* [Bloat] benefits of ack filtering @ 2017-11-28 21:48 Dave Taht 2017-11-29 6:09 ` Mikael Abrahamsson 2017-11-29 18:28 ` Juliusz Chroboczek 0 siblings, 2 replies; 76+ messages in thread From: Dave Taht @ 2017-11-28 21:48 UTC (permalink / raw) To: bloat Recently Ryan Mounce added ack filtering cabilities to the cake qdisc. The benefits were pretty impressive at a 50x1 Down/Up ratio: http://blog.cerowrt.org/post/ack_filtering/ And quite noticeable at 16x1 ratios as well. I'd rather like to have a compelling list of reasons why not to do this! And ways to do it better, if not. The relevant code is hovering at: https://github.com/dtaht/sch_cake/blob/cobalt/sch_cake.c#L902 -- Dave Täht CEO, TekLibre, LLC http://www.teklibre.com Tel: 1-669-226-2619 ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-11-28 21:48 [Bloat] benefits of ack filtering Dave Taht @ 2017-11-29 6:09 ` Mikael Abrahamsson 2017-11-29 9:34 ` Sebastian Moeller ` (2 more replies) 2017-11-29 18:28 ` Juliusz Chroboczek 1 sibling, 3 replies; 76+ messages in thread From: Mikael Abrahamsson @ 2017-11-29 6:09 UTC (permalink / raw) To: Dave Taht; +Cc: bloat On Tue, 28 Nov 2017, Dave Taht wrote: > Recently Ryan Mounce added ack filtering cabilities to the cake qdisc. > > The benefits were pretty impressive at a 50x1 Down/Up ratio: > > http://blog.cerowrt.org/post/ack_filtering/ > > And quite noticeable at 16x1 ratios as well. > > I'd rather like to have a compelling list of reasons why not to do > this! And ways to do it better, if not. The relevant code is hovering > at: > > https://github.com/dtaht/sch_cake/blob/cobalt/sch_cake.c#L902 Your post is already quite comprehensive when it comes to downsides. The better solution would of course be to have the TCP peeps change the way TCP works so that it sends fewer ACKs. I don't want middle boxes making "smart" decisions when the proper solution is for both end TCP speakers to do less work by sending fewer ACKs. In the TCP implementations I tcpdump regularily, it seems they send one ACK per 2 downstream packets. At 1 gigabit/s that's in the order of 35k pps of ACKs (100 megabyte/s divided by 1440 divided by 2). That's in my opinion completely ludicrous rate of ACKs for no good reason. I don't know what the formula should be, but it sounds like the ACK sending ratio should be influenced by how many in-flight ACKs there might be. Is there any reason to have more than 100 ACKs in flight at any given time? 500? 1000? My DOCSIS connection (inferred through observation) seems to run on 1ms upstream time slots, and my modem will delete contigous ACKs at 16 or 32 ACK intervals, ending up running at typically 1-2 ACKs per 1ms time slot. This cuts down the ACK rate when I do 250 megabit/s downloads from 5-8 megabit/s to 400 kilobit/s of used upstream bw. Since this ACK reduction is done on probably hundreds of millions of fixed-line subscriber lines today, what arguments do designers of TCP have to keep sending one ACK per 2 received TCP packets? -- Mikael Abrahamsson email: swmike@swm.pp.se ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-11-29 6:09 ` Mikael Abrahamsson @ 2017-11-29 9:34 ` Sebastian Moeller 2017-11-29 12:49 ` Mikael Abrahamsson 2017-11-29 18:21 ` Juliusz Chroboczek 2017-12-11 20:15 ` Benjamin Cronce 2 siblings, 1 reply; 76+ messages in thread From: Sebastian Moeller @ 2017-11-29 9:34 UTC (permalink / raw) To: Mikael Abrahamsson; +Cc: Dave Täht, bloat Well, ACK filtering/thinning is a simple trade-off: redundancy versus bandwidth. Since the RFCs say a receiver should acknoledge every second full MSS I think the decision whether to filter or not should be kept to the enduser and not some misguided middle boxes; if a DOCSIS ISP wants to secure precious upstream bandwidth they should at least re-synthesize the filtered ACKs after passing their upstream bottleneck IMHO. This is not reasonable network management in my irrelevant opinion unless actively opted-in by the user. Or put differently the real fix for DOCSIS ISPs is to simply not sell internet connections with asymmetries that make it impossible to saturate the link with TCP traffic without heroic measures like ack filtering. So I am all for cake learning to do that, but I am 100% against recommending using it unless one is "blessed" with a clue-less ISP that has problems calculating the maximal permissible Up/Down asymmetry for TCP... BTW, I believe older TCPs used the reception of an ACK and not the acknowledged byte increment for widening their send/congestion windows, ack filtering should make slow start behave more sluggish for such hosts. As far as I can tell linux recently learned to deal with this fact as GRO in essence will also make the receiver ACK more rarely (once every 2 super-packets), so linux I think now evaluates the number of acknoledged bytes. But I have no idea about windows or BSD tcp implementations. Best Regards > On Nov 29, 2017, at 07:09, Mikael Abrahamsson <swmike@swm.pp.se> wrote: > > On Tue, 28 Nov 2017, Dave Taht wrote: > >> Recently Ryan Mounce added ack filtering cabilities to the cake qdisc. >> >> The benefits were pretty impressive at a 50x1 Down/Up ratio: >> >> http://blog.cerowrt.org/post/ack_filtering/ >> >> And quite noticeable at 16x1 ratios as well. >> >> I'd rather like to have a compelling list of reasons why not to do >> this! And ways to do it better, if not. The relevant code is hovering >> at: >> >> https://github.com/dtaht/sch_cake/blob/cobalt/sch_cake.c#L902 > > Your post is already quite comprehensive when it comes to downsides. > > The better solution would of course be to have the TCP peeps change the way TCP works so that it sends fewer ACKs. I don't want middle boxes making "smart" decisions when the proper solution is for both end TCP speakers to do less work by sending fewer ACKs. In the TCP implementations I tcpdump regularily, it seems they send one ACK per 2 downstream packets. > > At 1 gigabit/s that's in the order of 35k pps of ACKs (100 megabyte/s divided by 1440 divided by 2). That's in my opinion completely ludicrous rate of ACKs for no good reason. > > I don't know what the formula should be, but it sounds like the ACK sending ratio should be influenced by how many in-flight ACKs there might be. Is there any reason to have more than 100 ACKs in flight at any given time? 500? 1000? > > My DOCSIS connection (inferred through observation) seems to run on 1ms upstream time slots, and my modem will delete contigous ACKs at 16 or 32 ACK intervals, ending up running at typically 1-2 ACKs per 1ms time slot. This cuts down the ACK rate when I do 250 megabit/s downloads from 5-8 megabit/s to 400 kilobit/s of used upstream bw. > > Since this ACK reduction is done on probably hundreds of millions of fixed-line subscriber lines today, what arguments do designers of TCP have to keep sending one ACK per 2 received TCP packets? > > -- > Mikael Abrahamsson email: swmike@swm.pp.se > _______________________________________________ > Bloat mailing list > Bloat@lists.bufferbloat.net > https://lists.bufferbloat.net/listinfo/bloat ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-11-29 9:34 ` Sebastian Moeller @ 2017-11-29 12:49 ` Mikael Abrahamsson 2017-11-29 13:13 ` Luca Muscariello 2017-11-29 16:50 ` Sebastian Moeller 0 siblings, 2 replies; 76+ messages in thread From: Mikael Abrahamsson @ 2017-11-29 12:49 UTC (permalink / raw) To: Sebastian Moeller; +Cc: Dave Täht, bloat On Wed, 29 Nov 2017, Sebastian Moeller wrote: > Well, ACK filtering/thinning is a simple trade-off: redundancy versus > bandwidth. Since the RFCs say a receiver should acknoledge every second > full MSS I think the decision whether to filter or not should be kept to Why does it say to do this? What benefit is there to either end system to send 35kPPS of ACKs in order to facilitate a 100 megabyte/s of TCP transfer? Sounds like a lot of useless interrupts and handling by the stack, apart from offloading it to the NIC to do a lot of handling of these mostly useless packets so the CPU doesn't have to do it. Why isn't 1kPPS of ACKs sufficient for most usecases? -- Mikael Abrahamsson email: swmike@swm.pp.se ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-11-29 12:49 ` Mikael Abrahamsson @ 2017-11-29 13:13 ` Luca Muscariello 2017-11-29 14:31 ` Mikael Abrahamsson 2017-11-29 16:50 ` Sebastian Moeller 1 sibling, 1 reply; 76+ messages in thread From: Luca Muscariello @ 2017-11-29 13:13 UTC (permalink / raw) To: Mikael Abrahamsson; +Cc: Sebastian Moeller, bloat [-- Attachment #1: Type: text/plain, Size: 1261 bytes --] Did you check RFC 3449 ? https://tools.ietf.org/html/rfc3449#section-5.2.1 It would be interesting to know what is the minimum ACK rate to achieve full utilisation. Or the how the downlink rate depends on the uplink ACK rate. I'm sure I've seen this dependency in some old paper. On Wed, Nov 29, 2017 at 1:49 PM, Mikael Abrahamsson <swmike@swm.pp.se> wrote: > On Wed, 29 Nov 2017, Sebastian Moeller wrote: > > Well, ACK filtering/thinning is a simple trade-off: redundancy versus >> bandwidth. Since the RFCs say a receiver should acknoledge every second >> full MSS I think the decision whether to filter or not should be kept to >> > > Why does it say to do this? What benefit is there to either end system to > send 35kPPS of ACKs in order to facilitate a 100 megabyte/s of TCP transfer? > > Sounds like a lot of useless interrupts and handling by the stack, apart > from offloading it to the NIC to do a lot of handling of these mostly > useless packets so the CPU doesn't have to do it. > > Why isn't 1kPPS of ACKs sufficient for most usecases? > > > -- > Mikael Abrahamsson email: swmike@swm.pp.se > _______________________________________________ > Bloat mailing list > Bloat@lists.bufferbloat.net > https://lists.bufferbloat.net/listinfo/bloat > [-- Attachment #2: Type: text/html, Size: 2153 bytes --] ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-11-29 13:13 ` Luca Muscariello @ 2017-11-29 14:31 ` Mikael Abrahamsson 2017-11-29 14:36 ` Jonathan Morton 2017-11-29 15:53 ` Luca Muscariello 0 siblings, 2 replies; 76+ messages in thread From: Mikael Abrahamsson @ 2017-11-29 14:31 UTC (permalink / raw) To: Luca Muscariello; +Cc: Sebastian Moeller, bloat On Wed, 29 Nov 2017, Luca Muscariello wrote: >> Why does it say to do this? What benefit is there to either end system to >> send 35kPPS of ACKs in order to facilitate a 100 megabyte/s of TCP transfer? > > Did you check RFC 3449 ? > https://tools.ietf.org/html/rfc3449#section-5.2.1 RFC3449 is all about middleboxes doing things. I wanted to understand why TCP implementations find it necessary to send one ACK per 2xMSS at really high PPS. Especially when NIC offloads and middleboxes frequently strip out this information anyway so it never reaches the IP stack (right?). -- Mikael Abrahamsson email: swmike@swm.pp.se ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-11-29 14:31 ` Mikael Abrahamsson @ 2017-11-29 14:36 ` Jonathan Morton 2017-11-29 15:24 ` Andrés Arcia-Moret 2017-11-29 15:53 ` Luca Muscariello 1 sibling, 1 reply; 76+ messages in thread From: Jonathan Morton @ 2017-11-29 14:36 UTC (permalink / raw) To: Mikael Abrahamsson; +Cc: Luca Muscariello, bloat [-- Attachment #1: Type: text/plain, Size: 140 bytes --] There is an RFC about emitting fewer acks in response to upstream congestion or some other cue; AckCC might be the name. - Jonathan Morton [-- Attachment #2: Type: text/html, Size: 179 bytes --] ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-11-29 14:36 ` Jonathan Morton @ 2017-11-29 15:24 ` Andrés Arcia-Moret 0 siblings, 0 replies; 76+ messages in thread From: Andrés Arcia-Moret @ 2017-11-29 15:24 UTC (permalink / raw) To: Jonathan Morton; +Cc: Mikael Abrahamsson, bloat [-- Attachment #1: Type: text/plain, Size: 594 bytes --] RFC 5690 and http://www.saber.ula.ve/bitstream/123456789/30345/1/thesis-francais-english.pdf <http://www.saber.ula.ve/bitstream/123456789/30345/1/thesis-francais-english.pdf> Ch 4 and 5 regards a. > On 29 Nov 2017, at 14:36, Jonathan Morton <chromatix99@gmail.com> wrote: > > There is an RFC about emitting fewer acks in response to upstream congestion or some other cue; AckCC might be the name. > > - Jonathan Morton > _______________________________________________ > Bloat mailing list > Bloat@lists.bufferbloat.net > https://lists.bufferbloat.net/listinfo/bloat [-- Attachment #2: Type: text/html, Size: 1313 bytes --] ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-11-29 14:31 ` Mikael Abrahamsson 2017-11-29 14:36 ` Jonathan Morton @ 2017-11-29 15:53 ` Luca Muscariello [not found] ` <CAJq5cE3qsmy8EFYZmQsLL_frm8Tty9Gkm92MQPZ649+kpM1oMw@mail.gmail.com> 2017-11-30 7:03 ` Michael Welzl 1 sibling, 2 replies; 76+ messages in thread From: Luca Muscariello @ 2017-11-29 15:53 UTC (permalink / raw) To: Mikael Abrahamsson; +Cc: Sebastian Moeller, bloat [-- Attachment #1: Type: text/plain, Size: 1129 bytes --] On Wed, Nov 29, 2017 at 3:31 PM, Mikael Abrahamsson <swmike@swm.pp.se> wrote: > On Wed, 29 Nov 2017, Luca Muscariello wrote: > > Why does it say to do this? What benefit is there to either end system to >>> send 35kPPS of ACKs in order to facilitate a 100 megabyte/s of TCP >>> transfer? >>> >> >> Did you check RFC 3449 ? >> https://tools.ietf.org/html/rfc3449#section-5.2.1 >> > > RFC3449 is all about middleboxes doing things. > > I wanted to understand why TCP implementations find it necessary to send > one ACK per 2xMSS at really high PPS. Especially when NIC offloads and > middleboxes frequently strip out this information anyway so it never > reaches the IP stack (right?). > > I would say because it is complex to guess at which PPS to work. You would need an adaptation mechanism. Need also to change the client and the server sides. The AckCC Jonathan has mentioned might be a solution to that. Probably an ACK pacer in the end host, out of the TCP stack, doing Ack filtering and decimation can be simpler to implement than the proper adaptation mechanism in TCP. Maybe inside sch_fq it would be doable. Maybe not. [-- Attachment #2: Type: text/html, Size: 1968 bytes --] ^ permalink raw reply [flat|nested] 76+ messages in thread
[parent not found: <CAJq5cE3qsmy8EFYZmQsLL_frm8Tty9Gkm92MQPZ649+kpM1oMw@mail.gmail.com>]
* Re: [Bloat] benefits of ack filtering [not found] ` <CAJq5cE3qsmy8EFYZmQsLL_frm8Tty9Gkm92MQPZ649+kpM1oMw@mail.gmail.com> @ 2017-11-29 16:13 ` Jonathan Morton 0 siblings, 0 replies; 76+ messages in thread From: Jonathan Morton @ 2017-11-29 16:13 UTC (permalink / raw) To: Luca Muscariello; +Cc: Mikael Abrahamsson, bloat [-- Attachment #1: Type: text/plain, Size: 307 bytes --] Given an RTT estimate and knowledge of the congestion window, the AckCC option could be used to target a handful of acks (maybe 4 to 10) per RTT. As usual, extra acks would be sent when loss is suspected, on ECN events, and when the push flag is set. That would be perfectly sufficient. - Jonathan Morton [-- Attachment #2: Type: text/html, Size: 368 bytes --] ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-11-29 15:53 ` Luca Muscariello [not found] ` <CAJq5cE3qsmy8EFYZmQsLL_frm8Tty9Gkm92MQPZ649+kpM1oMw@mail.gmail.com> @ 2017-11-30 7:03 ` Michael Welzl 2017-11-30 7:24 ` Dave Taht ` (2 more replies) 1 sibling, 3 replies; 76+ messages in thread From: Michael Welzl @ 2017-11-30 7:03 UTC (permalink / raw) To: bloat; +Cc: David Ros [-- Attachment #1: Type: text/plain, Size: 5878 bytes --] Hi Bloaters, I’d like to give offer some information and thoughts on AckCC, at the bottom of this email. > On Nov 29, 2017, at 4:53 PM, Luca Muscariello <luca.muscariello@gmail.com> wrote: > > > > On Wed, Nov 29, 2017 at 3:31 PM, Mikael Abrahamsson <swmike@swm.pp.se <mailto:swmike@swm.pp.se>> wrote: > On Wed, 29 Nov 2017, Luca Muscariello wrote: > > Why does it say to do this? What benefit is there to either end system to > send 35kPPS of ACKs in order to facilitate a 100 megabyte/s of TCP transfer? > > Did you check RFC 3449 ? > https://tools.ietf.org/html/rfc3449#section-5.2.1 <https://tools.ietf.org/html/rfc3449#section-5.2.1> > > RFC3449 is all about middleboxes doing things. > > I wanted to understand why TCP implementations find it necessary to send one ACK per 2xMSS at really high PPS. Especially when NIC offloads and middleboxes frequently strip out this information anyway so it never reaches the IP stack (right?). > > > I would say because it is complex to guess at which PPS to work. You would need an adaptation mechanism. Need also to change the client and the server sides. The AckCC Jonathan has mentioned > might be a solution to that. > Probably an ACK pacer in the end host, out of the TCP stack, doing Ack filtering and decimation can be simpler to implement than the proper adaptation mechanism in TCP. > Maybe inside sch_fq it would be doable. Maybe not. I’m adding the response from Jonathan Morton here to make this more self-contained: *** Given an RTT estimate and knowledge of the congestion window, the AckCC option could be used to target a handful of acks (maybe 4 to 10) per RTT. As usual, extra acks would be sent when loss is suspected, on ECN events, and when the push flag is set. That would be perfectly sufficient. - Jonathan Morton *** A few years ago, David Ros, whom I’m adding in cc, one of the original authors of RFC 5690 did a sabbatical with me at the University of Oslo. As part of that, we advised a master student to carry out tests with AckCC, and analyze the RFC to understand how it would have to change if we were to proceed to Proposed Standard. The result of his investigation is here: http://heim.ifi.uio.no/michawe/teaching/dipls/marius-olsen/mastersthesis-mariusno.pdf <http://heim.ifi.uio.no/michawe/teaching/dipls/marius-olsen/mastersthesis-mariusno.pdf> and his code is here: http://folk.uio.no/mariusno/master/ <http://folk.uio.no/mariusno/master/> Now, after finishing the thesis, when it came to writing a paper about it, we got stuck in the discussion of “how are we going to explain that this is really necessary?” - we didn’t want to submit a “solution searching for a problem” paper and didn’t want to get rejected for not having shown that the problem truly exists. Searching for this a little in the academic world (papers) gave us no result, at least back then. Interestingly, at IETF 98, not so long ago, Ingemar Johansson explained to folks at TSVWG that the problem IS real: https://datatracker.ietf.org/meeting/98/materials/slides-98-tsvwg-sessb-7-transport-protocol-feedback-overhead-issues-and-solutions/ <https://datatracker.ietf.org/meeting/98/materials/slides-98-tsvwg-sessb-7-transport-protocol-feedback-overhead-issues-and-solutions/> So, let me now try to answer “why is TCP not doing that?”. - First, AFAIK, AckCC isn’t implemented anywhere (except that we have this old patch - please feel free to download, adapt, and play with it !!) - Second, if someone was to update TCP to support this, a bit more than simple statements about the amount of traffic being large would be good IMO - I mean, some convincing proof that the large number of ACKs *really* is a problem. - Third, once this is implemented and deployed and found to be beneficial, it would be useful to follow up in the IETF and update RFC 5690. Since nobody seems to be doing any of these things, nothing changes. But consider this: I see folks from Google doing a lot of TCP updates in the IETF for which they themselves appear to have an immediate need. Given the heterogeneity and magnitude of traffic produced by Google, if they don’t see a pressing need for it, I suspect that, indeed, the problem might not be so real after all?! Also, a word of caution. In this thread, there seems to be general agreement that TCP sends way too many ACKs, and that reducing that number would be fantastic. I’m not so convinced. Okay, even if TCP isn’t that ACK-clocked anymore in Linux: 1) there isn’t only Linux in this world, 2) ACKs are still quite important in Fast Recovery, 3) BBR might not need to clock out ACKs, but it measures their incoming rate. For another example, consider a non-BBR sender in slow start: without ABC, missing ACKs would let it grow its cwnd too cautiously. Thanks to ABC, this can be done more aggressively - but ABC recommends a limit on how quickly to “jump” in the rate in response to a single ACK, for good reason - to avoid producing even heavier bursts. But with this limit, again, the TCP sender is unnecessarily cautious in Slow Start just because it misses ACKs. My point is: the ACKs ARE the feedback that TCP works on; when you take them away, TCP becomes “blind”, and whatever improvement is made to TCP will have to be developed on that basis. I’m not saying that 1 ACK for every two packets is really necessary… but unless there’s hard proof that this really is a problem, I’d caution against a “downward spiral” here: the level of asymmetry offered to users today is probably somehow related to the commonly seen TCP ACK rate - so if TCP starts to reduce the ACK rate, folks may decide to make links even more asymmetric, etc. etc. … I’m not sure this is a good direction. Just some thoughts, and some context. Cheers, Michael [-- Attachment #2: Type: text/html, Size: 8231 bytes --] ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-11-30 7:03 ` Michael Welzl @ 2017-11-30 7:24 ` Dave Taht 2017-11-30 7:45 ` Dave Taht 2017-11-30 7:48 ` Jonathan Morton 2 siblings, 0 replies; 76+ messages in thread From: Dave Taht @ 2017-11-30 7:24 UTC (permalink / raw) To: Michael Welzl; +Cc: bloat, David Ros On Wed, Nov 29, 2017 at 11:03 PM, Michael Welzl <michawe@ifi.uio.no> wrote: > Hi Bloaters, > > I’d like to give offer some information and thoughts on AckCC, at the bottom > of this email. > > > On Nov 29, 2017, at 4:53 PM, Luca Muscariello <luca.muscariello@gmail.com> > wrote: > > > > On Wed, Nov 29, 2017 at 3:31 PM, Mikael Abrahamsson <swmike@swm.pp.se> > wrote: >> >> On Wed, 29 Nov 2017, Luca Muscariello wrote: >> >>>> Why does it say to do this? What benefit is there to either end system >>>> to >>>> send 35kPPS of ACKs in order to facilitate a 100 megabyte/s of TCP >>>> transfer? >>> >>> >>> Did you check RFC 3449 ? >>> https://tools.ietf.org/html/rfc3449#section-5.2.1 >> >> >> RFC3449 is all about middleboxes doing things. >> >> I wanted to understand why TCP implementations find it necessary to send >> one ACK per 2xMSS at really high PPS. Especially when NIC offloads and >> middleboxes frequently strip out this information anyway so it never reaches >> the IP stack (right?). >> > > I would say because it is complex to guess at which PPS to work. You would > need an adaptation mechanism. Need also to change the client and the server > sides. The AckCC Jonathan has mentioned > might be a solution to that. > Probably an ACK pacer in the end host, out of the TCP stack, doing Ack > filtering and decimation can be simpler to implement than the proper > adaptation mechanism in TCP. > Maybe inside sch_fq it would be doable. Maybe not. > > > I’m adding the response from Jonathan Morton here to make this more > self-contained: > *** > Given an RTT estimate and knowledge of the congestion window, the AckCC > option could be used to target a handful of acks (maybe 4 to 10) per RTT. > As usual, extra acks would be sent when loss is suspected, on ECN events, > and when the push flag is set. > > That would be perfectly sufficient. > > - Jonathan Morton > > *** > > A few years ago, David Ros, whom I’m adding in cc, one of the original > authors of RFC 5690 did a sabbatical with me at the University of Oslo. As > part of that, we advised a master student to carry out tests with AckCC, and > analyze the RFC to understand how it would have to change if we were to > proceed to Proposed Standard. The result of his investigation is here: > http://heim.ifi.uio.no/michawe/teaching/dipls/marius-olsen/mastersthesis-mariusno.pdf > and his code is here: http://folk.uio.no/mariusno/master/ > > Now, after finishing the thesis, when it came to writing a paper about it, > we got stuck in the discussion of “how are we going to explain that this is > really necessary?” > - we didn’t want to submit a “solution searching for a problem” paper and > didn’t want to get rejected for not having shown that the problem truly > exists. Searching for this a little in the academic world (papers) gave us > no result, at least back then. > > Interestingly, at IETF 98, not so long ago, Ingemar Johansson explained to > folks at TSVWG that the problem IS real: > https://datatracker.ietf.org/meeting/98/materials/slides-98-tsvwg-sessb-7-transport-protocol-feedback-overhead-issues-and-solutions/ > > So, let me now try to answer “why is TCP not doing that?”. > - First, AFAIK, AckCC isn’t implemented anywhere (except that we have this > old patch - please feel free to download, adapt, and play with it !!) > - Second, if someone was to update TCP to support this, a bit more than > simple statements about the amount of traffic being large would be good IMO > - I mean, some convincing proof that the large number of ACKs *really* is a > problem. > - Third, once this is implemented and deployed and found to be beneficial, > it would be useful to follow up in the IETF and update RFC 5690. > > Since nobody seems to be doing any of these things, nothing changes. But > consider this: I see folks from Google doing a lot of TCP updates in the > IETF for which they themselves appear to have an immediate need. Given the > heterogeneity and magnitude of traffic produced by Google, if they don’t see > a pressing need for it, I suspect that, indeed, the problem might not be so > real after all?! > > Also, a word of caution. In this thread, there seems to be general agreement > that TCP sends way too many ACKs, and that reducing that number would be > fantastic. > I’m not so convinced. Okay, even if TCP isn’t that ACK-clocked anymore in > Linux: 1) there isn’t only Linux in this world, 2) ACKs are still quite > important in Fast Recovery, 3) BBR might not need to clock out ACKs, but it > measures their incoming rate. For another example, consider a non-BBR > sender in slow start: without ABC, missing ACKs would let it grow its cwnd > too cautiously. Thanks to ABC, this can be done more aggressively - but ABC > recommends a limit on how quickly to “jump” in the rate in response to a > single ACK, for good reason - to avoid producing even heavier bursts. But > with this limit, again, the TCP sender is unnecessarily cautious in Slow > Start just because it misses ACKs. My answer to questions like this that are difficult reason about... is to run the experiment. Trying out BBR in the testbeds we have setup would be straightforward, although rrul_be (which is what we have the MOS results for) is not the best test for BBR's behaviors. Maybe more of a staircase test would be better. (note we're also looking at sfq and pfifo as references) > My point is: the ACKs ARE the feedback that TCP works on; when you take them > away, TCP becomes “blind”, and whatever improvement is made to TCP will have > to be developed on that basis. > > I’m not saying that 1 ACK for every two packets is really necessary… but > unless there’s hard proof that this really is a problem, I’d caution against > a “downward spiral” here: the level of asymmetry offered to users today is > probably somehow related to the commonly seen TCP ACK rate - so if TCP > starts to reduce the ACK rate, folks may decide to make links even more > asymmetric, etc. etc. … I’m not sure this is a good direction. > > Just some thoughts, and some context. > > Cheers, > Michael > > > _______________________________________________ > Bloat mailing list > Bloat@lists.bufferbloat.net > https://lists.bufferbloat.net/listinfo/bloat > -- Dave Täht CEO, TekLibre, LLC http://www.teklibre.com Tel: 1-669-226-2619 ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-11-30 7:03 ` Michael Welzl 2017-11-30 7:24 ` Dave Taht @ 2017-11-30 7:45 ` Dave Taht 2017-11-30 7:48 ` Jonathan Morton 2 siblings, 0 replies; 76+ messages in thread From: Dave Taht @ 2017-11-30 7:45 UTC (permalink / raw) To: Michael Welzl; +Cc: bloat, David Ros On Wed, Nov 29, 2017 at 11:03 PM, Michael Welzl <michawe@ifi.uio.no> wrote: > Hi Bloaters, > > I’d like to give offer some information and thoughts on AckCC, at the bottom > of this email. > > > On Nov 29, 2017, at 4:53 PM, Luca Muscariello <luca.muscariello@gmail.com> > wrote: > > > > On Wed, Nov 29, 2017 at 3:31 PM, Mikael Abrahamsson <swmike@swm.pp.se> > wrote: >> >> On Wed, 29 Nov 2017, Luca Muscariello wrote: >> >>>> Why does it say to do this? What benefit is there to either end system >>>> to >>>> send 35kPPS of ACKs in order to facilitate a 100 megabyte/s of TCP >>>> transfer? >>> >>> >>> Did you check RFC 3449 ? >>> https://tools.ietf.org/html/rfc3449#section-5.2.1 >> >> >> RFC3449 is all about middleboxes doing things. >> >> I wanted to understand why TCP implementations find it necessary to send >> one ACK per 2xMSS at really high PPS. Especially when NIC offloads and >> middleboxes frequently strip out this information anyway so it never reaches >> the IP stack (right?). >> > > I would say because it is complex to guess at which PPS to work. You would > need an adaptation mechanism. Need also to change the client and the server > sides. The AckCC Jonathan has mentioned > might be a solution to that. > Probably an ACK pacer in the end host, out of the TCP stack, doing Ack > filtering and decimation can be simpler to implement than the proper > adaptation mechanism in TCP. > Maybe inside sch_fq it would be doable. Maybe not. > > > I’m adding the response from Jonathan Morton here to make this more > self-contained: > *** > Given an RTT estimate and knowledge of the congestion window, the AckCC > option could be used to target a handful of acks (maybe 4 to 10) per RTT. > As usual, extra acks would be sent when loss is suspected, on ECN events, > and when the push flag is set. > > That would be perfectly sufficient. > > - Jonathan Morton > > *** > > A few years ago, David Ros, whom I’m adding in cc, one of the original > authors of RFC 5690 did a sabbatical with me at the University of Oslo. As > part of that, we advised a master student to carry out tests with AckCC, and > analyze the RFC to understand how it would have to change if we were to > proceed to Proposed Standard. The result of his investigation is here: > http://heim.ifi.uio.no/michawe/teaching/dipls/marius-olsen/mastersthesis-mariusno.pdf > and his code is here: http://folk.uio.no/mariusno/master/ > > Now, after finishing the thesis, when it came to writing a paper about it, > we got stuck in the discussion of “how are we going to explain that this is > really necessary?” > - we didn’t want to submit a “solution searching for a problem” paper and > didn’t want to get rejected for not having shown that the problem truly > exists. Searching for this a little in the academic world (papers) gave us > no result, at least back then. > > Interestingly, at IETF 98, not so long ago, Ingemar Johansson explained to > folks at TSVWG that the problem IS real: > https://datatracker.ietf.org/meeting/98/materials/slides-98-tsvwg-sessb-7-transport-protocol-feedback-overhead-issues-and-solutions/ > > So, let me now try to answer “why is TCP not doing that?”. > - First, AFAIK, AckCC isn’t implemented anywhere (except that we have this > old patch - please feel free to download, adapt, and play with it !!) > - Second, if someone was to update TCP to support this, a bit more than > simple statements about the amount of traffic being large would be good IMO > - I mean, some convincing proof that the large number of ACKs *really* is a > problem. > - Third, once this is implemented and deployed and found to be beneficial, > it would be useful to follow up in the IETF and update RFC 5690. > > Since nobody seems to be doing any of these things, nothing changes. But > consider this: I see folks from Google doing a lot of TCP updates in the > IETF for which they themselves appear to have an immediate need. Given the > heterogeneity and magnitude of traffic produced by Google, if they don’t see > a pressing need for it, I suspect that, indeed, the problem might not be so > real after all?! > > Also, a word of caution. In this thread, there seems to be general agreement > that TCP sends way too many ACKs, and that reducing that number would be > fantastic. > I’m not so convinced. Okay, even if TCP isn’t that ACK-clocked anymore in > Linux: 1) there isn’t only Linux in this world, Nor one Linux. >2) ACKs are still quite > important in Fast Recovery, If you are already achieving twice the rate, what does occasionally losing fast recovery cost? >3) BBR might not need to clock out ACKs, but it > measures their incoming rate. if it collapses to a punctuated paced source, it could also notice acks being lost, and extrapolate. > For another example, consider a non-BBR > sender in slow start: without ABC, missing ACKs would let it grow its cwnd > too cautiously. Thanks to ABC, this can be done more aggressively - but ABC > recommends a limit on how quickly to “jump” in the rate in response to a > single ACK, for good reason - to avoid producing even heavier bursts. But > with this limit, again, the TCP sender is unnecessarily cautious in Slow > Start just because it misses ACKs. I'm not a huge fan of slow start in IW10. And: Strike "unnecessarily is", and substitute "may not be", as http://blog.cerowrt.org/flent/ack_filter/1Gbit-20Mbit-rrul_be.png seems to show. The ack-filter result shows one flow growing rapidly, and three others not. > My point is: the ACKs ARE the feedback that TCP works on; when you take them > away, TCP becomes “blind”, and whatever improvement is made to TCP will have > to be developed on that basis. > > I’m not saying that 1 ACK for every two packets is really necessary… but > unless there’s hard proof that this really is a problem, I’d caution against > a “downward spiral” here: the level of asymmetry offered to users today is > probably somehow related to the commonly seen TCP ACK rate - so if TCP > starts to reduce the ACK rate, folks may decide to make links even more > asymmetric, etc. etc. … I’m not sure this is a good direction. > > Just some thoughts, and some context. > > Cheers, > Michael > > > _______________________________________________ > Bloat mailing list > Bloat@lists.bufferbloat.net > https://lists.bufferbloat.net/listinfo/bloat > -- Dave Täht CEO, TekLibre, LLC http://www.teklibre.com Tel: 1-669-226-2619 ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-11-30 7:03 ` Michael Welzl 2017-11-30 7:24 ` Dave Taht 2017-11-30 7:45 ` Dave Taht @ 2017-11-30 7:48 ` Jonathan Morton 2017-11-30 8:00 ` Luca Muscariello 2017-11-30 10:24 ` Eric Dumazet 2 siblings, 2 replies; 76+ messages in thread From: Jonathan Morton @ 2017-11-30 7:48 UTC (permalink / raw) To: Michael Welzl; +Cc: bloat, David Ros [-- Attachment #1: Type: text/plain, Size: 1823 bytes --] I do see your arguments. Let it be known that I didn't initiate the ack-filter in Cake, though it does seem to work quite well. With respect to BBR, I don't think it depends strongly on the return rate of acks in themselves, but rather on the rate of sequence number advance that they indicate. For this purpose, having the receiver emit sparser but still regularly spaced acks would be better than having some middlebox delete some less-predictable subset of them. So I think BBR could be a good testbed for AckCC implementation, especially as it is inherently paced and thus doesn't suffer from burstiness as a conventional ack-clocked TCP might. The real trouble with AckCC is that it requires implementation on the client as well as the server. That's most likely why Google hasn't tried it yet; there are no receivers in the wild that would give them valid data on its effectiveness. Adding support in Linux would help here, but aside from Android devices, Linux is only a relatively small proportion of Google's client traffic - and Android devices are slow to pick up new kernel features if they can't immediately turn it into a consumer-friendly bullet point. Meanwhile we have highly asymmetric last-mile links (10:1 is typical, 50:1 is occasionally seen), where a large fraction of upload bandwidth is occupied by acks in order to fully utilise the download bandwidth in TCP. Any concurrent upload flows have to compete with that dense ack flow, which in various schemes is unfair to either the upload or the download throughput. That is a problem as soon as you have multiple users on the same link, eg. a family household at the weekend. Thinning out those acks in response to uplink congestion is a solution. Maybe not the best possible solution, but a deployable one that works. - Jonathan Morton [-- Attachment #2: Type: text/html, Size: 1970 bytes --] ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-11-30 7:48 ` Jonathan Morton @ 2017-11-30 8:00 ` Luca Muscariello 2017-11-30 10:24 ` Eric Dumazet 1 sibling, 0 replies; 76+ messages in thread From: Luca Muscariello @ 2017-11-30 8:00 UTC (permalink / raw) To: Jonathan Morton; +Cc: Michael Welzl, David Ros, bloat [-- Attachment #1: Type: text/plain, Size: 2337 bytes --] Agree and think this is a lucid analysis of the problem(s) and solution(s). But, what can be done to let clients upgrade orders of magnitude faster than today? Move transport in user space inside the app? Else? On Thu, Nov 30, 2017 at 8:48 AM, Jonathan Morton <chromatix99@gmail.com> wrote: > I do see your arguments. Let it be known that I didn't initiate the > ack-filter in Cake, though it does seem to work quite well. > > With respect to BBR, I don't think it depends strongly on the return rate > of acks in themselves, but rather on the rate of sequence number advance > that they indicate. For this purpose, having the receiver emit sparser but > still regularly spaced acks would be better than having some middlebox > delete some less-predictable subset of them. So I think BBR could be a > good testbed for AckCC implementation, especially as it is inherently paced > and thus doesn't suffer from burstiness as a conventional ack-clocked TCP > might. > > The real trouble with AckCC is that it requires implementation on the > client as well as the server. That's most likely why Google hasn't tried > it yet; there are no receivers in the wild that would give them valid data > on its effectiveness. Adding support in Linux would help here, but aside > from Android devices, Linux is only a relatively small proportion of > Google's client traffic - and Android devices are slow to pick up new > kernel features if they can't immediately turn it into a consumer-friendly > bullet point. > > Meanwhile we have highly asymmetric last-mile links (10:1 is typical, 50:1 > is occasionally seen), where a large fraction of upload bandwidth is > occupied by acks in order to fully utilise the download bandwidth in TCP. > Any concurrent upload flows have to compete with that dense ack flow, which > in various schemes is unfair to either the upload or the download > throughput. > > That is a problem as soon as you have multiple users on the same link, eg. > a family household at the weekend. Thinning out those acks in response to > uplink congestion is a solution. Maybe not the best possible solution, but > a deployable one that works. > > - Jonathan Morton > > _______________________________________________ > Bloat mailing list > Bloat@lists.bufferbloat.net > https://lists.bufferbloat.net/listinfo/bloat > > [-- Attachment #2: Type: text/html, Size: 3015 bytes --] ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-11-30 7:48 ` Jonathan Morton 2017-11-30 8:00 ` Luca Muscariello @ 2017-11-30 10:24 ` Eric Dumazet 2017-11-30 13:04 ` Mikael Abrahamsson 2017-11-30 14:51 ` Neal Cardwell 1 sibling, 2 replies; 76+ messages in thread From: Eric Dumazet @ 2017-11-30 10:24 UTC (permalink / raw) To: Jonathan Morton, Michael Welzl; +Cc: David Ros, bloat I agree that TCP itself should generate ACK smarter, on receivers that are lacking GRO. (TCP sends at most one ACK per GRO packets, that is why we did not feel an urgent need for better ACK generation) It is actually difficult task, because it might need an additional timer, and we were reluctant adding extra complexity for that. An additional point where huge gains are possible is to add TSO autodefer while in recovery. Lacking TSO auto defer explains why TCP flows enter a degenerated behavior, re-sending 1-MSS packets in response to SACK flood. On Thu, 2017-11-30 at 09:48 +0200, Jonathan Morton wrote: > I do see your arguments. Let it be known that I didn't initiate the > ack-filter in Cake, though it does seem to work quite well. > With respect to BBR, I don't think it depends strongly on the return > rate of acks in themselves, but rather on the rate of sequence number > advance that they indicate. For this purpose, having the receiver > emit sparser but still regularly spaced acks would be better than > having some middlebox delete some less-predictable subset of them. > So I think BBR could be a good testbed for AckCC implementation, > especially as it is inherently paced and thus doesn't suffer from > burstiness as a conventional ack-clocked TCP might. > The real trouble with AckCC is that it requires implementation on the > client as well as the server. That's most likely why Google hasn't > tried it yet; there are no receivers in the wild that would give them > valid data on its effectiveness. Adding support in Linux would help > here, but aside from Android devices, Linux is only a relatively > small proportion of Google's client traffic - and Android devices are > slow to pick up new kernel features if they can't immediately turn it > into a consumer-friendly bullet point. > Meanwhile we have highly asymmetric last-mile links (10:1 is typical, > 50:1 is occasionally seen), where a large fraction of upload > bandwidth is occupied by acks in order to fully utilise the download > bandwidth in TCP. Any concurrent upload flows have to compete with > that dense ack flow, which in various schemes is unfair to either the > upload or the download throughput. > That is a problem as soon as you have multiple users on the same > link, eg. a family household at the weekend. Thinning out those acks > in response to uplink congestion is a solution. Maybe not the best > possible solution, but a deployable one that works. > - Jonathan Morton > _______________________________________________ > Bloat mailing list > Bloat@lists.bufferbloat.net > https://lists.bufferbloat.net/listinfo/bloat ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-11-30 10:24 ` Eric Dumazet @ 2017-11-30 13:04 ` Mikael Abrahamsson 2017-11-30 15:51 ` Eric Dumazet 2017-12-01 0:28 ` David Lang 2017-11-30 14:51 ` Neal Cardwell 1 sibling, 2 replies; 76+ messages in thread From: Mikael Abrahamsson @ 2017-11-30 13:04 UTC (permalink / raw) To: Eric Dumazet; +Cc: bloat On Thu, 30 Nov 2017, Eric Dumazet wrote: > I agree that TCP itself should generate ACK smarter, on receivers that > are lacking GRO. (TCP sends at most one ACK per GRO packets, that is why > we did not feel an urgent need for better ACK generation) Could you elaborate a bit more on the practical implications of the above text? What is the typical GRO size used when doing gigabit ethernet transmissions? So if we're receiving 70kPPS of 1500 byte packets containing 1460 MSS sized packet (~100 megabyte/s), what would a typical ACK rate be in that case? In response to some other postings here, my question regarding "is 35kPPS really needed" my proposal is not "let's send 50 PPS of ACKs". My proposal is if we can't come up with a smarter algorithm than something from the 90ties that says "let's send one ACK per 2*MSS" when we today have magnitudes higher rates of forwarding. Also, on for instance DOCSIS networks then you're going to get several ACKs back-to-back anyway (because if they're not pruned by the DOCSIS network, they're anyway sent in "bursts" within a single DOCSIS transmit opportunity), so imagining that 35kPPS gives you higher resolution than 1kPPS of ACKs is just an illusion. So if GRO results in (I'm just speculating here) "we're only sending one ACK per X kilobytes received if the packets arrived in the same millisecond" and X is in the 16-64 kilobyte range, then that's fine by me. Any network worth anything should be able to smooth out "bursts" of 16-64 kilobytes at line rate anyway, in case of egress and the line rate there is lower than the sending end is transmitting packets at. -- Mikael Abrahamsson email: swmike@swm.pp.se ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-11-30 13:04 ` Mikael Abrahamsson @ 2017-11-30 15:51 ` Eric Dumazet 2017-12-01 0:28 ` David Lang 1 sibling, 0 replies; 76+ messages in thread From: Eric Dumazet @ 2017-11-30 15:51 UTC (permalink / raw) To: Mikael Abrahamsson; +Cc: bloat On Thu, 2017-11-30 at 14:04 +0100, Mikael Abrahamsson wrote: > On Thu, 30 Nov 2017, Eric Dumazet wrote: > > > I agree that TCP itself should generate ACK smarter, on receivers > > that > > are lacking GRO. (TCP sends at most one ACK per GRO packets, that > > is why > > we did not feel an urgent need for better ACK generation) > > Could you elaborate a bit more on the practical implications of the > above > text? What is the typical GRO size used when doing gigabit ethernet > transmissions? Assuming NAPI handler receives a big packet train in one go [1], GRO packets can be full size (45 MSS -> 65160 bytes of payload assuming 1448 bytes per frame) [1] GRO engine has an opt-in high res timer helping to extend NAPI poll if desired. https://git.kernel.org/pub/scm/linux/kernel/git/davem/net-n ext.git/commit/?id=3b47d30396bae4f0bd1ff0dbcd7c4f5077e7df4e > > So if we're receiving 70kPPS of 1500 byte packets containing 1460 > MSS > sized packet (~100 megabyte/s), what would a typical ACK rate be in > that > case? 1) Assuming receiver handles GRO. 2) Assuming few PSH flag set on incoming frames. 3) A default GRO engine on a 10Gbit NIC would probably not aggregate packets, since 14 usec delay between each packet is too big to let NAPI handler catch more than 1 packet per NIC RX interrupt. But setting /sys/class/net/ethX/gro_flush_timeout to 14000 would allow to build full size GRO packets (45 MSS) -> TCP receiver would then send 1555 ACK per second instead of 70,000 > > In response to some other postings here, my question regarding "is > 35kPPS > really needed" my proposal is not "let's send 50 PPS of ACKs". My > proposal > is if we can't come up with a smarter algorithm than something from > the > 90ties that says "let's send one ACK per 2*MSS" when we today have > magnitudes higher rates of forwarding. Also, on for instance DOCSIS > networks then you're going to get several ACKs back-to-back anyway > (because if they're not pruned by the DOCSIS network, they're anyway > sent > in "bursts" within a single DOCSIS transmit opportunity), so > imagining > that 35kPPS gives you higher resolution than 1kPPS of ACKs is just > an > illusion. > > So if GRO results in (I'm just speculating here) "we're only sending > one > ACK per X kilobytes received if the packets arrived in the same > millisecond" and X is in the 16-64 kilobyte range, then that's fine > by me. > > Any network worth anything should be able to smooth out "bursts" of > 16-64 > kilobytes at line rate anyway, in case of egress and the line rate > there > is lower than the sending end is transmitting packets at. > ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-11-30 13:04 ` Mikael Abrahamsson 2017-11-30 15:51 ` Eric Dumazet @ 2017-12-01 0:28 ` David Lang 2017-12-01 7:09 ` Jan Ceuleers 2017-12-01 8:45 ` [Bloat] " Sebastian Moeller 1 sibling, 2 replies; 76+ messages in thread From: David Lang @ 2017-12-01 0:28 UTC (permalink / raw) To: Mikael Abrahamsson; +Cc: Eric Dumazet, bloat 35K PPS of acks is insane, one ack every ms is FAR more than enough to do 'fast recovery', and outside the datacenter, one ack per 10ms is probably more than enough. Assuming something that's not too assymetric, thinning out the acks may not make any difference in the transfer rate of a single data flow in one direction, but if you step back and realize that there may be a need to transfer data in the other direction, things change here. If you have a fully symmetrical link, and are maxing it out in both direction, going from 35K PPs of aks competing with data packets and gonig down to 1k PPS or 100 PPS (or 10 PPS) would result in a noticable improvement in the flow that the acks are competing against. Stop thinking in terms of single-flow benchmarks and near idle 'upstream' paths. David Lang ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-12-01 0:28 ` David Lang @ 2017-12-01 7:09 ` Jan Ceuleers 2017-12-01 12:53 ` Toke Høiland-Jørgensen 2017-12-01 8:45 ` [Bloat] " Sebastian Moeller 1 sibling, 1 reply; 76+ messages in thread From: Jan Ceuleers @ 2017-12-01 7:09 UTC (permalink / raw) To: bloat On 01/12/17 01:28, David Lang wrote: > Stop thinking in terms of single-flow benchmarks and near idle > 'upstream' paths. Nobody has said it so I will: on wifi-connected endpoints the upstream acks also compete for airtime with the downstream flow. ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-12-01 7:09 ` Jan Ceuleers @ 2017-12-01 12:53 ` Toke Høiland-Jørgensen 2017-12-01 13:13 ` [Bloat] [Make-wifi-fast] " Кирилл Луконин 2017-12-01 13:17 ` [Bloat] " Luca Muscariello 0 siblings, 2 replies; 76+ messages in thread From: Toke Høiland-Jørgensen @ 2017-12-01 12:53 UTC (permalink / raw) To: Jan Ceuleers, bloat, make-wifi-fast Jan Ceuleers <jan.ceuleers@gmail.com> writes: > On 01/12/17 01:28, David Lang wrote: >> Stop thinking in terms of single-flow benchmarks and near idle >> 'upstream' paths. > > Nobody has said it so I will: on wifi-connected endpoints the upstream > acks also compete for airtime with the downstream flow. There's a related discussion going on over on the make-wifi-fast list related to the FastACK scheme proposed by Meraki at this year's IMC: https://conferences.sigcomm.org/imc/2017/papers/imc17-final203.pdf It basically turns link-layer ACKs into upstream TCP ACKs (and handles some of the corner cases resulting from this) and also seems to contain an ACK compression component. -Toke ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] [Make-wifi-fast] benefits of ack filtering 2017-12-01 12:53 ` Toke Høiland-Jørgensen @ 2017-12-01 13:13 ` Кирилл Луконин 2017-12-01 13:22 ` Luca Muscariello 2017-12-11 17:42 ` Simon Barber 2017-12-01 13:17 ` [Bloat] " Luca Muscariello 1 sibling, 2 replies; 76+ messages in thread From: Кирилл Луконин @ 2017-12-01 13:13 UTC (permalink / raw) To: Toke Høiland-Jørgensen; +Cc: Jan Ceuleers, bloat, make-wifi-fast As I noticed from the Meraki document: "FastACK also relies on packet inspection, and will not work when payload is encrypted. However, in our networks, we do not currently see an extensive use of encryption techniques like IPSec." But what about TLS ? As for me, this technology will never work in most cases. Best regards, Lukonin Kirill. 2017-12-01 17:53 GMT+05:00 Toke Høiland-Jørgensen <toke@toke.dk>: > Jan Ceuleers <jan.ceuleers@gmail.com> writes: > >> On 01/12/17 01:28, David Lang wrote: >>> Stop thinking in terms of single-flow benchmarks and near idle >>> 'upstream' paths. >> >> Nobody has said it so I will: on wifi-connected endpoints the upstream >> acks also compete for airtime with the downstream flow. > > There's a related discussion going on over on the make-wifi-fast list > related to the FastACK scheme proposed by Meraki at this year's IMC: > > https://conferences.sigcomm.org/imc/2017/papers/imc17-final203.pdf > > It basically turns link-layer ACKs into upstream TCP ACKs (and handles > some of the corner cases resulting from this) and also seems to contain > an ACK compression component. > > -Toke > _______________________________________________ > Make-wifi-fast mailing list > Make-wifi-fast@lists.bufferbloat.net > https://lists.bufferbloat.net/listinfo/make-wifi-fast -- Best Regards, Lukonin Kirill ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] [Make-wifi-fast] benefits of ack filtering 2017-12-01 13:13 ` [Bloat] [Make-wifi-fast] " Кирилл Луконин @ 2017-12-01 13:22 ` Luca Muscariello 2017-12-11 17:42 ` Simon Barber 1 sibling, 0 replies; 76+ messages in thread From: Luca Muscariello @ 2017-12-01 13:22 UTC (permalink / raw) To: Кирилл Луконин Cc: Toke Høiland-Jørgensen, make-wifi-fast, Jan Ceuleers, bloat [-- Attachment #1: Type: text/plain, Size: 1803 bytes --] I think only IPSEC would be a problem for fastACK but not TLS. On Fri, Dec 1, 2017 at 2:13 PM, Кирилл Луконин <klukonin@gmail.com> wrote: > As I noticed from the Meraki document: > > "FastACK also relies on packet inspection, and will not work when > payload is encrypted. However, in our networks, we do not currently > see an extensive use of encryption techniques like IPSec." > > But what about TLS ? > As for me, this technology will never work in most cases. > > > Best regards, > Lukonin Kirill. > > 2017-12-01 17:53 GMT+05:00 Toke Høiland-Jørgensen <toke@toke.dk>: > > Jan Ceuleers <jan.ceuleers@gmail.com> writes: > > > >> On 01/12/17 01:28, David Lang wrote: > >>> Stop thinking in terms of single-flow benchmarks and near idle > >>> 'upstream' paths. > >> > >> Nobody has said it so I will: on wifi-connected endpoints the upstream > >> acks also compete for airtime with the downstream flow. > > > > There's a related discussion going on over on the make-wifi-fast list > > related to the FastACK scheme proposed by Meraki at this year's IMC: > > > > https://conferences.sigcomm.org/imc/2017/papers/imc17-final203.pdf > > > > It basically turns link-layer ACKs into upstream TCP ACKs (and handles > > some of the corner cases resulting from this) and also seems to contain > > an ACK compression component. > > > > -Toke > > _______________________________________________ > > Make-wifi-fast mailing list > > Make-wifi-fast@lists.bufferbloat.net > > https://lists.bufferbloat.net/listinfo/make-wifi-fast > > > > -- > Best Regards, > Lukonin Kirill > _______________________________________________ > Make-wifi-fast mailing list > Make-wifi-fast@lists.bufferbloat.net > https://lists.bufferbloat.net/listinfo/make-wifi-fast [-- Attachment #2: Type: text/html, Size: 2948 bytes --] ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] [Make-wifi-fast] benefits of ack filtering 2017-12-01 13:13 ` [Bloat] [Make-wifi-fast] " Кирилл Луконин 2017-12-01 13:22 ` Luca Muscariello @ 2017-12-11 17:42 ` Simon Barber 1 sibling, 0 replies; 76+ messages in thread From: Simon Barber @ 2017-12-11 17:42 UTC (permalink / raw) To: Кирилл Луконин, Toke Høiland-Jørgensen Cc: make-wifi-fast, bloat TLS works over TCP, so the TCP headers are not encrypted. Simon Sent with AquaMail for Android http://www.aqua-mail.com On December 11, 2017 8:17:47 AM Кирилл Луконин <klukonin@gmail.com> wrote: > As I noticed from the Meraki document: > > "FastACK also relies on packet inspection, and will not work when > payload is encrypted. However, in our networks, we do not currently > see an extensive use of encryption techniques like IPSec." > > But what about TLS ? > As for me, this technology will never work in most cases. > > > Best regards, > Lukonin Kirill. > > 2017-12-01 17:53 GMT+05:00 Toke Høiland-Jørgensen <toke@toke.dk>: >> Jan Ceuleers <jan.ceuleers@gmail.com> writes: >> >>> On 01/12/17 01:28, David Lang wrote: >>>> Stop thinking in terms of single-flow benchmarks and near idle >>>> 'upstream' paths. >>> >>> Nobody has said it so I will: on wifi-connected endpoints the upstream >>> acks also compete for airtime with the downstream flow. >> >> There's a related discussion going on over on the make-wifi-fast list >> related to the FastACK scheme proposed by Meraki at this year's IMC: >> >> https://conferences.sigcomm.org/imc/2017/papers/imc17-final203.pdf >> >> It basically turns link-layer ACKs into upstream TCP ACKs (and handles >> some of the corner cases resulting from this) and also seems to contain >> an ACK compression component. >> >> -Toke >> _______________________________________________ >> Make-wifi-fast mailing list >> Make-wifi-fast@lists.bufferbloat.net >> https://lists.bufferbloat.net/listinfo/make-wifi-fast > > > > -- > Best Regards, > Lukonin Kirill > _______________________________________________ > Bloat mailing list > Bloat@lists.bufferbloat.net > https://lists.bufferbloat.net/listinfo/bloat ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-12-01 12:53 ` Toke Høiland-Jørgensen 2017-12-01 13:13 ` [Bloat] [Make-wifi-fast] " Кирилл Луконин @ 2017-12-01 13:17 ` Luca Muscariello 2017-12-01 13:40 ` Toke Høiland-Jørgensen 1 sibling, 1 reply; 76+ messages in thread From: Luca Muscariello @ 2017-12-01 13:17 UTC (permalink / raw) To: Toke Høiland-Jørgensen; +Cc: Jan Ceuleers, bloat, make-wifi-fast [-- Attachment #1: Type: text/plain, Size: 1290 bytes --] If I understand the text right, FastACK runs in the AP and generates an ACK on behalf (or despite) of the TCP client end. Then, it decimates dupACKs. This means that there is a stateful connection tracker in the AP. Not so simple. It's almost, not entirely though, a TCP proxy doing Split TCP. On Fri, Dec 1, 2017 at 1:53 PM, Toke Høiland-Jørgensen <toke@toke.dk> wrote: > Jan Ceuleers <jan.ceuleers@gmail.com> writes: > > > On 01/12/17 01:28, David Lang wrote: > >> Stop thinking in terms of single-flow benchmarks and near idle > >> 'upstream' paths. > > > > Nobody has said it so I will: on wifi-connected endpoints the upstream > > acks also compete for airtime with the downstream flow. > > There's a related discussion going on over on the make-wifi-fast list > related to the FastACK scheme proposed by Meraki at this year's IMC: > > https://conferences.sigcomm.org/imc/2017/papers/imc17-final203.pdf > > It basically turns link-layer ACKs into upstream TCP ACKs (and handles > some of the corner cases resulting from this) and also seems to contain > an ACK compression component. > > -Toke > _______________________________________________ > Bloat mailing list > Bloat@lists.bufferbloat.net > https://lists.bufferbloat.net/listinfo/bloat > [-- Attachment #2: Type: text/html, Size: 2172 bytes --] ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-12-01 13:17 ` [Bloat] " Luca Muscariello @ 2017-12-01 13:40 ` Toke Høiland-Jørgensen 2017-12-01 17:42 ` Dave Taht 0 siblings, 1 reply; 76+ messages in thread From: Toke Høiland-Jørgensen @ 2017-12-01 13:40 UTC (permalink / raw) To: Luca Muscariello; +Cc: Jan Ceuleers, bloat, make-wifi-fast Luca Muscariello <luca.muscariello@gmail.com> writes: > If I understand the text right, FastACK runs in the AP and generates an ACK > on behalf (or despite) of the TCP client end. > Then, it decimates dupACKs. > > This means that there is a stateful connection tracker in the AP. Not so > simple. > It's almost, not entirely though, a TCP proxy doing Split TCP. Yeah, it's very much stateful, and tied closely to both TCP and the MAC layer. So it has all the usual middlebox issues as far as that is concerned... Also, APs need to transfer state between each other when the client roams. It does increase single-flow TCP throughput by up to a factor of two, though... Which everyone knows is the most important benchmark number ;) -Toke ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-12-01 13:40 ` Toke Høiland-Jørgensen @ 2017-12-01 17:42 ` Dave Taht 2017-12-01 20:39 ` Juliusz Chroboczek 2017-12-01 21:17 ` Bob McMahon 0 siblings, 2 replies; 76+ messages in thread From: Dave Taht @ 2017-12-01 17:42 UTC (permalink / raw) To: Toke Høiland-Jørgensen; +Cc: Luca Muscariello, make-wifi-fast, bloat Toke Høiland-Jørgensen <toke@toke.dk> writes: > Luca Muscariello <luca.muscariello@gmail.com> writes: > >> If I understand the text right, FastACK runs in the AP and generates an ACK >> on behalf (or despite) of the TCP client end. >> Then, it decimates dupACKs. >> >> This means that there is a stateful connection tracker in the AP. Not so >> simple. >> It's almost, not entirely though, a TCP proxy doing Split TCP. > > Yeah, it's very much stateful, and tied closely to both TCP and the MAC > layer. So it has all the usual middlebox issues as far as that is > concerned... Also, APs need to transfer state between each other when > the client roams. > > It does increase single-flow TCP throughput by up to a factor of two, > though... Which everyone knows is the most important benchmark number ;) Were you always as cynical as I am? I'd like to compare (eventually) what we are trying with cake's new ack filter here, which at least doesn't lie to the endpoint. my guess, however, would be that the media access negotiation will dominate the cost, and savings from (say) reducing 10 acks to 1 would only be somewhere in the 5-20% range, for simple benchmarks. I think we might get a better rrul result, however, as we'd be able to pack more big flows into a given aggregate, with less acks there. > > -Toke > _______________________________________________ > Bloat mailing list > Bloat@lists.bufferbloat.net > https://lists.bufferbloat.net/listinfo/bloat ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-12-01 17:42 ` Dave Taht @ 2017-12-01 20:39 ` Juliusz Chroboczek 2017-12-03 5:20 ` [Bloat] [Make-wifi-fast] " Bob McMahon 2017-12-01 21:17 ` Bob McMahon 1 sibling, 1 reply; 76+ messages in thread From: Juliusz Chroboczek @ 2017-12-01 20:39 UTC (permalink / raw) To: Dave Taht; +Cc: Toke Høiland-Jørgensen, make-wifi-fast, bloat >> It does increase single-flow TCP throughput by up to a factor of two, >> though... Which everyone knows is the most important benchmark number ;) > Were you always as cynical as I am? (Giggle) Dave, you've always underestimated Toke ;-) ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] [Make-wifi-fast] benefits of ack filtering 2017-12-01 20:39 ` Juliusz Chroboczek @ 2017-12-03 5:20 ` Bob McMahon 2017-12-03 10:35 ` Juliusz Chroboczek 0 siblings, 1 reply; 76+ messages in thread From: Bob McMahon @ 2017-12-03 5:20 UTC (permalink / raw) To: Juliusz Chroboczek; +Cc: Dave Taht, make-wifi-fast, bloat [-- Attachment #1: Type: text/plain, Size: 1062 bytes --] I'm skeptical that this would improve single stream throughput by a factor of two. The larger RTT would drive larger aggregations and it's aggregation that scales peak average throughput. Also, the time difference between the 802.11 ack and the client network stack writing the TCP ack would probably be in the 100s of microseconds (mileage will vary.) So it's the client's media access that will drive the increase in RTT. It might be preferred to modify EDCA parameters to reduce media access latencies for TCP acks rather than spoof them. Bob On Fri, Dec 1, 2017 at 12:39 PM, Juliusz Chroboczek <jch@irif.fr> wrote: > >> It does increase single-flow TCP throughput by up to a factor of two, > >> though... Which everyone knows is the most important benchmark number ;) > > > Were you always as cynical as I am? > > (Giggle) > > Dave, you've always underestimated Toke ;-) > _______________________________________________ > Make-wifi-fast mailing list > Make-wifi-fast@lists.bufferbloat.net > https://lists.bufferbloat.net/listinfo/make-wifi-fast > [-- Attachment #2: Type: text/html, Size: 1679 bytes --] ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] [Make-wifi-fast] benefits of ack filtering 2017-12-03 5:20 ` [Bloat] [Make-wifi-fast] " Bob McMahon @ 2017-12-03 10:35 ` Juliusz Chroboczek 2017-12-03 11:40 ` Jan Ceuleers 2017-12-03 19:04 ` Bob McMahon 0 siblings, 2 replies; 76+ messages in thread From: Juliusz Chroboczek @ 2017-12-03 10:35 UTC (permalink / raw) To: Bob McMahon; +Cc: Dave Taht, make-wifi-fast, bloat > It might be preferred to modify EDCA parameters to reduce media access > latencies for TCP acks rather than spoof them. I'm lost here. What exact problem is the ACK hack supposed to work around? Ridiculous amount of asymmetry in the last-hop WiFi link, or outrageous amounts of asymmetry in a transit link beyond the last hop? -- Juliusz ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] [Make-wifi-fast] benefits of ack filtering 2017-12-03 10:35 ` Juliusz Chroboczek @ 2017-12-03 11:40 ` Jan Ceuleers 2017-12-03 13:57 ` Juliusz Chroboczek 2017-12-04 3:44 ` Dave Taht 2017-12-03 19:04 ` Bob McMahon 1 sibling, 2 replies; 76+ messages in thread From: Jan Ceuleers @ 2017-12-03 11:40 UTC (permalink / raw) To: bloat On 03/12/17 11:35, Juliusz Chroboczek wrote: > I'm lost here. What exact problem is the ACK hack supposed to work > around? Ridiculous amount of asymmetry in the last-hop WiFi link, or > outrageous amounts of asymmetry in a transit link beyond the last hop? My understanding is that the issue that gave rise to this discussion was concerned with upstream bandwidth conservation in the uplink of a DOCSIS network by the cable modem dropping a large percentage of upstream TCP ACKs. One element of that discussion was the question as to whether it was OK for middleboxes (such as in this case cable modems) to reduce the number of TCP ACKs, or whether instead the TCP stacks in the endpoints should be made to send fewer such ACKs in the first place. I then added more confusion by saying that in the case of wifi-connected endpoints the upstream TCP ACKs also compete for airtime with the downstream flow. Of course this no longer has anything to do with the cable modem. ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] [Make-wifi-fast] benefits of ack filtering 2017-12-03 11:40 ` Jan Ceuleers @ 2017-12-03 13:57 ` Juliusz Chroboczek 2017-12-03 14:07 ` Mikael Abrahamsson ` (2 more replies) 2017-12-04 3:44 ` Dave Taht 1 sibling, 3 replies; 76+ messages in thread From: Juliusz Chroboczek @ 2017-12-03 13:57 UTC (permalink / raw) To: Jan Ceuleers; +Cc: bloat >> I'm lost here. What exact problem is the ACK hack supposed to work >> around? Ridiculous amount of asymmetry in the last-hop WiFi link, or >> outrageous amounts of asymmetry in a transit link beyond the last hop? > My understanding is that the issue that gave rise to this discussion was > concerned with upstream bandwidth conservation in the uplink of a DOCSIS > network by the cable modem dropping a large percentage of upstream TCP ACKs. Ok, that's what I thought. I'm glad we agree that WiFi is a different issue. A TCP Ack is 40 bytes. A data packet is up to 1500 bytes. As far as I know, DOCSIS has an asymmetry factor that is between 4 and 10, depending on the deployment. With worst case asymmetry being 10, this means that you can send an Ack for every data packet with 400 byte data packets, every second data packet with 200 byte data packets. If the asymmetry is a more reasonable 4, then the figures are 100 and 50 respectively. Try as I might, I fail to see the problem. Are we advocating deploying TCP-aware middleboxes, with all the problems that entails, in order to work around a problem that doesn't exist? -- Juliusz ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] [Make-wifi-fast] benefits of ack filtering 2017-12-03 13:57 ` Juliusz Chroboczek @ 2017-12-03 14:07 ` Mikael Abrahamsson 2017-12-03 19:53 ` Juliusz Chroboczek 2017-12-03 14:09 ` Ryan Mounce 2017-12-03 15:25 ` Robert Bradley 2 siblings, 1 reply; 76+ messages in thread From: Mikael Abrahamsson @ 2017-12-03 14:07 UTC (permalink / raw) To: Juliusz Chroboczek; +Cc: Jan Ceuleers, bloat On Sun, 3 Dec 2017, Juliusz Chroboczek wrote: > As far as I know, DOCSIS has an asymmetry factor that is between 4 and 10, > depending on the deployment. With worst case asymmetry being 10, this I can buy 300/10 megabit/s access from my cable provider. So that's a lot worse. My cable box has 16 downstream channels, and 4 upstream ones. Each channel is TDM based, and there is some kind of scheduler granting sending opportunities for each channel to each modem, as needed. I'm not a DOCSIS expert. > means that you can send an Ack for every data packet with 400 byte data > packets, every second data packet with 200 byte data packets. If the > asymmetry is a more reasonable 4, then the figures are 100 and 50 > respectively. > > Try as I might, I fail to see the problem. Are we advocating deploying > TCP-aware middleboxes, with all the problems that entails, in order to > work around a problem that doesn't exist? If I understand correctly, DOCSIS has ~1ms sending opportunities upstream. So sending more than 1kPPS of ACKs is meaningless, as these ACKs will just come back to back at wire-speed as the CMTS receives them from the modem in chunks. So instead, the cable modem just deletes all the sequential ACKs and doesn't even send these back-to-back ones. LTE works the same, it's also frequency divided and TDM, so I can see the same benefit there of culling sequential ACKs sitting there in the buffer. I don't know if this is done though. I've seen people I think are involved in TCP design. They seem to be under the impression that more ACKs give higher resolution and granularity to TCP. My postulation is that this is commonly false because of how the network access is designed and how also the NICs are designed (the transmit/receive offloading). So sending 35kPPS of ACKs for a gigabit/s transfer is just inefficient and shouldn't be done. I would prefer if end points would send less ACKs instead of the network killing them. And the network does kill them, as we have seen. Because any novice network access technology designer can say "oh, having 16 sequential ACKs here in my buffer, sitting waiting to get sent, is just useless information. Let's kill the 15 first ones." -- Mikael Abrahamsson email: swmike@swm.pp.se ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] [Make-wifi-fast] benefits of ack filtering 2017-12-03 14:07 ` Mikael Abrahamsson @ 2017-12-03 19:53 ` Juliusz Chroboczek 0 siblings, 0 replies; 76+ messages in thread From: Juliusz Chroboczek @ 2017-12-03 19:53 UTC (permalink / raw) To: Mikael Abrahamsson; +Cc: bloat > I can buy 300/10 megabit/s access from my cable provider. Don't! > If I understand correctly, DOCSIS has ~1ms sending opportunities > upstream. So sending more than 1kPPS of ACKs is meaningless, as these ACKs > will just come back to back at wire-speed as the CMTS receives them from > the modem in chunks. So instead, the cable modem just deletes all the > sequential ACKs and doesn't even send these back-to-back ones. If true -- then it's horrible. > LTE works the same, it's also frequency divided and TDM, so I can see the > same benefit there of culling sequential ACKs sitting there in the > buffer. I don't know if this is done though. I cannot find anything about Ack compression in LTE. (The PDCP protocol does header compression, so that's the place I'm looking.) -- Juliusz ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] [Make-wifi-fast] benefits of ack filtering 2017-12-03 13:57 ` Juliusz Chroboczek 2017-12-03 14:07 ` Mikael Abrahamsson @ 2017-12-03 14:09 ` Ryan Mounce 2017-12-03 19:54 ` Juliusz Chroboczek 2017-12-03 15:25 ` Robert Bradley 2 siblings, 1 reply; 76+ messages in thread From: Ryan Mounce @ 2017-12-03 14:09 UTC (permalink / raw) To: Juliusz Chroboczek; +Cc: Jan Ceuleers, bloat On 4 December 2017 at 00:27, Juliusz Chroboczek <jch@irif.fr> wrote: >>> I'm lost here. What exact problem is the ACK hack supposed to work >>> around? Ridiculous amount of asymmetry in the last-hop WiFi link, or >>> outrageous amounts of asymmetry in a transit link beyond the last hop? > >> My understanding is that the issue that gave rise to this discussion was >> concerned with upstream bandwidth conservation in the uplink of a DOCSIS >> network by the cable modem dropping a large percentage of upstream TCP ACKs. > > Ok, that's what I thought. I'm glad we agree that WiFi is a different issue. > > A TCP Ack is 40 bytes. A data packet is up to 1500 bytes. > > As far as I know, DOCSIS has an asymmetry factor that is between 4 and 10, > depending on the deployment. With worst case asymmetry being 10, this > means that you can send an Ack for every data packet with 400 byte data > packets, every second data packet with 200 byte data packets. If the > asymmetry is a more reasonable 4, then the figures are 100 and 50 > respectively. > Many would kill for a 10:1 DOCSIS connection. 50:1 is not rare, and I have personally been subscribed to a near 100:1 service. Either way, the issue is not so much ACKs from downloads on an otherwise idle link. The real issue is when the ACKs are contending with a file upload, in this case download speeds will suffer if ACKs are naively tail-dropped. Recovering extra bandwidth for the file upload can be a happy side-effect. You're also only counting IP packet length. The DOCSIS shaper deals with ethernet frames so 58 / 1518 bytes. > Try as I might, I fail to see the problem. Are we advocating deploying > TCP-aware middleboxes, with all the problems that entails, in order to > work around a problem that doesn't exist? > > -- Juliusz > _______________________________________________ > Bloat mailing list > Bloat@lists.bufferbloat.net > https://lists.bufferbloat.net/listinfo/bloat Regards, Ryan Mounce ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] [Make-wifi-fast] benefits of ack filtering 2017-12-03 14:09 ` Ryan Mounce @ 2017-12-03 19:54 ` Juliusz Chroboczek 2017-12-03 20:14 ` Sebastian Moeller 0 siblings, 1 reply; 76+ messages in thread From: Juliusz Chroboczek @ 2017-12-03 19:54 UTC (permalink / raw) To: Ryan Mounce; +Cc: bloat > Many would kill for a 10:1 DOCSIS connection. 50:1 is not rare, and I > have personally been subscribed to a near 100:1 service. Some people should not be allowed to design networks. > The DOCSIS shaper deals with ethernet frames so 58 / 1518 bytes. Could you please point me to details of the DOCSIS shaper? -- Juliusz ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] [Make-wifi-fast] benefits of ack filtering 2017-12-03 19:54 ` Juliusz Chroboczek @ 2017-12-03 20:14 ` Sebastian Moeller 2017-12-03 22:27 ` Dave Taht 0 siblings, 1 reply; 76+ messages in thread From: Sebastian Moeller @ 2017-12-03 20:14 UTC (permalink / raw) To: bloat, Juliusz Chroboczek, Ryan Mounce On December 3, 2017 8:54:40 PM GMT+01:00, Juliusz Chroboczek <jch@irif.fr> wrote: >> Many would kill for a 10:1 DOCSIS connection. 50:1 is not rare, and I >> have personally been subscribed to a near 100:1 service. > >Some people should not be allowed to design networks. > >> The DOCSIS shaper deals with ethernet frames so 58 / 1518 bytes. > >Could you please point me to details of the DOCSIS shaper? the relevant section from the Docsis standard (http://www.cablelabs.com/specification/docsis-3-0-mac-and-upper-layer-protocols-interface-specification/): "C.2.2.7.2 Maximum Sustained Traffic Rate 632 This parameter is the rate parameter R of a token-bucket-based rate limit for packets. R is expressed in bits per second, and MUST take into account all MAC frame data PDU of the Service Flow from the byte following the MAC header HCS to the end of the CRC, including every PDU in the case of a Concatenated MAC Frame. This parameter is applied after Payload Header Suppression; it does not include the bytes suppressed for PHS. The number of bytes forwarded (in bytes) is limited during any time interval T by Max(T), as described in the expression: Max(T) = T * (R / 8) + B, (1) where the parameter B (in bytes) is the Maximum Traffic Burst Configuration Setting (refer to Annex C.2.2.7.3). NOTE: This parameter does not limit the instantaneous rate of the Service Flow. The specific algorithm for enforcing this parameter is not mandated here. Any implementation which satisfies the above equation is conformant. In particular, the granularity of enforcement and the minimum implemented value of this parameter are vendor specific. The CMTS SHOULD support a granularity of at most 100 kbps. The CM SHOULD support a granularity of at most 100 kbps. NOTE: If this parameter is omitted or set to zero, then there is no explicitly-enforced traffic rate maximum. This field specifies only a bound, not a guarantee that this rate is available." So in essence DOCSIS users need to only account for 18 Bytes of ethernet overhead in both ingress and egress directions under non-congested conditions. > >-- Juliusz >_______________________________________________ >Bloat mailing list >Bloat@lists.bufferbloat.net >https://lists.bufferbloat.net/listinfo/bloat -- Sent from my Android device with K-9 Mail. Please excuse my brevity. ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] [Make-wifi-fast] benefits of ack filtering 2017-12-03 20:14 ` Sebastian Moeller @ 2017-12-03 22:27 ` Dave Taht 0 siblings, 0 replies; 76+ messages in thread From: Dave Taht @ 2017-12-03 22:27 UTC (permalink / raw) To: Sebastian Moeller; +Cc: bloat, Juliusz Chroboczek, Ryan Mounce On Sun, Dec 3, 2017 at 12:14 PM, Sebastian Moeller <moeller0@gmx.de> wrote: > > > On December 3, 2017 8:54:40 PM GMT+01:00, Juliusz Chroboczek <jch@irif.fr> wrote: >>> Many would kill for a 10:1 DOCSIS connection. 50:1 is not rare, and I >>> have personally been subscribed to a near 100:1 service. >> >>Some people should not be allowed to design networks. The upstream/downstream problem over long distances has been problematic for dsl (phone line) and cable (coax) deployments. The head-ends have much greater control over the signal strengths than the (usually much cheaper) Gpon fiber is also commonly sold in 1Gbit/100Mbit modes. Testing on a GPON network showed about 80ms worth of buffering in the ONT - which we can get rid of entirely, in cake. >>> The DOCSIS shaper deals with ethernet frames so 58 / 1518 bytes. >> >>Could you please point me to details of the DOCSIS shaper? > > the relevant section from the Docsis standard (http://www.cablelabs.com/specification/docsis-3-0-mac-and-upper-layer-protocols-interface-specification/): > > "C.2.2.7.2 Maximum Sustained Traffic Rate 632 This parameter is the rate parameter R of a token-bucket-based rate limit for packets. R is expressed in bits per second, and MUST take into account all MAC frame data PDU of the Service Flow from the byte following the MAC header HCS to the end of the CRC, including every PDU in the case of a Concatenated MAC Frame. This parameter is applied after Payload Header Suppression; it does not include the bytes suppressed for PHS. The number of bytes forwarded (in bytes) is limited during any time interval T by Max(T), as described in the expression: Max(T) = T * (R / 8) + B, (1) where the parameter B (in bytes) is the Maximum Traffic Burst Configuration Setting (refer to Annex C.2.2.7.3). NOTE: This parameter does not limit the instantaneous rate of the Service Flow. The specific algorithm for enforcing this parameter is not mandated here. Any implementation which satisfies the above equation is conformant. In particular, the granularity of enforcement and the minimum implemented value of this parameter are vendor specific. The CMTS SHOULD support a granularity of at most 100 kbps. The CM SHOULD support a granularity of at most 100 kbps. NOTE: If this parameter is omitted or set to zero, then there is no explicitly-enforced traffic rate maximum. This field specifies only a bound, not a guarantee that this rate is available." > > So in essence DOCSIS users need to only account for 18 Bytes of ethernet overhead in both ingress and egress directions under non-congested conditions. Also, cake, as a deficit mode shaper, it is the opposite of how htb functions in terms of bursts. TB tries to make up for bandwidth you should have, verses cake which gives you the bandwidth you have "right now". This lets us set the shaper much closer (seemingly exact in the case of docsis, atleast) to the actual configured TB rate (with better fq/aqm queue management) I just submitted an initial patch for cake to net-next after a huge round of testing. > > > >> >>-- Juliusz >>_______________________________________________ >>Bloat mailing list >>Bloat@lists.bufferbloat.net >>https://lists.bufferbloat.net/listinfo/bloat > > -- > Sent from my Android device with K-9 Mail. Please excuse my brevity. > _______________________________________________ > Bloat mailing list > Bloat@lists.bufferbloat.net > https://lists.bufferbloat.net/listinfo/bloat -- Dave Täht CEO, TekLibre, LLC http://www.teklibre.com Tel: 1-669-226-2619 ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] [Make-wifi-fast] benefits of ack filtering 2017-12-03 13:57 ` Juliusz Chroboczek 2017-12-03 14:07 ` Mikael Abrahamsson 2017-12-03 14:09 ` Ryan Mounce @ 2017-12-03 15:25 ` Robert Bradley 2 siblings, 0 replies; 76+ messages in thread From: Robert Bradley @ 2017-12-03 15:25 UTC (permalink / raw) To: bloat [-- Attachment #1.1: Type: text/plain, Size: 654 bytes --] On 03/12/2017 13:57, Juliusz Chroboczek wrote: > A TCP Ack is 40 bytes. A data packet is up to 1500 bytes. > > As far as I know, DOCSIS has an asymmetry factor that is between 4 and 10, > depending on the deployment. With worst case asymmetry being 10, this > means that you can send an Ack for every data packet with 400 byte data > packets, every second data packet with 200 byte data packets. If the > asymmetry is a more reasonable 4, then the figures are 100 and 50 > respectively. > I currently have 230 Mb/s down to 12.7 Mb/s up, so about an 18:1 ratio. That's roughly an ACK for every 750 byte packet. -- Robert Bradley [-- Attachment #2: OpenPGP digital signature --] [-- Type: application/pgp-signature, Size: 834 bytes --] ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] [Make-wifi-fast] benefits of ack filtering 2017-12-03 11:40 ` Jan Ceuleers 2017-12-03 13:57 ` Juliusz Chroboczek @ 2017-12-04 3:44 ` Dave Taht 2017-12-04 14:38 ` David Collier-Brown 1 sibling, 1 reply; 76+ messages in thread From: Dave Taht @ 2017-12-04 3:44 UTC (permalink / raw) To: Jan Ceuleers; +Cc: bloat Jan Ceuleers <jan.ceuleers@gmail.com> writes: > On 03/12/17 11:35, Juliusz Chroboczek wrote: >> I'm lost here. What exact problem is the ACK hack supposed to work >> around? Ridiculous amount of asymmetry in the last-hop WiFi link, or >> outrageous amounts of asymmetry in a transit link beyond the last hop? > > My understanding is that the issue that gave rise to this discussion was > concerned with upstream bandwidth conservation in the uplink of a DOCSIS > network by the cable modem dropping a large percentage of upstream TCP ACKs. > > One element of that discussion was the question as to whether it was OK > for middleboxes (such as in this case cable modems) to reduce the number > of TCP ACKs, or whether instead the TCP stacks in the endpoints should > be made to send fewer such ACKs in the first place. > > I then added more confusion by saying that in the case of wifi-connected > endpoints the upstream TCP ACKs also compete for airtime with the > downstream flow. Of course this no longer has anything to do with the > cable modem. More generally, the case where you have a queue containing acks, stored up for whatever reason (congestion, media access, asymmetry), is a chance for a middlebox or host to do something "smarter" to thin them out. Acks don't respond to conventional congestion control mechanisms anyway. There is another case (that I don't support) where you would try to filter out acks on the fly without a queue (similar to how a policer works). The flaws of this approach are many, including tail loss, which the concept of filtering down (reducing?) a queue, doesn't have. fq_codel has a tendency to gather up flows into a quantum (usually 1514 bytes), which translates out to 22 ipv4 acks before it will switch flows. The cake implementation will always deliver the lastmost ack packet, and also has some compensations for stuff in slow start. (it could use a more formal state machine, and perhaps tuning out the sparse flow optimization, and more testing. It certainly is not fast code, but still cheaper than the hashing bits in cake) > _______________________________________________ > Bloat mailing list > Bloat@lists.bufferbloat.net > https://lists.bufferbloat.net/listinfo/bloat ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] [Make-wifi-fast] benefits of ack filtering 2017-12-04 3:44 ` Dave Taht @ 2017-12-04 14:38 ` David Collier-Brown 2017-12-04 15:44 ` Juliusz Chroboczek 0 siblings, 1 reply; 76+ messages in thread From: David Collier-Brown @ 2017-12-04 14:38 UTC (permalink / raw) To: bloat On 03/12/17 10:44 PM, Dave Taht wrote: > More generally, the case where you have a queue containing acks, stored > up for whatever reason (congestion, media access, asymmetry), is a > chance for a middlebox or host to do something "smarter" to thin them > out. > > Acks don't respond to conventional congestion control mechanisms anyway. > > There is another case (that I don't support) where you would try to > filter out acks on the fly without a queue (similar to how a policer > works). The flaws of this approach are many, including tail loss, > which the concept of filtering down (reducing?) a queue, doesn't have. Taking a very high-level view of this discussion, the times you want to change a protocol or add a 'network optimizer" are when enough time has passed that the original requirements don't describe what you want any more. In a previous life I did some work on the optimization (by remote proxying) of the SMB protocol used by Samba. It was very desirable, but at the cost of continuing to support a protocol that did the wrong thing, and kludging it with additional middleware. In effect, making your new system dependent on a bug in the old one. Eventually we said the heck with it, and sat Samba on top of a different protocol entirely, one which worked well over non-local links. That concentrate the impedance matching in Samba, not in code I had to maintain in synchronization with a bug (;-)) --dave -- David Collier-Brown, | Always do right. This will gratify System Programmer and Author | some people and astonish the rest davecb@spamcop.net | -- Mark Twain ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] [Make-wifi-fast] benefits of ack filtering 2017-12-04 14:38 ` David Collier-Brown @ 2017-12-04 15:44 ` Juliusz Chroboczek 2017-12-04 17:17 ` David Collier-Brown 0 siblings, 1 reply; 76+ messages in thread From: Juliusz Chroboczek @ 2017-12-04 15:44 UTC (permalink / raw) To: davecb; +Cc: bloat > In a previous life I did some work on the optimization (by remote > proxying) of the SMB protocol used by Samba [...] Eventually we said > the heck with it, and sat Samba on top of a different protocol entirely, The audience are waiting with held breath for more details. -- Juliusz ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] [Make-wifi-fast] benefits of ack filtering 2017-12-04 15:44 ` Juliusz Chroboczek @ 2017-12-04 17:17 ` David Collier-Brown 0 siblings, 0 replies; 76+ messages in thread From: David Collier-Brown @ 2017-12-04 17:17 UTC (permalink / raw) To: Juliusz Chroboczek, davecb; +Cc: bloat [-- Attachment #1: Type: text/plain, Size: 1073 bytes --] On 04/12/17 10:44 AM, Juliusz Chroboczek wrote: >> In a previous life I did some work on the optimization (by remote >> proxying) of the SMB protocol used by Samba [...] Eventually we said >> the heck with it, and sat Samba on top of a different protocol entirely, > The audience are waiting with held breath for more details. > > -- Juliusz > They aren't discussable in polite company. Way too much cursing (;-)) Joking aside, that was definitely a case where we said "don't go there". To the best of my knowledge, there are two network optimization products that do SMB, so it's physically possible. In our opinion, it was better to use the SMB protocol locally and a different, cached, protocol over a wide-area network. I actually prototyped it with Solaris NFS and cachefs, and was pleasantly surprised it worked for a single-writer case. --dave -- David Collier-Brown, | Always do right. This will gratify System Programmer and Author | some people and astonish the rest davecb@spamcop.net | -- Mark Twain [-- Attachment #2: Type: text/html, Size: 1759 bytes --] ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] [Make-wifi-fast] benefits of ack filtering 2017-12-03 10:35 ` Juliusz Chroboczek 2017-12-03 11:40 ` Jan Ceuleers @ 2017-12-03 19:04 ` Bob McMahon 1 sibling, 0 replies; 76+ messages in thread From: Bob McMahon @ 2017-12-03 19:04 UTC (permalink / raw) To: Juliusz Chroboczek; +Cc: Dave Taht, make-wifi-fast, bloat [-- Attachment #1: Type: text/plain, Size: 522 bytes --] My understanding per the thread is a last hop wifi link. I could be wrong though. Bob On Sun, Dec 3, 2017 at 2:35 AM, Juliusz Chroboczek <jch@irif.fr> wrote: > > It might be preferred to modify EDCA parameters to reduce media access > > latencies for TCP acks rather than spoof them. > > I'm lost here. What exact problem is the ACK hack supposed to work > around? Ridiculous amount of asymmetry in the last-hop WiFi link, or > outrageous amounts of asymmetry in a transit link beyond the last hop? > > -- Juliusz > [-- Attachment #2: Type: text/html, Size: 930 bytes --] ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] [Make-wifi-fast] benefits of ack filtering 2017-12-01 17:42 ` Dave Taht 2017-12-01 20:39 ` Juliusz Chroboczek @ 2017-12-01 21:17 ` Bob McMahon 1 sibling, 0 replies; 76+ messages in thread From: Bob McMahon @ 2017-12-01 21:17 UTC (permalink / raw) To: Dave Taht; +Cc: Toke Høiland-Jørgensen, make-wifi-fast, bloat [-- Attachment #1: Type: text/plain, Size: 2518 bytes --] 802.11 acks are packet or ampdu driven while tcp, being a byte protocol, acks bytes. Aligning these may not be straightforward. We test with different read() rates on the wifi clients as TCP is supposed to flow control the source's writes() as well. Wifi clients are starting to align their sleep cycles with "natural" periodicity in traffic so having larger aggregates can help both peak average throughput as well as power consumption. It's not obvious with Wifi that a faster RTT is always better. (Reminds me of the early days of NASA where many designed to reduce weight without keeping in account structural integrity, shave a few grams and lose a rocket.) Bob On Fri, Dec 1, 2017 at 9:42 AM, Dave Taht <dave@taht.net> wrote: > Toke Høiland-Jørgensen <toke@toke.dk> writes: > > > Luca Muscariello <luca.muscariello@gmail.com> writes: > > > >> If I understand the text right, FastACK runs in the AP and generates an > ACK > >> on behalf (or despite) of the TCP client end. > >> Then, it decimates dupACKs. > >> > >> This means that there is a stateful connection tracker in the AP. Not so > >> simple. > >> It's almost, not entirely though, a TCP proxy doing Split TCP. > > > > Yeah, it's very much stateful, and tied closely to both TCP and the MAC > > layer. So it has all the usual middlebox issues as far as that is > > concerned... Also, APs need to transfer state between each other when > > the client roams. > > > > It does increase single-flow TCP throughput by up to a factor of two, > > though... Which everyone knows is the most important benchmark number ;) > > Were you always as cynical as I am? > > I'd like to compare (eventually) what we are trying with cake's new ack > filter here, which at least doesn't lie to the endpoint. > > my guess, however, would be that the media access negotiation will > dominate the cost, and savings from (say) reducing 10 acks to 1 would > only be somewhere in the 5-20% range, for simple benchmarks. > > I think we might get a better rrul result, however, as we'd be able to > pack more big flows into a given aggregate, with less acks there. > > > > > -Toke > > _______________________________________________ > > Bloat mailing list > > Bloat@lists.bufferbloat.net > > https://lists.bufferbloat.net/listinfo/bloat > _______________________________________________ > Make-wifi-fast mailing list > Make-wifi-fast@lists.bufferbloat.net > https://lists.bufferbloat.net/listinfo/make-wifi-fast > [-- Attachment #2: Type: text/html, Size: 3532 bytes --] ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-12-01 0:28 ` David Lang 2017-12-01 7:09 ` Jan Ceuleers @ 2017-12-01 8:45 ` Sebastian Moeller 2017-12-01 10:45 ` Luca Muscariello 1 sibling, 1 reply; 76+ messages in thread From: Sebastian Moeller @ 2017-12-01 8:45 UTC (permalink / raw) To: David Lang; +Cc: Mikael Abrahamsson, bloat Hi All, you do realize that the worst case is going to stay at 35KPPS? If we assume simply that the 100Mbps download rate is not created by a single flow but by many flows (say 70K flows) the discussed ACK frequency reduction schemes will not work that well. So ACK thinning is a nice optimization, but will not help the fact that some ISPs/link technologies simply are asymmetric and the user will suffer under some traffic conditions. Now the 70K flow example is too extreme, but the fact is at hight flow number with sparse flows (so fewer ACKs per flow in the queue and fewer ACKs per flow reaching the end NIC in a GRO-collection interval (I naively assume there is a somewhat fixed but small interval in which packets of the same flow are collected for GRO)) there will be problems. (Again, I am all for allowing the end user to configure ACK filtering thinning, but I would rather see ISPs sell less imbalanced links ;) ) Best Regards Sebastian > On Dec 1, 2017, at 01:28, David Lang <david@lang.hm> wrote: > > 35K PPS of acks is insane, one ack every ms is FAR more than enough to do 'fast recovery', and outside the datacenter, one ack per 10ms is probably more than enough. > > Assuming something that's not too assymetric, thinning out the acks may not make any difference in the transfer rate of a single data flow in one direction, but if you step back and realize that there may be a need to transfer data in the other direction, things change here. > > If you have a fully symmetrical link, and are maxing it out in both direction, going from 35K PPs of aks competing with data packets and gonig down to 1k PPS or 100 PPS (or 10 PPS) would result in a noticable improvement in the flow that the acks are competing against. > > Stop thinking in terms of single-flow benchmarks and near idle 'upstream' paths. > > David Lang > _______________________________________________ > Bloat mailing list > Bloat@lists.bufferbloat.net > https://lists.bufferbloat.net/listinfo/bloat ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-12-01 8:45 ` [Bloat] " Sebastian Moeller @ 2017-12-01 10:45 ` Luca Muscariello 2017-12-01 18:43 ` Dave Taht 0 siblings, 1 reply; 76+ messages in thread From: Luca Muscariello @ 2017-12-01 10:45 UTC (permalink / raw) To: Sebastian Moeller; +Cc: David Lang, bloat [-- Attachment #1: Type: text/plain, Size: 3032 bytes --] For highly asymmetric links, but also shared media like wifi, QUIC might be a better playground for optimisations. Not pervasive as TCP though and maybe off topic in this thread. If the downlink is what one want to optimise, using FEC in the downstream, in conjunction with flow control could be very effective. No need to send ACK frequently and having something like FQ_codel in the downstream would avoid fairness problems that might happen though. I don't know if FEC is still in QUIC and used. BTW, for wifi, the ACK stream can be compressed in aggregate of frames and sent in bursts. This is similar to DOCSIS upstream. I wonder if this is a phenomenon that is visible in recent WiFi or just negligible. On Fri, Dec 1, 2017 at 9:45 AM, Sebastian Moeller <moeller0@gmx.de> wrote: > Hi All, > > you do realize that the worst case is going to stay at 35KPPS? If we > assume simply that the 100Mbps download rate is not created by a single > flow but by many flows (say 70K flows) the discussed ACK frequency > reduction schemes will not work that well. So ACK thinning is a nice > optimization, but will not help the fact that some ISPs/link technologies > simply are asymmetric and the user will suffer under some traffic > conditions. Now the 70K flow example is too extreme, but the fact is at > hight flow number with sparse flows (so fewer ACKs per flow in the queue > and fewer ACKs per flow reaching the end NIC in a GRO-collection interval > (I naively assume there is a somewhat fixed but small interval in which > packets of the same flow are collected for GRO)) there will be problems. > (Again, I am all for allowing the end user to configure ACK filtering > thinning, but I would rather see ISPs sell less imbalanced links ;) ) > > Best Regards > Sebastian > > > On Dec 1, 2017, at 01:28, David Lang <david@lang.hm> wrote: > > > > 35K PPS of acks is insane, one ack every ms is FAR more than enough to > do 'fast recovery', and outside the datacenter, one ack per 10ms is > probably more than enough. > > > > Assuming something that's not too assymetric, thinning out the acks may > not make any difference in the transfer rate of a single data flow in one > direction, but if you step back and realize that there may be a need to > transfer data in the other direction, things change here. > > > > If you have a fully symmetrical link, and are maxing it out in both > direction, going from 35K PPs of aks competing with data packets and gonig > down to 1k PPS or 100 PPS (or 10 PPS) would result in a noticable > improvement in the flow that the acks are competing against. > > > > Stop thinking in terms of single-flow benchmarks and near idle > 'upstream' paths. > > > > David Lang > > _______________________________________________ > > Bloat mailing list > > Bloat@lists.bufferbloat.net > > https://lists.bufferbloat.net/listinfo/bloat > > _______________________________________________ > Bloat mailing list > Bloat@lists.bufferbloat.net > https://lists.bufferbloat.net/listinfo/bloat > [-- Attachment #2: Type: text/html, Size: 4135 bytes --] ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-12-01 10:45 ` Luca Muscariello @ 2017-12-01 18:43 ` Dave Taht 2017-12-01 18:57 ` Luca Muscariello 0 siblings, 1 reply; 76+ messages in thread From: Dave Taht @ 2017-12-01 18:43 UTC (permalink / raw) To: Luca Muscariello; +Cc: Sebastian Moeller, bloat Luca Muscariello <luca.muscariello@gmail.com> writes: > For highly asymmetric links, but also shared media like wifi, QUIC might be a > better playground for optimisations. > Not pervasive as TCP though and maybe off topic in this thread. I happen to really like QUIC, but a netperf-style tool did not exist for it when I last looked, last year. Also getting to emulating DASH traffic is on my list. > > If the downlink is what one want to optimise, using FEC in the downstream, in > conjunction with flow control could be very effective. > No need to send ACK frequently and having something like FQ_codel in the > downstream would avoid fairness problems that might > happen though. I don't know if FEC is still in QUIC and used. > > BTW, for wifi, the ACK stream can be compressed in aggregate of frames and sent > in bursts. This is similar to DOCSIS upstream. > I wonder if this is a phenomenon that is visible in recent WiFi or just > negligible. My guess is meraki deployed something and I think they are in in the top 5 in the enterprise market. I see ubnt added airtime fairness (of some sort), recently. > > On Fri, Dec 1, 2017 at 9:45 AM, Sebastian Moeller <moeller0@gmx.de> wrote: > > Hi All, > > you do realize that the worst case is going to stay at 35KPPS? If we assume > simply that the 100Mbps download rate is not created by a single flow but by > many flows (say 70K flows) the discussed ACK frequency reduction schemes > will not work that well. So ACK thinning is a nice optimization, but will > not help the fact that some ISPs/link technologies simply are asymmetric and > the user will suffer under some traffic conditions. Now the 70K flow example > is too extreme, but the fact is at hight flow number with sparse flows (so > fewer ACKs per flow in the queue and fewer ACKs per flow reaching the end > NIC in a GRO-collection interval (I naively assume there is a somewhat fixed > but small interval in which packets of the same flow are collected for GRO)) > there will be problems. (Again, I am all for allowing the end user to > configure ACK filtering thinning, but I would rather see ISPs sell less > imbalanced links ;) ) > > Best Regards > Sebastian > > > > > On Dec 1, 2017, at 01:28, David Lang <david@lang.hm> wrote: > > > > 35K PPS of acks is insane, one ack every ms is FAR more than enough to do > 'fast recovery', and outside the datacenter, one ack per 10ms is probably > more than enough. > > > > Assuming something that's not too assymetric, thinning out the acks may > not make any difference in the transfer rate of a single data flow in one > direction, but if you step back and realize that there may be a need to > transfer data in the other direction, things change here. > > > > If you have a fully symmetrical link, and are maxing it out in both > direction, going from 35K PPs of aks competing with data packets and gonig > down to 1k PPS or 100 PPS (or 10 PPS) would result in a noticable > improvement in the flow that the acks are competing against. > > > > Stop thinking in terms of single-flow benchmarks and near idle 'upstream' > paths. > > > > David Lang > > _______________________________________________ > > Bloat mailing list > > Bloat@lists.bufferbloat.net > > https://lists.bufferbloat.net/listinfo/bloat > > _______________________________________________ > Bloat mailing list > Bloat@lists.bufferbloat.net > https://lists.bufferbloat.net/listinfo/bloat > > > > _______________________________________________ > Bloat mailing list > Bloat@lists.bufferbloat.net > https://lists.bufferbloat.net/listinfo/bloat ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-12-01 18:43 ` Dave Taht @ 2017-12-01 18:57 ` Luca Muscariello 2017-12-01 19:36 ` Dave Taht 0 siblings, 1 reply; 76+ messages in thread From: Luca Muscariello @ 2017-12-01 18:57 UTC (permalink / raw) To: Dave Taht; +Cc: Sebastian Moeller, bloat [-- Attachment #1: Type: text/plain, Size: 4144 bytes --] https://www.cisco.com/c/en/us/products/collateral/wireless/aironet-3700-series/white-paper-c11-735947.html On Fri 1 Dec 2017 at 19:43, Dave Taht <dave@taht.net> wrote: > Luca Muscariello <luca.muscariello@gmail.com> writes: > > > For highly asymmetric links, but also shared media like wifi, QUIC might > be a > > better playground for optimisations. > > Not pervasive as TCP though and maybe off topic in this thread. > > I happen to really like QUIC, but a netperf-style tool did not exist for > it when I last looked, last year. > > Also getting to emulating DASH traffic is on my list. > > > > > If the downlink is what one want to optimise, using FEC in the > downstream, in > > conjunction with flow control could be very effective. > > No need to send ACK frequently and having something like FQ_codel in the > > downstream would avoid fairness problems that might > > happen though. I don't know if FEC is still in QUIC and used. > > > > BTW, for wifi, the ACK stream can be compressed in aggregate of frames > and sent > > in bursts. This is similar to DOCSIS upstream. > > I wonder if this is a phenomenon that is visible in recent WiFi or just > > negligible. > > My guess is meraki deployed something and I think they are in in the top > 5 in the enterprise market. > > I see ubnt added airtime fairness (of some sort), recently. > > > > > On Fri, Dec 1, 2017 at 9:45 AM, Sebastian Moeller <moeller0@gmx.de> > wrote: > > > > Hi All, > > > > you do realize that the worst case is going to stay at 35KPPS? If we > assume > > simply that the 100Mbps download rate is not created by a single > flow but by > > many flows (say 70K flows) the discussed ACK frequency reduction > schemes > > will not work that well. So ACK thinning is a nice optimization, but > will > > not help the fact that some ISPs/link technologies simply are > asymmetric and > > the user will suffer under some traffic conditions. Now the 70K flow > example > > is too extreme, but the fact is at hight flow number with sparse > flows (so > > fewer ACKs per flow in the queue and fewer ACKs per flow reaching > the end > > NIC in a GRO-collection interval (I naively assume there is a > somewhat fixed > > but small interval in which packets of the same flow are collected > for GRO)) > > there will be problems. (Again, I am all for allowing the end user to > > configure ACK filtering thinning, but I would rather see ISPs sell > less > > imbalanced links ;) ) > > > > Best Regards > > Sebastian > > > > > > > > > On Dec 1, 2017, at 01:28, David Lang <david@lang.hm> wrote: > > > > > > 35K PPS of acks is insane, one ack every ms is FAR more than > enough to do > > 'fast recovery', and outside the datacenter, one ack per 10ms is > probably > > more than enough. > > > > > > Assuming something that's not too assymetric, thinning out the > acks may > > not make any difference in the transfer rate of a single data flow > in one > > direction, but if you step back and realize that there may be a need > to > > transfer data in the other direction, things change here. > > > > > > If you have a fully symmetrical link, and are maxing it out in both > > direction, going from 35K PPs of aks competing with data packets and > gonig > > down to 1k PPS or 100 PPS (or 10 PPS) would result in a noticable > > improvement in the flow that the acks are competing against. > > > > > > Stop thinking in terms of single-flow benchmarks and near idle > 'upstream' > > paths. > > > > > > David Lang > > > _______________________________________________ > > > Bloat mailing list > > > Bloat@lists.bufferbloat.net > > > https://lists.bufferbloat.net/listinfo/bloat > > > > _______________________________________________ > > Bloat mailing list > > Bloat@lists.bufferbloat.net > > https://lists.bufferbloat.net/listinfo/bloat > > > > > > > > _______________________________________________ > > Bloat mailing list > > Bloat@lists.bufferbloat.net > > https://lists.bufferbloat.net/listinfo/bloat > [-- Attachment #2: Type: text/html, Size: 5843 bytes --] ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-12-01 18:57 ` Luca Muscariello @ 2017-12-01 19:36 ` Dave Taht 0 siblings, 0 replies; 76+ messages in thread From: Dave Taht @ 2017-12-01 19:36 UTC (permalink / raw) To: Luca Muscariello; +Cc: Dave Taht, bloat On Fri, Dec 1, 2017 at 10:57 AM, Luca Muscariello <luca.muscariello@gmail.com> wrote: > https://www.cisco.com/c/en/us/products/collateral/wireless/aironet-3700-series/white-paper-c11-735947.html > Good news all over. I wonder what happens on cisco against the suite of tests toke made available here: https://www.cs.kau.se/tohojo/airtime-fairness/ People are getting some good results with this stuff: https://forum.lede-project.org/t/ubiquiti-unifi-ac-mesh/4499/4 (however, I currently have 6 bricked ones that I need to recover, and am having way more fun in simulation that I imagined I could ever have).... > On Fri 1 Dec 2017 at 19:43, Dave Taht <dave@taht.net> wrote: >> >> Luca Muscariello <luca.muscariello@gmail.com> writes: >> >> > For highly asymmetric links, but also shared media like wifi, QUIC might >> > be a >> > better playground for optimisations. >> > Not pervasive as TCP though and maybe off topic in this thread. >> >> I happen to really like QUIC, but a netperf-style tool did not exist for >> it when I last looked, last year. >> >> Also getting to emulating DASH traffic is on my list. >> >> > >> > If the downlink is what one want to optimise, using FEC in the >> > downstream, in >> > conjunction with flow control could be very effective. >> > No need to send ACK frequently and having something like FQ_codel in the >> > downstream would avoid fairness problems that might >> > happen though. I don't know if FEC is still in QUIC and used. >> > >> > BTW, for wifi, the ACK stream can be compressed in aggregate of frames >> > and sent >> > in bursts. This is similar to DOCSIS upstream. >> > I wonder if this is a phenomenon that is visible in recent WiFi or just >> > negligible. >> >> My guess is meraki deployed something and I think they are in in the top >> 5 in the enterprise market. >> >> I see ubnt added airtime fairness (of some sort), recently. >> >> > >> > On Fri, Dec 1, 2017 at 9:45 AM, Sebastian Moeller <moeller0@gmx.de> >> > wrote: >> > >> > Hi All, >> > >> > you do realize that the worst case is going to stay at 35KPPS? If we >> > assume >> > simply that the 100Mbps download rate is not created by a single >> > flow but by >> > many flows (say 70K flows) the discussed ACK frequency reduction >> > schemes >> > will not work that well. So ACK thinning is a nice optimization, but >> > will >> > not help the fact that some ISPs/link technologies simply are >> > asymmetric and >> > the user will suffer under some traffic conditions. Now the 70K flow >> > example >> > is too extreme, but the fact is at hight flow number with sparse >> > flows (so >> > fewer ACKs per flow in the queue and fewer ACKs per flow reaching >> > the end >> > NIC in a GRO-collection interval (I naively assume there is a >> > somewhat fixed >> > but small interval in which packets of the same flow are collected >> > for GRO)) >> > there will be problems. (Again, I am all for allowing the end user >> > to >> > configure ACK filtering thinning, but I would rather see ISPs sell >> > less >> > imbalanced links ;) ) >> > >> > Best Regards >> > Sebastian >> > >> > >> > >> > > On Dec 1, 2017, at 01:28, David Lang <david@lang.hm> wrote: >> > > >> > > 35K PPS of acks is insane, one ack every ms is FAR more than >> > enough to do >> > 'fast recovery', and outside the datacenter, one ack per 10ms is >> > probably >> > more than enough. >> > > >> > > Assuming something that's not too assymetric, thinning out the >> > acks may >> > not make any difference in the transfer rate of a single data flow >> > in one >> > direction, but if you step back and realize that there may be a need >> > to >> > transfer data in the other direction, things change here. >> > > >> > > If you have a fully symmetrical link, and are maxing it out in >> > both >> > direction, going from 35K PPs of aks competing with data packets and >> > gonig >> > down to 1k PPS or 100 PPS (or 10 PPS) would result in a noticable >> > improvement in the flow that the acks are competing against. >> > > >> > > Stop thinking in terms of single-flow benchmarks and near idle >> > 'upstream' >> > paths. >> > > >> > > David Lang >> > > _______________________________________________ >> > > Bloat mailing list >> > > Bloat@lists.bufferbloat.net >> > > https://lists.bufferbloat.net/listinfo/bloat >> > >> > _______________________________________________ >> > Bloat mailing list >> > Bloat@lists.bufferbloat.net >> > https://lists.bufferbloat.net/listinfo/bloat >> > >> > >> > >> > _______________________________________________ >> > Bloat mailing list >> > Bloat@lists.bufferbloat.net >> > https://lists.bufferbloat.net/listinfo/bloat > > > _______________________________________________ > Bloat mailing list > Bloat@lists.bufferbloat.net > https://lists.bufferbloat.net/listinfo/bloat > -- Dave Täht CEO, TekLibre, LLC http://www.teklibre.com Tel: 1-669-226-2619 ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-11-30 10:24 ` Eric Dumazet 2017-11-30 13:04 ` Mikael Abrahamsson @ 2017-11-30 14:51 ` Neal Cardwell 2017-11-30 15:55 ` Eric Dumazet 1 sibling, 1 reply; 76+ messages in thread From: Neal Cardwell @ 2017-11-30 14:51 UTC (permalink / raw) To: Eric Dumazet Cc: Jonathan Morton, Michael Welzl, David Ros, bloat, Yuchung Cheng, Wei Wang [-- Attachment #1: Type: text/plain, Size: 3786 bytes --] On Thu, Nov 30, 2017 at 5:24 AM, Eric Dumazet <eric.dumazet@gmail.com> wrote: > I agree that TCP itself should generate ACK smarter, on receivers that > are lacking GRO. (TCP sends at most one ACK per GRO packets, that is > why we did not feel an urgent need for better ACK generation) > > It is actually difficult task, because it might need an additional > timer, and we were reluctant adding extra complexity for that. > How about just using the existing delayed ACK timer, and just making the delayed ACK logic a bit smarter? We could try using the existing logic and timers, but using something adaptive instead of the magic "2" MSS received to force an ACK. > An additional point where huge gains are possible is to add TSO > autodefer while in recovery. Lacking TSO auto defer explains why TCP > flows enter a degenerated behavior, re-sending 1-MSS packets in > response to SACK flood. > Yes, agreed. I suspect there is some simple heuristic that could be implemented to allow TSO deferral for most packets sent in recovery. For example, allowing TSO deferral once the number of packet bursts (TSO skbs) sent in recovery is greater than some threshold. Perhaps TSO deferral would be fine in Recovery if we have sent, say, 10 skbs, because at that point if the ACK stream from the original flight dries up due to massive/tail loss, we have probably sent enough data in the new flight in Recovery to ensure some kind of ACKs come back to keep the ACK clock going. neal > > > On Thu, 2017-11-30 at 09:48 +0200, Jonathan Morton wrote: > > I do see your arguments. Let it be known that I didn't initiate the > > ack-filter in Cake, though it does seem to work quite well. > > With respect to BBR, I don't think it depends strongly on the return > > rate of acks in themselves, but rather on the rate of sequence number > > advance that they indicate. For this purpose, having the receiver > > emit sparser but still regularly spaced acks would be better than > > having some middlebox delete some less-predictable subset of them. > > So I think BBR could be a good testbed for AckCC implementation, > > especially as it is inherently paced and thus doesn't suffer from > > burstiness as a conventional ack-clocked TCP might. > > The real trouble with AckCC is that it requires implementation on the > > client as well as the server. That's most likely why Google hasn't > > tried it yet; there are no receivers in the wild that would give them > > valid data on its effectiveness. Adding support in Linux would help > > here, but aside from Android devices, Linux is only a relatively > > small proportion of Google's client traffic - and Android devices are > > slow to pick up new kernel features if they can't immediately turn it > > into a consumer-friendly bullet point. > > Meanwhile we have highly asymmetric last-mile links (10:1 is typical, > > 50:1 is occasionally seen), where a large fraction of upload > > bandwidth is occupied by acks in order to fully utilise the download > > bandwidth in TCP. Any concurrent upload flows have to compete with > > that dense ack flow, which in various schemes is unfair to either the > > upload or the download throughput. > > That is a problem as soon as you have multiple users on the same > > link, eg. a family household at the weekend. Thinning out those acks > > in response to uplink congestion is a solution. Maybe not the best > > possible solution, but a deployable one that works. > > - Jonathan Morton > > _______________________________________________ > > Bloat mailing list > > Bloat@lists.bufferbloat.net > > https://lists.bufferbloat.net/listinfo/bloat > _______________________________________________ > Bloat mailing list > Bloat@lists.bufferbloat.net > https://lists.bufferbloat.net/listinfo/bloat > [-- Attachment #2: Type: text/html, Size: 5100 bytes --] ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-11-30 14:51 ` Neal Cardwell @ 2017-11-30 15:55 ` Eric Dumazet 2017-11-30 15:57 ` Neal Cardwell 0 siblings, 1 reply; 76+ messages in thread From: Eric Dumazet @ 2017-11-30 15:55 UTC (permalink / raw) To: Neal Cardwell Cc: Jonathan Morton, Michael Welzl, David Ros, bloat, Yuchung Cheng, Wei Wang On Thu, 2017-11-30 at 09:51 -0500, Neal Cardwell wrote: > On Thu, Nov 30, 2017 at 5:24 AM, Eric Dumazet <eric.dumazet@gmail.com > > wrote: > > I agree that TCP itself should generate ACK smarter, on receivers > > that > > are lacking GRO. (TCP sends at most one ACK per GRO packets, that > > is > > why we did not feel an urgent need for better ACK generation) > > > > It is actually difficult task, because it might need an additional > > timer, and we were reluctant adding extra complexity for that. > > How about just using the existing delayed ACK timer, and just making > the delayed ACK logic a bit smarter? We could try using the existing > logic and timers, but using something adaptive instead of the magic > "2" MSS received to force an ACK. Keep in mind some distros have HZ=250 or even HZ=100 So even a 'one jiffie' timer could add 10ms delay. That is why I believe only a hrtimer could be used (and that would imply CONFIG_HIGH_RES_TIMERS=y ) I am waiting for Anna-Maria Gleixner work ( hrtimer: Provide softirq context hrtimers ) so that we can avoid a trip through a tasklet. > > > An additional point where huge gains are possible is to add TSO > > autodefer while in recovery. Lacking TSO auto defer explains why > > TCP > > flows enter a degenerated behavior, re-sending 1-MSS packets in > > response to SACK flood. > > Yes, agreed. I suspect there is some simple heuristic that could be > implemented to allow TSO deferral for most packets sent in recovery. > For example, allowing TSO deferral once the number of packet bursts > (TSO skbs) sent in recovery is greater than some threshold. Perhaps > TSO deferral would be fine in Recovery if we have sent, say, 10 skbs, > because at that point if the ACK stream from the original flight > dries up due to massive/tail loss, we have probably sent enough data > in the new flight in Recovery to ensure some kind of ACKs come back > to keep the ACK clock going. > > neal > > > > > On Thu, 2017-11-30 at 09:48 +0200, Jonathan Morton wrote: > > > I do see your arguments. Let it be known that I didn't initiate > > the > > > ack-filter in Cake, though it does seem to work quite well. > > > With respect to BBR, I don't think it depends strongly on the > > return > > > rate of acks in themselves, but rather on the rate of sequence > > number > > > advance that they indicate. For this purpose, having the > > receiver > > > emit sparser but still regularly spaced acks would be better than > > > having some middlebox delete some less-predictable subset of > > them. > > > So I think BBR could be a good testbed for AckCC implementation, > > > especially as it is inherently paced and thus doesn't suffer from > > > burstiness as a conventional ack-clocked TCP might. > > > The real trouble with AckCC is that it requires implementation on > > the > > > client as well as the server. That's most likely why Google > > hasn't > > > tried it yet; there are no receivers in the wild that would give > > them > > > valid data on its effectiveness. Adding support in Linux would > > help > > > here, but aside from Android devices, Linux is only a relatively > > > small proportion of Google's client traffic - and Android devices > > are > > > slow to pick up new kernel features if they can't immediately > > turn it > > > into a consumer-friendly bullet point. > > > Meanwhile we have highly asymmetric last-mile links (10:1 is > > typical, > > > 50:1 is occasionally seen), where a large fraction of upload > > > bandwidth is occupied by acks in order to fully utilise the > > download > > > bandwidth in TCP. Any concurrent upload flows have to compete > > with > > > that dense ack flow, which in various schemes is unfair to either > > the > > > upload or the download throughput. > > > That is a problem as soon as you have multiple users on the same > > > link, eg. a family household at the weekend. Thinning out those > > acks > > > in response to uplink congestion is a solution. Maybe not the > > best > > > possible solution, but a deployable one that works. > > > - Jonathan Morton > > > _______________________________________________ > > > Bloat mailing list > > > Bloat@lists.bufferbloat.net > > > https://lists.bufferbloat.net/listinfo/bloat > > _______________________________________________ > > Bloat mailing list > > Bloat@lists.bufferbloat.net > > https://lists.bufferbloat.net/listinfo/bloat > > > > ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-11-30 15:55 ` Eric Dumazet @ 2017-11-30 15:57 ` Neal Cardwell 0 siblings, 0 replies; 76+ messages in thread From: Neal Cardwell @ 2017-11-30 15:57 UTC (permalink / raw) To: Eric Dumazet Cc: Jonathan Morton, Michael Welzl, David Ros, bloat, Yuchung Cheng, Wei Wang [-- Attachment #1: Type: text/plain, Size: 1037 bytes --] On Thu, Nov 30, 2017 at 10:55 AM, Eric Dumazet <eric.dumazet@gmail.com> wrote: > On Thu, 2017-11-30 at 09:51 -0500, Neal Cardwell wrote: > > On Thu, Nov 30, 2017 at 5:24 AM, Eric Dumazet <eric.dumazet@gmail.com > > > wrote: > > > I agree that TCP itself should generate ACK smarter, on receivers > > > that > > > are lacking GRO. (TCP sends at most one ACK per GRO packets, that > > > is > > > why we did not feel an urgent need for better ACK generation) > > > > > > It is actually difficult task, because it might need an additional > > > timer, and we were reluctant adding extra complexity for that. > > > > How about just using the existing delayed ACK timer, and just making > > the delayed ACK logic a bit smarter? We could try using the existing > > logic and timers, but using something adaptive instead of the magic > > "2" MSS received to force an ACK. > > Keep in mind some distros have HZ=250 or even HZ=100 > > So even a 'one jiffie' timer could add 10ms delay. > Right, good point. I forgot about those cases. :-) neal [-- Attachment #2: Type: text/html, Size: 1631 bytes --] ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-11-29 12:49 ` Mikael Abrahamsson 2017-11-29 13:13 ` Luca Muscariello @ 2017-11-29 16:50 ` Sebastian Moeller 2017-12-12 19:27 ` Benjamin Cronce 1 sibling, 1 reply; 76+ messages in thread From: Sebastian Moeller @ 2017-11-29 16:50 UTC (permalink / raw) To: Mikael Abrahamsson; +Cc: Dave Täht, bloat Hi Mikael, > On Nov 29, 2017, at 13:49, Mikael Abrahamsson <swmike@swm.pp.se> wrote: > > On Wed, 29 Nov 2017, Sebastian Moeller wrote: > >> Well, ACK filtering/thinning is a simple trade-off: redundancy versus bandwidth. Since the RFCs say a receiver should acknoledge every second full MSS I think the decision whether to filter or not should be kept to > > Why does it say to do this? According to RFC 2525: "2.13. Name of Problem Stretch ACK violation Paxson, et. al. Informational [Page 40] RFC 2525 TCP Implementation Problems March 1999 Classification Congestion Control/Performance Description To improve efficiency (both computer and network) a data receiver may refrain from sending an ACK for each incoming segment, according to [ RFC1122 ]. However, an ACK should not be delayed an inordinate amount of time. Specifically, ACKs SHOULD be sent for every second full-sized segment that arrives. If a second full- sized segment does not arrive within a given timeout (of no more than 0.5 seconds), an ACK should be transmitted, according to [ RFC1122 ]. A TCP receiver which does not generate an ACK for every second full-sized segment exhibits a "Stretch ACK Violation". Significance TCP receivers exhibiting this behavior will cause TCP senders to generate burstier traffic, which can degrade performance in congested environments. In addition, generating fewer ACKs increases the amount of time needed by the slow start algorithm to open the congestion window to an appropriate point, which diminishes performance in environments with large bandwidth-delay products. Finally, generating fewer ACKs may cause needless retransmission timeouts in lossy environments, as it increases the possibility that an entire window of ACKs is lost, forcing a retransmission timeout. Implications When not in loss recovery, every ACK received by a TCP sender triggers the transmission of new data segments. The burst size is determined by the number of previously unacknowledged segments each ACK covers. Therefore, a TCP receiver ack'ing more than 2 segments at a time causes the sending TCP to generate a larger burst of traffic upon receipt of the ACK. This large burst of traffic can overwhelm an intervening gateway, leading to higher drop rates for both the connection and other connections passing through the congested gateway. In addition, the TCP slow start algorithm increases the congestion window by 1 segment for each ACK received. Therefore, increasing the ACK interval (thus decreasing the rate at which ACKs are transmitted) increases the amount of time it takes slow start to increase the congestion window to an appropriate operating point, and the connection consequently suffers from reduced performance. This is especially true for connections using large windows. Relevant RFCs RFC 1122 outlines delayed ACKs as a recommended mechanism. Paxson, et. al. Informational [Page 41] RFC 2525 TCP Implementation Problems March 1999 Trace file demonstrating it Trace file taken using tcpdump at host B, the data receiver (and ACK originator). The advertised window (which never changed) and timestamp options have been omitted for clarity, except for the first packet sent by A: 12:09:24.820187 A.1174 > B.3999: . 2049:3497(1448) ack 1 win 33580 <nop,nop,timestamp 2249877 2249914> [tos 0x8] 12:09:24.824147 A.1174 > B.3999: . 3497:4945(1448) ack 1 12:09:24.832034 A.1174 > B.3999: . 4945:6393(1448) ack 1 12:09:24.832222 B.3999 > A.1174: . ack 6393 12:09:24.934837 A.1174 > B.3999: . 6393:7841(1448) ack 1 12:09:24.942721 A.1174 > B.3999: . 7841:9289(1448) ack 1 12:09:24.950605 A.1174 > B.3999: . 9289:10737(1448) ack 1 12:09:24.950797 B.3999 > A.1174: . ack 10737 12:09:24.958488 A.1174 > B.3999: . 10737:12185(1448) ack 1 12:09:25.052330 A.1174 > B.3999: . 12185:13633(1448) ack 1 12:09:25.060216 A.1174 > B.3999: . 13633:15081(1448) ack 1 12:09:25.060405 B.3999 > A.1174: . ack 15081 This portion of the trace clearly shows that the receiver (host B) sends an ACK for every third full sized packet received. Further investigation of this implementation found that the cause of the increased ACK interval was the TCP options being used. The implementation sent an ACK after it was holding 2*MSS worth of unacknowledged data. In the above case, the MSS is 1460 bytes so the receiver transmits an ACK after it is holding at least 2920 bytes of unacknowledged data. However, the length of the TCP options being used [ RFC1323 ] took 12 bytes away from the data portion of each packet. This produced packets containing 1448 bytes of data. But the additional bytes used by the options in the header were not taken into account when determining when to trigger an ACK. Therefore, it took 3 data segments before the data receiver was holding enough unacknowledged data (>= 2*MSS, or 2920 bytes in the above example) to transmit an ACK. Trace file demonstrating correct behavior Trace file taken using tcpdump at host B, the data receiver (and ACK originator), again with window and timestamp information omitted except for the first packet: 12:06:53.627320 A.1172 > B.3999: . 1449:2897(1448) ack 1 win 33580 <nop,nop,timestamp 2249575 2249612> [tos 0x8] 12:06:53.634773 A.1172 > B.3999: . 2897:4345(1448) ack 1 12:06:53.634961 B.3999 > A.1172: . ack 4345 12:06:53.737326 A.1172 > B.3999: . 4345:5793(1448) ack 1 12:06:53.744401 A.1172 > B.3999: . 5793:7241(1448) ack 1 12:06:53.744592 B.3999 > A.1172: . ack 7241 Paxson, et. al. Informational [Page 42] RFC 2525 TCP Implementation Problems March 1999 12:06:53.752287 A.1172 > B.3999: . 7241:8689(1448) ack 1 12:06:53.847332 A.1172 > B.3999: . 8689:10137(1448) ack 1 12:06:53.847525 B.3999 > A.1172: . ack 10137 This trace shows the TCP receiver (host B) ack'ing every second full-sized packet, according to [ RFC1122 ]. This is the same implementation shown above, with slight modifications that allow the receiver to take the length of the options into account when deciding when to transmit an ACK." So I guess the point is that at the rates we are discussing (the the according short periods between non-filtered ACKs the time-out issue will be moot). The Slow start issue might also be moot if the sender does more than simple ACK counting. This leaves redundancy... The fact that GRO/GSO effectively lead to ack stretching already the disadvantages might not be as bad today (for high bandwidth flows) than they were in the past... > What benefit is there to either end system to send 35kPPS of ACKs in order to facilitate a 100 megabyte/s of TCP transfer? > > Sounds like a lot of useless interrupts and handling by the stack, apart from offloading it to the NIC to do a lot of handling of these mostly useless packets so the CPU doesn't have to do it. > > Why isn't 1kPPS of ACKs sufficient for most usecases? This is not going to fly, as far as I can tell the ACK rate needs to be high enough so that its inverse does not exceed the period that is equivalent to the calculated RTO, so the ACK rate needs to scale with the RTT of a connection. But I do not claim to be an expert here, I just had a look at some RFCs that might or might not be outdated already... Best Regards Sebastian > > -- > Mikael Abrahamsson email: swmike@swm.pp.se ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-11-29 16:50 ` Sebastian Moeller @ 2017-12-12 19:27 ` Benjamin Cronce 2017-12-12 20:04 ` Dave Taht ` (2 more replies) 0 siblings, 3 replies; 76+ messages in thread From: Benjamin Cronce @ 2017-12-12 19:27 UTC (permalink / raw) To: Sebastian Moeller; +Cc: Mikael Abrahamsson, bloat [-- Attachment #1: Type: text/plain, Size: 9994 bytes --] On Wed, Nov 29, 2017 at 10:50 AM, Sebastian Moeller <moeller0@gmx.de> wrote: > Hi Mikael, > > > > On Nov 29, 2017, at 13:49, Mikael Abrahamsson <swmike@swm.pp.se> wrote: > > > > On Wed, 29 Nov 2017, Sebastian Moeller wrote: > > > >> Well, ACK filtering/thinning is a simple trade-off: redundancy versus > bandwidth. Since the RFCs say a receiver should acknoledge every second > full MSS I think the decision whether to filter or not should be kept to > > > > Why does it say to do this? > > According to RFC 2525: > "2.13. > > Name of Problem > Stretch ACK violation > > > > > Paxson, et. al. Informational [Page 40] > > RFC 2525 TCP Implementation Problems March 1999 > > > > Classification > Congestion Control/Performance > > Description > To improve efficiency (both computer and network) a data receiver > may refrain from sending an ACK for each incoming segment, > according to [ > RFC1122 > ]. However, an ACK should not be delayed an > inordinate amount of time. Specifically, ACKs SHOULD be sent for > every second full-sized segment that arrives. If a second full- > sized segment does not arrive within a given timeout (of no more > than 0.5 seconds), an ACK should be transmitted, according to > [ > RFC1122 > ]. A TCP receiver which does not generate an ACK for > every second full-sized segment exhibits a "Stretch ACK > Violation". > > Significance > TCP receivers exhibiting this behavior will cause TCP senders to > generate burstier traffic, which can degrade performance in > congested environments. In addition, generating fewer ACKs > increases the amount of time needed by the slow start algorithm to > open the congestion window to an appropriate point, which > diminishes performance in environments with large bandwidth-delay > products. Finally, generating fewer ACKs may cause needless > retransmission timeouts in lossy environments, as it increases the > possibility that an entire window of ACKs is lost, forcing a > retransmission timeout. > It is interesting that enough of an issue occurred for them to explicitly state that at least 1 ACK per 2 segments as an RFC. That being said, all rules are meant to be broken, but not taken lightly when breaking. In highly asymmetric connections with large bufferbloat, the sender is either theoretically or practically of sending ACKs fast enough due to lack of bandwidth, results in ACKs becoming highly delayed, which, in my opinion, is worse. If the recover cannot ACK the receiver data within ~1.5 seconds, the sender will resend the missing segments. In my experience, I have seen upwards of 50% dup packet rates even though the actual loss rate was less than 1%. I do not feel that thinning ACKs gains much for any healthy ratio of down:up. The overhead of those "wasteful" ACKs are on par with the overhead of IP+TCP headers. Anything that can disturb the health of the Internet should make strong measures to prevent the end user from configuring the shaper in a knowingly destructive way. Like possibly letting the end user configure the amount of bandwidth ACKs get. I see many saying 35k pps is ridiculous, but that's pittance. If someone's network can't handle that, maybe they need a special TCP proxy. Thinning ACKs to help with bufferbloat is one thing, thinning ACKs because we feel TCP is too aggressive, is a can of worms. Research on the topic is still appreciated, but we should be careful about how much functionality Cake will have. > > Implications > When not in loss recovery, every ACK received by a TCP sender > triggers the transmission of new data segments. The burst size is > determined by the number of previously unacknowledged segments > each ACK covers. Therefore, a TCP receiver ack'ing more than 2 > segments at a time causes the sending TCP to generate a larger > burst of traffic upon receipt of the ACK. This large burst of > traffic can overwhelm an intervening gateway, leading to higher > drop rates for both the connection and other connections passing > through the congested gateway. > > In addition, the TCP slow start algorithm increases the congestion > window by 1 segment for each ACK received. Therefore, increasing > the ACK interval (thus decreasing the rate at which ACKs are > transmitted) increases the amount of time it takes slow start to > increase the congestion window to an appropriate operating point, > and the connection consequently suffers from reduced performance. > This is especially true for connections using large windows. > > Relevant RFCs > > RFC 1122 > outlines delayed ACKs as a recommended mechanism. > > > > > Paxson, et. al. Informational [Page 41] > > RFC 2525 TCP Implementation Problems March 1999 > > > > Trace file demonstrating it > Trace file taken using tcpdump at host B, the data receiver (and > ACK originator). The advertised window (which never changed) and > timestamp options have been omitted for clarity, except for the > first packet sent by A: > > 12:09:24.820187 A.1174 > B.3999: . 2049:3497(1448) ack 1 > win 33580 <nop,nop,timestamp 2249877 2249914> [tos 0x8] > 12:09:24.824147 A.1174 > B.3999: . 3497:4945(1448) ack 1 > 12:09:24.832034 A.1174 > B.3999: . 4945:6393(1448) ack 1 > 12:09:24.832222 B.3999 > A.1174: . ack 6393 > 12:09:24.934837 A.1174 > B.3999: . 6393:7841(1448) ack 1 > 12:09:24.942721 A.1174 > B.3999: . 7841:9289(1448) ack 1 > 12:09:24.950605 A.1174 > B.3999: . 9289:10737(1448) ack 1 > 12:09:24.950797 B.3999 > A.1174: . ack 10737 > 12:09:24.958488 A.1174 > B.3999: . 10737:12185(1448) ack 1 > 12:09:25.052330 A.1174 > B.3999: . 12185:13633(1448) ack 1 > 12:09:25.060216 A.1174 > B.3999: . 13633:15081(1448) ack 1 > 12:09:25.060405 B.3999 > A.1174: . ack 15081 > > This portion of the trace clearly shows that the receiver (host B) > sends an ACK for every third full sized packet received. Further > investigation of this implementation found that the cause of the > increased ACK interval was the TCP options being used. The > implementation sent an ACK after it was holding 2*MSS worth of > unacknowledged data. In the above case, the MSS is 1460 bytes so > the receiver transmits an ACK after it is holding at least 2920 > bytes of unacknowledged data. However, the length of the TCP > options being used [ > RFC1323 > ] took 12 bytes away from the data > portion of each packet. This produced packets containing 1448 > bytes of data. But the additional bytes used by the options in > the header were not taken into account when determining when to > trigger an ACK. Therefore, it took 3 data segments before the > data receiver was holding enough unacknowledged data (>= 2*MSS, or > 2920 bytes in the above example) to transmit an ACK. > > Trace file demonstrating correct behavior > Trace file taken using tcpdump at host B, the data receiver (and > ACK originator), again with window and timestamp information > omitted except for the first packet: > > 12:06:53.627320 A.1172 > B.3999: . 1449:2897(1448) ack 1 > win 33580 <nop,nop,timestamp 2249575 2249612> [tos 0x8] > 12:06:53.634773 A.1172 > B.3999: . 2897:4345(1448) ack 1 > 12:06:53.634961 B.3999 > A.1172: . ack 4345 > 12:06:53.737326 A.1172 > B.3999: . 4345:5793(1448) ack 1 > 12:06:53.744401 A.1172 > B.3999: . 5793:7241(1448) ack 1 > 12:06:53.744592 B.3999 > A.1172: . ack 7241 > > > > > Paxson, et. al. Informational [Page 42] > > RFC 2525 TCP Implementation Problems March 1999 > > > > 12:06:53.752287 A.1172 > B.3999: . 7241:8689(1448) ack 1 > 12:06:53.847332 A.1172 > B.3999: . 8689:10137(1448) ack 1 > 12:06:53.847525 B.3999 > A.1172: . ack 10137 > > This trace shows the TCP receiver (host B) ack'ing every second > full-sized packet, according to [ > RFC1122 > ]. This is the same > implementation shown above, with slight modifications that allow > the receiver to take the length of the options into account when > deciding when to transmit an ACK." > > So I guess the point is that at the rates we are discussing (the the > according short periods between non-filtered ACKs the time-out issue will > be moot). The Slow start issue might also be moot if the sender does more > than simple ACK counting. This leaves redundancy... The fact that GRO/GSO > effectively lead to ack stretching already the disadvantages might not be > as bad today (for high bandwidth flows) than they were in the past... > > > > What benefit is there to either end system to send 35kPPS of ACKs in > order to facilitate a 100 megabyte/s of TCP transfer? > > > > > Sounds like a lot of useless interrupts and handling by the stack, apart > from offloading it to the NIC to do a lot of handling of these mostly > useless packets so the CPU doesn't have to do it. > > > > Why isn't 1kPPS of ACKs sufficient for most usecases? > > This is not going to fly, as far as I can tell the ACK rate needs > to be high enough so that its inverse does not exceed the period that is > equivalent to the calculated RTO, so the ACK rate needs to scale with the > RTT of a connection. > > But I do not claim to be an expert here, I just had a look at some RFCs > that might or might not be outdated already... > > Best Regards > Sebastian > > > > > > -- > > Mikael Abrahamsson email: swmike@swm.pp.se > > _______________________________________________ > Bloat mailing list > Bloat@lists.bufferbloat.net > https://lists.bufferbloat.net/listinfo/bloat > [-- Attachment #2: Type: text/html, Size: 12149 bytes --] ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-12-12 19:27 ` Benjamin Cronce @ 2017-12-12 20:04 ` Dave Taht 2017-12-12 21:03 ` David Lang 2017-12-12 22:03 ` Jonathan Morton 2 siblings, 0 replies; 76+ messages in thread From: Dave Taht @ 2017-12-12 20:04 UTC (permalink / raw) To: Benjamin Cronce; +Cc: Sebastian Moeller, bloat What kicked off this thread was my urge to get a little code review of https://github.com/dtaht/sch_cake/blob/cobalt/sch_cake.c#L904 because it seems to work well in a variety of tests, and ever better as your D/U ratio cracks 10/1. There are a few things I don't like about the implementation: 0) It's cpu intensive. Not as bad as hashing three times, as cake, can, but intensive. 1) It reparses the whole queue looking for further acks to take out. This makes sense were this to be applied to a single fifo, but in cake's 1024 queue set associative case, leveraging something like oldskb->isack && oldskb->hash == skb->hash on the five tuple would be faster. 2) stopping entirely on a ack-filterable miss, and just working on replacing the last packet on the tail of the queue, is far more O(1). (I'd kind of like a "ackstate" machine, perhaps added to the cb) 3) I already made an attempt to deprioritize bulk ack flows slightly. 4) How much parsing of sack is really necessary? 5) I'm a little unsure as to the right things to do for ECN-echo. 1 ECN-echo packet should always be sent... That all said, the results are fascinating, and I can live with all these issues for a first release in sch_cake to more people in the lede project... and plan on trying to pull this functionality out more generally over the next month or three - primarily as impairments to netem. On Tue, Dec 12, 2017 at 11:27 AM, Benjamin Cronce <bcronce@gmail.com> wrote: > > > On Wed, Nov 29, 2017 at 10:50 AM, Sebastian Moeller <moeller0@gmx.de> wrote: >> >> Hi Mikael, >> >> >> > On Nov 29, 2017, at 13:49, Mikael Abrahamsson <swmike@swm.pp.se> wrote: >> > >> > On Wed, 29 Nov 2017, Sebastian Moeller wrote: >> > >> >> Well, ACK filtering/thinning is a simple trade-off: redundancy versus >> >> bandwidth. Since the RFCs say a receiver should acknoledge every second full >> >> MSS I think the decision whether to filter or not should be kept to >> > >> > Why does it say to do this? >> >> According to RFC 2525: >> "2.13. >> >> Name of Problem >> Stretch ACK violation >> >> >> >> >> Paxson, et. al. Informational [Page 40] >> >> RFC 2525 TCP Implementation Problems March 1999 >> >> >> >> Classification >> Congestion Control/Performance >> >> Description >> To improve efficiency (both computer and network) a data receiver >> may refrain from sending an ACK for each incoming segment, >> according to [ >> RFC1122 >> ]. However, an ACK should not be delayed an >> inordinate amount of time. Specifically, ACKs SHOULD be sent for >> every second full-sized segment that arrives. If a second full- >> sized segment does not arrive within a given timeout (of no more >> than 0.5 seconds), an ACK should be transmitted, according to >> [ >> RFC1122 >> ]. A TCP receiver which does not generate an ACK for >> every second full-sized segment exhibits a "Stretch ACK >> Violation". >> >> Significance >> TCP receivers exhibiting this behavior will cause TCP senders to >> generate burstier traffic, which can degrade performance in >> congested environments. In addition, generating fewer ACKs >> increases the amount of time needed by the slow start algorithm to >> open the congestion window to an appropriate point, which >> diminishes performance in environments with large bandwidth-delay >> products. Finally, generating fewer ACKs may cause needless >> retransmission timeouts in lossy environments, as it increases the >> possibility that an entire window of ACKs is lost, forcing a >> retransmission timeout. > > > It is interesting that enough of an issue occurred for them to explicitly > state that at least 1 ACK per 2 segments as an RFC. That being said, all > rules are meant to be broken, but not taken lightly when breaking. In highly > asymmetric connections with large bufferbloat, the sender is either > theoretically or practically of sending ACKs fast enough due to lack of > bandwidth, results in ACKs becoming highly delayed, which, in my opinion, is > worse. If the recover cannot ACK the receiver data within ~1.5 seconds, the > sender will resend the missing segments. In my experience, I have seen > upwards of 50% dup packet rates even though the actual loss rate was less > than 1%. I too have seen some insane dup packet rates also, but that's a failure on the input side mostly. > > I do not feel that thinning ACKs gains much for any healthy ratio of > down:up. Define "healthy". > The overhead of those "wasteful" ACKs are on par with the overhead > of IP+TCP headers. Anything that can disturb the health of the Internet > should make strong measures to prevent the end user from configuring the > shaper in a knowingly destructive way. Like possibly letting the end user > configure the amount of bandwidth ACKs get. I see many saying 35k pps is > ridiculous, but that's pittance. I tend to agree that for longer RTTs (and in the context of a clean sheet design for TCP!) more than one ack per ms is excessive - more broadly, per TXOP, in the case of wifi in its presently overly-reliable mac retransmission layer. I sometimes wish we had a substrate for "I'm going to send 17 packets total on this flow, tell me if you got 'em", rather than the ack clock. > If someone's network can't handle that, > maybe they need a special TCP proxy. Thinning ACKs to help with bufferbloat > is one thing, I wouldn't quite define it that way. Thinning acks to make room for non-acks in an already debloated environment or "applying a congestion control algorithm that applies specifically to acks". The blog posting and graph here showed how slow codel was at clearing room here: http://blog.cerowrt.org/post/ack_filtering/ > thinning ACKs because we feel TCP is too aggressive, is a can > of worms. Research on the topic is still appreciated, but we should be > careful about how much functionality Cake will have. good point. Despite deployment in a few places like riverbed and ubnt and lede, sch_cake has not achieved particularly high penetration elsewhere. It's still kind of a convenient research vehicle, but I dearly wish the things I love about it (the deficit scheduler, the per host fq stuff) had more users. >> >> >> Implications >> When not in loss recovery, every ACK received by a TCP sender >> triggers the transmission of new data segments. The burst size is >> determined by the number of previously unacknowledged segments >> each ACK covers. Therefore, a TCP receiver ack'ing more than 2 >> segments at a time causes the sending TCP to generate a larger >> burst of traffic upon receipt of the ACK. This large burst of >> traffic can overwhelm an intervening gateway, leading to higher >> drop rates for both the connection and other connections passing >> through the congested gateway. This is no longer true in the case of pacing. >> In addition, the TCP slow start algorithm increases the congestion >> window by 1 segment for each ACK received. Therefore, increasing >> the ACK interval (thus decreasing the rate at which ACKs are >> transmitted) increases the amount of time it takes slow start to >> increase the congestion window to an appropriate operating point, >> and the connection consequently suffers from reduced performance. >> This is especially true for connections using large windows. >> >> Relevant RFCs >> >> RFC 1122 >> outlines delayed ACKs as a recommended mechanism. >> >> >> >> >> Paxson, et. al. Informational [Page 41] >> >> RFC 2525 TCP Implementation Problems March 1999 >> >> >> >> Trace file demonstrating it >> Trace file taken using tcpdump at host B, the data receiver (and >> ACK originator). The advertised window (which never changed) and >> timestamp options have been omitted for clarity, except for the >> first packet sent by A: >> >> 12:09:24.820187 A.1174 > B.3999: . 2049:3497(1448) ack 1 >> win 33580 <nop,nop,timestamp 2249877 2249914> [tos 0x8] >> 12:09:24.824147 A.1174 > B.3999: . 3497:4945(1448) ack 1 >> 12:09:24.832034 A.1174 > B.3999: . 4945:6393(1448) ack 1 >> 12:09:24.832222 B.3999 > A.1174: . ack 6393 >> 12:09:24.934837 A.1174 > B.3999: . 6393:7841(1448) ack 1 >> 12:09:24.942721 A.1174 > B.3999: . 7841:9289(1448) ack 1 >> 12:09:24.950605 A.1174 > B.3999: . 9289:10737(1448) ack 1 >> 12:09:24.950797 B.3999 > A.1174: . ack 10737 >> 12:09:24.958488 A.1174 > B.3999: . 10737:12185(1448) ack 1 >> 12:09:25.052330 A.1174 > B.3999: . 12185:13633(1448) ack 1 >> 12:09:25.060216 A.1174 > B.3999: . 13633:15081(1448) ack 1 >> 12:09:25.060405 B.3999 > A.1174: . ack 15081 >> >> This portion of the trace clearly shows that the receiver (host B) >> sends an ACK for every third full sized packet received. Further >> investigation of this implementation found that the cause of the >> increased ACK interval was the TCP options being used. The >> implementation sent an ACK after it was holding 2*MSS worth of >> unacknowledged data. In the above case, the MSS is 1460 bytes so >> the receiver transmits an ACK after it is holding at least 2920 >> bytes of unacknowledged data. However, the length of the TCP >> options being used [ >> RFC1323 >> ] took 12 bytes away from the data >> portion of each packet. This produced packets containing 1448 >> bytes of data. But the additional bytes used by the options in >> the header were not taken into account when determining when to >> trigger an ACK. Therefore, it took 3 data segments before the >> data receiver was holding enough unacknowledged data (>= 2*MSS, or >> 2920 bytes in the above example) to transmit an ACK. >> >> Trace file demonstrating correct behavior >> Trace file taken using tcpdump at host B, the data receiver (and >> ACK originator), again with window and timestamp information >> omitted except for the first packet: >> >> 12:06:53.627320 A.1172 > B.3999: . 1449:2897(1448) ack 1 >> win 33580 <nop,nop,timestamp 2249575 2249612> [tos 0x8] >> 12:06:53.634773 A.1172 > B.3999: . 2897:4345(1448) ack 1 >> 12:06:53.634961 B.3999 > A.1172: . ack 4345 >> 12:06:53.737326 A.1172 > B.3999: . 4345:5793(1448) ack 1 >> 12:06:53.744401 A.1172 > B.3999: . 5793:7241(1448) ack 1 >> 12:06:53.744592 B.3999 > A.1172: . ack 7241 >> >> >> >> >> Paxson, et. al. Informational [Page 42] >> >> RFC 2525 TCP Implementation Problems March 1999 >> >> >> >> 12:06:53.752287 A.1172 > B.3999: . 7241:8689(1448) ack 1 >> 12:06:53.847332 A.1172 > B.3999: . 8689:10137(1448) ack 1 >> 12:06:53.847525 B.3999 > A.1172: . ack 10137 >> >> This trace shows the TCP receiver (host B) ack'ing every second >> full-sized packet, according to [ >> RFC1122 >> ]. This is the same >> implementation shown above, with slight modifications that allow >> the receiver to take the length of the options into account when >> deciding when to transmit an ACK." >> >> So I guess the point is that at the rates we are discussing (the the >> according short periods between non-filtered ACKs the time-out issue will be >> moot). The Slow start issue might also be moot if the sender does more than >> simple ACK counting. This leaves redundancy... The fact that GRO/GSO >> effectively lead to ack stretching already the disadvantages might not be as >> bad today (for high bandwidth flows) than they were in the past... >> >> >> > What benefit is there to either end system to send 35kPPS of ACKs in >> > order to facilitate a 100 megabyte/s of TCP transfer? >> >> > >> > Sounds like a lot of useless interrupts and handling by the stack, apart >> > from offloading it to the NIC to do a lot of handling of these mostly >> > useless packets so the CPU doesn't have to do it. >> > >> > Why isn't 1kPPS of ACKs sufficient for most usecases? >> >> This is not going to fly, as far as I can tell the ACK rate needs >> to be high enough so that its inverse does not exceed the period that is >> equivalent to the calculated RTO, so the ACK rate needs to scale with the >> RTT of a connection. >> >> But I do not claim to be an expert here, I just had a look at some RFCs >> that might or might not be outdated already... >> >> Best Regards >> Sebastian >> >> >> > >> > -- >> > Mikael Abrahamsson email: swmike@swm.pp.se >> >> _______________________________________________ >> Bloat mailing list >> Bloat@lists.bufferbloat.net >> https://lists.bufferbloat.net/listinfo/bloat > > > > _______________________________________________ > Bloat mailing list > Bloat@lists.bufferbloat.net > https://lists.bufferbloat.net/listinfo/bloat > -- Dave Täht CEO, TekLibre, LLC http://www.teklibre.com Tel: 1-669-226-2619 ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-12-12 19:27 ` Benjamin Cronce 2017-12-12 20:04 ` Dave Taht @ 2017-12-12 21:03 ` David Lang 2017-12-12 21:29 ` Jonathan Morton 2017-12-12 22:03 ` Jonathan Morton 2 siblings, 1 reply; 76+ messages in thread From: David Lang @ 2017-12-12 21:03 UTC (permalink / raw) To: Benjamin Cronce; +Cc: Sebastian Moeller, bloat On Tue, 12 Dec 2017, Benjamin Cronce wrote: > I do not feel that thinning ACKs gains much for any healthy ratio of > down:up. The overhead of those "wasteful" ACKs are on par with the overhead > of IP+TCP headers. assuming that there was no traffic going the other way to compete with the acks. > Anything that can disturb the health of the Internet > should make strong measures to prevent the end user from configuring the > shaper in a knowingly destructive way. Like possibly letting the end user > configure the amount of bandwidth ACKs get. I see many saying 35k pps is > ridiculous, but that's pittance. If someone's network can't handle that, > maybe they need a special TCP proxy. Thinning ACKs to help with bufferbloat > is one thing, thinning ACKs because we feel TCP is too aggressive, is a can > of worms. Research on the topic is still appreciated, but we should be > careful about how much functionality Cake will have. Yes, research is needed, but we need to recognize that what was appropriate when 1Mb was a very fast link may not be appropriate when you are orders of magnatude faster, and where there can be significant amounts of traffic in the other direction. I think that TCP is pretty wasteful of bandwidth (and txops on wifi) under most conditions. Just chopping the number from 1/2 to 1/200 or something like that is obviously wrong, but I have a real hard time figuring out how collapsing acks that are sitting in a queue together into one ack will hurt. The acks that you are deleting are not going to get to the recipient any faster than the ack that you keep (at least if done correctly), so how can it make things better to delay acking data that you have received in order to send out many additional acks of parts of that data? David Lang ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-12-12 21:03 ` David Lang @ 2017-12-12 21:29 ` Jonathan Morton 0 siblings, 0 replies; 76+ messages in thread From: Jonathan Morton @ 2017-12-12 21:29 UTC (permalink / raw) To: David Lang; +Cc: Benjamin Cronce, bloat [-- Attachment #1: Type: text/plain, Size: 1304 bytes --] Taking into account a variety of scenarios, I have difficulty identifying a case where an ack deleted by a reasonably conservative algorithm would have given any practical benefit had it remained, *including* considerations of smoothness of ack-clocking. If the uplink isn't congested then no deletions occur; if it is congested then there's a high probability that a flow-isolation scheme would deliver several acks back to back between larger data packets, so an ack-clocked sender would still be "lumpy". That's without even considering aggregation and discrete MAC-grant links (ie. DOCSIS). Deleting unnecessary acks from a congested uplink also frees capacity for competing traffic, which I think we can agree is a good thing when it has no deleterous side-effects. I have not yet personally verified that the algorithm now in Cake matches my assumptions. If it doesn't, I'll push for modifications. Incidentally, I am of the opinion that ECE can safely be ignored for ack-filtering purposes. Normally ECE remains set in all acks until a CWR is heard in reply, so it only matters that the ECE signal isn't *delayed* - which ack-filtering actually helps to achieve. More sophisticated uses of ECE should also survive this as long as statistical independence is maintained. - Jonathan Morton [-- Attachment #2: Type: text/html, Size: 1452 bytes --] ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-12-12 19:27 ` Benjamin Cronce 2017-12-12 20:04 ` Dave Taht 2017-12-12 21:03 ` David Lang @ 2017-12-12 22:03 ` Jonathan Morton 2017-12-12 22:21 ` David Lang 2017-12-13 12:39 ` Luca Muscariello 2 siblings, 2 replies; 76+ messages in thread From: Jonathan Morton @ 2017-12-12 22:03 UTC (permalink / raw) To: Benjamin Cronce; +Cc: Sebastian Moeller, bloat [-- Attachment #1: Type: text/plain, Size: 642 bytes --] The one "correct" argument against ack-filtering I've seen is that it encourages (or rather validates) the use of extreme asymmetry ratios. However, these extreme ratios are already in widespread use without the aid of ack-filtering. Even ADSL2 Annex A has, as its "ideal" sync rate, a 16:1 ratio, which Annex M modifies to under 10:1. I fear we must conclude that technical considerations are not the driving factor here. A better place to sort out the asymmetry problem (as well as several other problems of current interest) would be in a free, competitive market. Sadly such a thing is rare in the telecoms sector. - Jonathan Morton [-- Attachment #2: Type: text/html, Size: 746 bytes --] ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-12-12 22:03 ` Jonathan Morton @ 2017-12-12 22:21 ` David Lang [not found] ` <CAJq5cE3nfSQP0GCLjp=X0T-iHHgAs=YUCcr34e3ARgkrGZe-wg@mail.gmail.com> 2017-12-13 12:39 ` Luca Muscariello 1 sibling, 1 reply; 76+ messages in thread From: David Lang @ 2017-12-12 22:21 UTC (permalink / raw) To: Jonathan Morton; +Cc: Benjamin Cronce, bloat On Wed, 13 Dec 2017, Jonathan Morton wrote: > The one "correct" argument against ack-filtering I've seen is that it > encourages (or rather validates) the use of extreme asymmetry ratios. I would sure rather have a extremely asymmetric ration than a 'proper' ratio with the same upstream bandwidth. I really doubt that choosing to badly support extreme ratios will stop or even slow down the deployment, and the technology continues to develop in ways that make such ratios more common (it's much easier to spend money on signal processing for a central box than for all the endpoint products) David Lang ^ permalink raw reply [flat|nested] 76+ messages in thread
[parent not found: <CAJq5cE3nfSQP0GCLjp=X0T-iHHgAs=YUCcr34e3ARgkrGZe-wg@mail.gmail.com>]
* Re: [Bloat] benefits of ack filtering [not found] ` <CAJq5cE3nfSQP0GCLjp=X0T-iHHgAs=YUCcr34e3ARgkrGZe-wg@mail.gmail.com> @ 2017-12-12 22:41 ` Jonathan Morton 2017-12-13 9:46 ` Mikael Abrahamsson 0 siblings, 1 reply; 76+ messages in thread From: Jonathan Morton @ 2017-12-12 22:41 UTC (permalink / raw) To: David Lang; +Cc: Benjamin Cronce, bloat [-- Attachment #1: Type: text/plain, Size: 1150 bytes --] Actually, the cost argument goes the other way. You need heavy DSP to *receive* high bandwidths; sending it is much easier computationally. Also, in aggregate a hundred cheap CPE boxes probably have more DSP horsepower than the one head-end box serving them. What the centralised head-end has an advantage in is transmit power, and thus SNR. This feeds into Shannon's equation and supports your argument more directly. In ADSL this is partly compensated for by assigning the lower frequency carriers to the upload direction, since they have less loss than high frequencies on a copper pair. However, in the most extreme examples I've seen, the level of asymmetry has little to do with the underlying link technology and more to do with how the provisioning was arbitrarily set up. Things like ADSL with an unrestricted downlink sync rate but uplink limited to 128k. Or DOCSIS with a huge headline bandwidth for downlink, and no obvious mention (until you've paid for it, set it up and measured it) that the uplink shaper is set to about a fiftieth of that. I seriously doubt that DOCSIS is ever inherently that asymmetric. - Jonathan Morton [-- Attachment #2: Type: text/html, Size: 1262 bytes --] ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-12-12 22:41 ` Jonathan Morton @ 2017-12-13 9:46 ` Mikael Abrahamsson 2017-12-13 10:03 ` Jonathan Morton 2017-12-13 12:36 ` Sebastian Moeller 0 siblings, 2 replies; 76+ messages in thread From: Mikael Abrahamsson @ 2017-12-13 9:46 UTC (permalink / raw) To: Jonathan Morton; +Cc: David Lang, bloat On Wed, 13 Dec 2017, Jonathan Morton wrote: > the uplink shaper is set to about a fiftieth of that. I seriously doubt > that DOCSIS is ever inherently that asymmetric. Well, the products are, because that's what the operators seems to want, probably also because that's what the customers demand. So my modem has 16x4 (16 downstream channels and 4 upstream channels), meaning built into the hardware, I have 1/4 split. Then providers typically (this is my understanding, I haven't worked professionally with DOCSIS networks) do is they have 24 downstream channels and 4 upstream channels. Older modems can have 8 downstream and 4 upstream for instance, so they'll "tune" to the amount of channels they can, and then there is an on-demand scheduler that handles upstream and downstream traffic. So I guess theoretically the operator could (if large enough) make a hw vendor create a 16x16 modem and have 32 channels total. But nobody does that, because that doesn't sell as well as having more downstream (because people don't seem to care about upstream). It just makes more market sense to sell these asymmetric services, because typically people are eyeballs and they don't need a lot of upstream bw (or think they need it). On the ADSL side, I have seen 28/3 (28 down, 3 up) for annex-M with proprietary extensions. The fastest symmetric I have seen is 4.6/4.6. So if you as an operator can choose between selling a 28/3 or 4.6/4.6 service, what will you do? To consumers, it's 28/3 all day. So people can blame the ISPs all day long, but there is still (as you stated) physical limitations on capacity on RF spectrum in air/copper, and you need to handle this reality somehow. If a lot of power is used upstream then you'll get worse SNR for the downstream, meaning less capacity overall. Symmetric access capacity costs real money and results in less overall capacity unless it's on point to point fiber. -- Mikael Abrahamsson email: swmike@swm.pp.se ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-12-13 9:46 ` Mikael Abrahamsson @ 2017-12-13 10:03 ` Jonathan Morton 2017-12-13 12:11 ` Sebastian Moeller 2017-12-13 12:36 ` Sebastian Moeller 1 sibling, 1 reply; 76+ messages in thread From: Jonathan Morton @ 2017-12-13 10:03 UTC (permalink / raw) To: Mikael Abrahamsson; +Cc: David Lang, bloat [-- Attachment #1: Type: text/plain, Size: 116 bytes --] Forgive my ignorance, but does each channel have the same capacity in both directions in DOCSIS? - Jonathan Morton [-- Attachment #2: Type: text/html, Size: 155 bytes --] ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-12-13 10:03 ` Jonathan Morton @ 2017-12-13 12:11 ` Sebastian Moeller 2017-12-13 12:18 ` Jonathan Morton 0 siblings, 1 reply; 76+ messages in thread From: Sebastian Moeller @ 2017-12-13 12:11 UTC (permalink / raw) To: Jonathan Morton; +Cc: Mikael Abrahamsson, bloat > On Dec 13, 2017, at 11:03, Jonathan Morton <chromatix99@gmail.com> wrote: > > Forgive my ignorance, but does each channel have the same capacity in both directions in DOCSIS? A quick look at https://en.wikipedia.org/wiki/DOCSIS seems to reveal that there typically is higher capacity for each downstream versus each upstream channel, at least downstream consistently seems to offer higher maximal modulations... Best Regards Sebastian > > - Jonathan Morton > _______________________________________________ > Bloat mailing list > Bloat@lists.bufferbloat.net > https://lists.bufferbloat.net/listinfo/bloat ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-12-13 12:11 ` Sebastian Moeller @ 2017-12-13 12:18 ` Jonathan Morton 0 siblings, 0 replies; 76+ messages in thread From: Jonathan Morton @ 2017-12-13 12:18 UTC (permalink / raw) To: Sebastian Moeller; +Cc: Mikael Abrahamsson, bloat [-- Attachment #1: Type: text/plain, Size: 273 bytes --] Okay, from the tables on that page, it seems that the most asymmetric maximal configuration is below 8:1. That's in line with what you'd expect given transmit power and thus SNR differences. Hence no legitimate reason to provision at 42:1 and above... - Jonathan Morton [-- Attachment #2: Type: text/html, Size: 341 bytes --] ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-12-13 9:46 ` Mikael Abrahamsson 2017-12-13 10:03 ` Jonathan Morton @ 2017-12-13 12:36 ` Sebastian Moeller 1 sibling, 0 replies; 76+ messages in thread From: Sebastian Moeller @ 2017-12-13 12:36 UTC (permalink / raw) To: Mikael Abrahamsson; +Cc: Jonathan Morton, bloat Hi Mikael, > On Dec 13, 2017, at 10:46, Mikael Abrahamsson <swmike@swm.pp.se> wrote: > > On Wed, 13 Dec 2017, Jonathan Morton wrote: > >> the uplink shaper is set to about a fiftieth of that. I seriously doubt that DOCSIS is ever inherently that asymmetric. > > Well, the products are, because that's what the operators seems to want, probably also because that's what the customers demand. Not 100% about the demand; I believe this also has a component of market segmentation: a) everybody that actually wants to offer content is going to be not to well-served with the asymmetric links and hence might need to upgrade to the typical business-grade contracts that AFAIKT often have smaller download/upload ratios. b) I seem to recall (but can find no evidence, so I might fantasizing) that having assymmetric traffic can have advantages for an ISP with peering/transit costs. > > So my modem has 16x4 (16 downstream channels and 4 upstream channels), meaning built into the hardware, I have 1/4 split. In addition to the differences in available modulations for down- and upstream channels. > > Then providers typically (this is my understanding, I haven't worked professionally with DOCSIS networks) do is they have 24 downstream channels and 4 upstream channels. Older modems can have 8 downstream and 4 upstream for instance, so they'll "tune" to the amount of channels they can, and then there is an on-demand scheduler that handles upstream and downstream traffic. > > So I guess theoretically the operator could (if large enough) make a hw vendor create a 16x16 modem and have 32 channels total. > But nobody does that, because that doesn't sell as well as having more downstream (because people don't seem to care about upstream). Or because more symmetric offers can be sold for more money to businesses (sure the "business" contract class probably offers more than that, but I think this is one thing it does offer). > It just makes more market sense to sell these asymmetric services, because typically people are eyeballs and they don't need a lot of upstream bw (or think they need it). Let's put it that way, people simply do not know as in the advertisements one typically only sees the downstream numbers with the upstream relegated to the footnotes (or hidden behind a link). If customers truly would not care ISPs could afford to be more open with the upstream numbers (something regulators would certainly prefer to hiding the information in the fine print). > > On the ADSL side, I have seen 28/3 (28 down, 3 up) for annex-M with proprietary extensions. The fastest symmetric I have seen is 4.6/4.6. So if you as an operator can choose between selling a 28/3 or 4.6/4.6 service, what will you do? To consumers, it's 28/3 all day. I agree that most users would see it that way (especially since 4.6 to 3 is not that much loss); also I b;eive it will be hard to offer simultaneous 23/3 and 4.6/4.6 over the same trunk line (not sure whether that is the correct word, I mean the thick copper cable "tree" that starts from the CO/gf-attached DSLAM). For ADSL the challenge is that the up-/downstrewam bands need to be equal for all users on a trunk cable other wise interference/cross talk will be bad; and the most remote customer will still need some downstream effectively limiting the high end for the single upstream band in ADSL. VDSL2 sidesteps this issue somewhat by using multiple upstream bands and more remote lines will simply miss out on the higher frequency upstream bands but will still get a better symmetry... > > So people can blame the ISPs all day long, but there is still (as you stated) physical limitations on capacity on RF spectrum in air/copper, These limitations might or might not be close: https://www.assia-inc.com/wp-content/uploads/2017/05/TDSL-presentation.pdf > and you need to handle this reality somehow. If a lot of power is used upstream then you'll get worse SNR for the downstream, meaning less capacity overall. Symmetric access capacity costs real money and results in less overall capacity unless it's on point to point fiber. Best Regards Sebastian > > -- > Mikael Abrahamsson email: swmike@swm.pp.se > _______________________________________________ > Bloat mailing list > Bloat@lists.bufferbloat.net > https://lists.bufferbloat.net/listinfo/bloat ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-12-12 22:03 ` Jonathan Morton 2017-12-12 22:21 ` David Lang @ 2017-12-13 12:39 ` Luca Muscariello 1 sibling, 0 replies; 76+ messages in thread From: Luca Muscariello @ 2017-12-13 12:39 UTC (permalink / raw) To: Jonathan Morton; +Cc: Benjamin Cronce, bloat [-- Attachment #1: Type: text/plain, Size: 1512 bytes --] If I understand the patch well, the ack filter is actually fixing the problem of ACK compression only. Because it is enforced on packets in the queue only. It is stateless. ACK compression would happen even w/o highly asymmetric access links by just having concurrent data streams with ack streams. So, IMO, the patch is harmless per se in all cases. ACK compression is harmful though and the patch fixes it. Background on ACK compression: Lixia Zhang, Scott Shenker, and Daivd D. Clark. Observations on the dynamics of a congestion control algorithm: the effects of two-way traffic. acm sigcomm 1991. On Tue, Dec 12, 2017 at 11:03 PM, Jonathan Morton <chromatix99@gmail.com> wrote: > The one "correct" argument against ack-filtering I've seen is that it > encourages (or rather validates) the use of extreme asymmetry ratios. > > However, these extreme ratios are already in widespread use without the > aid of ack-filtering. Even ADSL2 Annex A has, as its "ideal" sync rate, a > 16:1 ratio, which Annex M modifies to under 10:1. I fear we must conclude > that technical considerations are not the driving factor here. > > A better place to sort out the asymmetry problem (as well as several other > problems of current interest) would be in a free, competitive market. > Sadly such a thing is rare in the telecoms sector. > > - Jonathan Morton > > _______________________________________________ > Bloat mailing list > Bloat@lists.bufferbloat.net > https://lists.bufferbloat.net/listinfo/bloat > > [-- Attachment #2: Type: text/html, Size: 2838 bytes --] ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-11-29 6:09 ` Mikael Abrahamsson 2017-11-29 9:34 ` Sebastian Moeller @ 2017-11-29 18:21 ` Juliusz Chroboczek 2017-11-29 18:41 ` Dave Taht 2017-12-11 20:15 ` Benjamin Cronce 2 siblings, 1 reply; 76+ messages in thread From: Juliusz Chroboczek @ 2017-11-29 18:21 UTC (permalink / raw) To: Mikael Abrahamsson; +Cc: Dave Taht, bloat > The better solution would of course be to have the TCP peeps change the > way TCP works so that it sends fewer ACKs. Which tends to perturb the way the TCP self-clocking feedback loop works, and to break Nagle. > In the TCP implementations I tcpdump regularily, it seems they send one > ACK per 2 downstream packets. That's the delack algorithm. One of the stupidest algorithms I've had the displeasure of looking at (a fixed 500ms timeout, sheesh). And yes, it breaks Nagle. > I don't want middle boxes making "smart" decisions I agree, especially if they use transport-layer data to make their decisions. > Since this ACK reduction is done on probably hundreds of millions of > fixed-line subscriber lines today, what arguments do designers of TCP have > to keep sending one ACK per 2 received TCP packets? I think it's about growing the TCP congestion window fast enough. Recall that that AIMD counts received ACKs, not ACKed bytes. (And not breaking Nagle.) -- Juliusz ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-11-29 18:21 ` Juliusz Chroboczek @ 2017-11-29 18:41 ` Dave Taht 2017-11-29 23:29 ` Steinar H. Gunderson 2017-11-29 23:59 ` Stephen Hemminger 0 siblings, 2 replies; 76+ messages in thread From: Dave Taht @ 2017-11-29 18:41 UTC (permalink / raw) To: Juliusz Chroboczek; +Cc: Mikael Abrahamsson, bloat, Cake List On Wed, Nov 29, 2017 at 10:21 AM, Juliusz Chroboczek <jch@irif.fr> wrote: >> The better solution would of course be to have the TCP peeps change the >> way TCP works so that it sends fewer ACKs. > > Which tends to perturb the way the TCP self-clocking feedback loop works, > and to break Nagle. Linux TCP is no longer particularly ack-clocked. In the post pacing, post sch_fq world, packets are released (currently) on a 1ms schedule. Support was recently released for modifying that schedule on a per driver basis, which turns out to be helpful for wifi. see: https://www.spinics.net/lists/netdev/msg466312.html > >> In the TCP implementations I tcpdump regularily, it seems they send one >> ACK per 2 downstream packets. > > That's the delack algorithm. One of the stupidest algorithms I've had the > displeasure of looking at (a fixed 500ms timeout, sheesh). Nagle would probably agree. He once told me he wished for 1 ack per data packet... We were young then. > > And yes, it breaks Nagle. > >> I don't want middle boxes making "smart" decisions Ironically, it was dave reed's (co-author of the end to end argument) 50x1 ratio network connection that was an impetus to look harder at this, and what I modeled in http://blog.cerowrt.org/post/ack_filtering/ (I note there is discussion and way more tests landing on the cake mailing list) The astounding number was that we were able to drop 70% of all packets (and 90+% of acks) without doing any visible harm on the tests. > > I agree, especially if they use transport-layer data to make their > decisions. I'm not particularly fond of the idea myself! But I didn't invent severe network asymmetry, or cpus that can't context switch worth a damn. >> Since this ACK reduction is done on probably hundreds of millions of >> fixed-line subscriber lines today, What I'd started with was wanting to create impairments for netem that matched common ack-filtering schemes in the field already. > what arguments do designers of TCP have >> to keep sending one ACK per 2 received TCP packets? this would be a good list to have. I note osx does stretch acks by default. > > I think it's about growing the TCP congestion window fast enough. Recall > that that AIMD counts received ACKs, not ACKed bytes. the cake code has a specific optimization to preserve slow start. It can be improved. > > (And not breaking Nagle.) > > -- Juliusz -- Dave Täht CEO, TekLibre, LLC http://www.teklibre.com Tel: 1-669-226-2619 ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-11-29 18:41 ` Dave Taht @ 2017-11-29 23:29 ` Steinar H. Gunderson 2017-11-29 23:59 ` Stephen Hemminger 1 sibling, 0 replies; 76+ messages in thread From: Steinar H. Gunderson @ 2017-11-29 23:29 UTC (permalink / raw) To: Dave Taht; +Cc: Juliusz Chroboczek, Cake List, bloat On Wed, Nov 29, 2017 at 10:41:41AM -0800, Dave Taht wrote: > Linux TCP is no longer particularly ack-clocked. In the post pacing, > post sch_fq world, packets are released (currently) on a 1ms schedule. Most Linux hosts don't run sch_fq, though. I mean, it's not even default in a 4.15 kernel. /* Steinar */ -- Homepage: https://www.sesse.net/ ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-11-29 18:41 ` Dave Taht 2017-11-29 23:29 ` Steinar H. Gunderson @ 2017-11-29 23:59 ` Stephen Hemminger 2017-11-30 0:21 ` Eric Dumazet 1 sibling, 1 reply; 76+ messages in thread From: Stephen Hemminger @ 2017-11-29 23:59 UTC (permalink / raw) To: Dave Taht; +Cc: Juliusz Chroboczek, Cake List, bloat On Wed, 29 Nov 2017 10:41:41 -0800 Dave Taht <dave.taht@gmail.com> wrote: > On Wed, Nov 29, 2017 at 10:21 AM, Juliusz Chroboczek <jch@irif.fr> wrote: > >> The better solution would of course be to have the TCP peeps change the > >> way TCP works so that it sends fewer ACKs. > > > > Which tends to perturb the way the TCP self-clocking feedback loop works, > > and to break Nagle. > > Linux TCP is no longer particularly ack-clocked. In the post pacing, > post sch_fq world, packets are released (currently) on a 1ms schedule. > Support was recently released for modifying that schedule on a per > driver basis, which turns out to be helpful for wifi. > > see: https://www.spinics.net/lists/netdev/msg466312.html Also TCP BBR has lost its initial luster since it is unfair and ignores losses and ECN (see recent netdev paper). ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-11-29 23:59 ` Stephen Hemminger @ 2017-11-30 0:21 ` Eric Dumazet 0 siblings, 0 replies; 76+ messages in thread From: Eric Dumazet @ 2017-11-30 0:21 UTC (permalink / raw) To: Stephen Hemminger, Dave Taht; +Cc: Cake List, Juliusz Chroboczek, bloat On Wed, 2017-11-29 at 15:59 -0800, Stephen Hemminger wrote: > On Wed, 29 Nov 2017 10:41:41 -0800 > Dave Taht <dave.taht@gmail.com> wrote: > > > On Wed, Nov 29, 2017 at 10:21 AM, Juliusz Chroboczek <jch@irif.fr> > > wrote: > > > > The better solution would of course be to have the TCP peeps > > > > change the > > > > way TCP works so that it sends fewer ACKs. > > > > > > Which tends to perturb the way the TCP self-clocking feedback > > > loop works, > > > and to break Nagle. > > > > Linux TCP is no longer particularly ack-clocked. In the post > > pacing, > > post sch_fq world, packets are released (currently) on a 1ms > > schedule. > > Support was recently released for modifying that schedule on a per > > driver basis, which turns out to be helpful for wifi. > > > > see: https://www.spinics.net/lists/netdev/msg466312.html > > Also TCP BBR has lost its initial luster since it is unfair and > ignores > losses and ECN (see recent netdev paper). Recent netdev paper (from Larry) mentioned that fq_codel is used. fq_codel is stochastic, so not a fairness champion with many flows. There is a reason we use fq [1] instead ;) We asked Larry how to reproduce his (surprising) results, because we suspect some setup error or bias. He has to update his github trees. netem can be tricky to use properly. [1] Although the choice of packet scheduler is no longer an issue with BBR now TCP can fallback to internal pacing implementation. About ECN : We do not enable ECN for edge communications, so BBR runs without ECN being negotiated/accepted. We will probably take care of this point soon, but we had more urgent problems. ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-11-29 6:09 ` Mikael Abrahamsson 2017-11-29 9:34 ` Sebastian Moeller 2017-11-29 18:21 ` Juliusz Chroboczek @ 2017-12-11 20:15 ` Benjamin Cronce 2 siblings, 0 replies; 76+ messages in thread From: Benjamin Cronce @ 2017-12-11 20:15 UTC (permalink / raw) To: Mikael Abrahamsson; +Cc: Dave Taht, bloat [-- Attachment #1: Type: text/plain, Size: 2386 bytes --] I wonder if TCP could be effectively changed to send an ACK every WindowSize/N number of packets. We'd need to be careful about how this would affect 'slow start'. On Wed, Nov 29, 2017 at 12:09 AM, Mikael Abrahamsson <swmike@swm.pp.se> wrote: > On Tue, 28 Nov 2017, Dave Taht wrote: > > Recently Ryan Mounce added ack filtering cabilities to the cake qdisc. >> >> The benefits were pretty impressive at a 50x1 Down/Up ratio: >> >> http://blog.cerowrt.org/post/ack_filtering/ >> >> And quite noticeable at 16x1 ratios as well. >> >> I'd rather like to have a compelling list of reasons why not to do >> this! And ways to do it better, if not. The relevant code is hovering >> at: >> >> https://github.com/dtaht/sch_cake/blob/cobalt/sch_cake.c#L902 >> > > Your post is already quite comprehensive when it comes to downsides. > > The better solution would of course be to have the TCP peeps change the > way TCP works so that it sends fewer ACKs. I don't want middle boxes making > "smart" decisions when the proper solution is for both end TCP speakers to > do less work by sending fewer ACKs. In the TCP implementations I tcpdump > regularily, it seems they send one ACK per 2 downstream packets. > > At 1 gigabit/s that's in the order of 35k pps of ACKs (100 megabyte/s > divided by 1440 divided by 2). That's in my opinion completely ludicrous > rate of ACKs for no good reason. > > I don't know what the formula should be, but it sounds like the ACK > sending ratio should be influenced by how many in-flight ACKs there might > be. Is there any reason to have more than 100 ACKs in flight at any given > time? 500? 1000? > > My DOCSIS connection (inferred through observation) seems to run on 1ms > upstream time slots, and my modem will delete contigous ACKs at 16 or 32 > ACK intervals, ending up running at typically 1-2 ACKs per 1ms time slot. > This cuts down the ACK rate when I do 250 megabit/s downloads from 5-8 > megabit/s to 400 kilobit/s of used upstream bw. > > Since this ACK reduction is done on probably hundreds of millions of > fixed-line subscriber lines today, what arguments do designers of TCP have > to keep sending one ACK per 2 received TCP packets? > > -- > Mikael Abrahamsson email: swmike@swm.pp.se > > _______________________________________________ > Bloat mailing list > Bloat@lists.bufferbloat.net > https://lists.bufferbloat.net/listinfo/bloat > [-- Attachment #2: Type: text/html, Size: 3470 bytes --] ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-11-28 21:48 [Bloat] benefits of ack filtering Dave Taht 2017-11-29 6:09 ` Mikael Abrahamsson @ 2017-11-29 18:28 ` Juliusz Chroboczek 2017-11-29 18:48 ` Dave Taht 2017-12-11 18:30 ` Jonathan Morton 1 sibling, 2 replies; 76+ messages in thread From: Juliusz Chroboczek @ 2017-11-29 18:28 UTC (permalink / raw) To: Dave Taht; +Cc: bloat > Recently Ryan Mounce added ack filtering cabilities to the cake qdisc. > The benefits were pretty impressive at a 50x1 Down/Up ratio: If I read this posting right, you're only measuring bulk performance. What about interactive traffic, when there's only one or two data segments in flight at a given time > I'd rather like to have a compelling list of reasons why not to do > this! I haven't looked at Cake in detail, and I haven't put much thought into ACK filtering, but off the top of my head: - not risking breaking any of the TCP-related algorithms that depend on ACKs arriving in a timely manner (AIMD, Nagle, Eifel, etc.), especially in the case of just one segment in flight; - not contributing to the ossification of the Internet by giving an unfair advantage to TCP over other protocols; - limiting the amount of knowledge that middleboxes have of the transport-layer protocols, which leads to further ossification; - avoiding complexity in middleboxes, which leads to a more brittle Internet; - not encouraging ISPs to deploy highly asymmetric links. This is not my area of expertise, and therefore I don't feel competent to have an opinion, but I think that before you deploy ACK filtering, you really should consider the worries expressed above and whatever other worries more competent people might have. -- Juliusz ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-11-29 18:28 ` Juliusz Chroboczek @ 2017-11-29 18:48 ` Dave Taht 2017-12-11 18:30 ` Jonathan Morton 1 sibling, 0 replies; 76+ messages in thread From: Dave Taht @ 2017-11-29 18:48 UTC (permalink / raw) To: Juliusz Chroboczek; +Cc: bloat, Cake List On Wed, Nov 29, 2017 at 10:28 AM, Juliusz Chroboczek <jch@irif.fr> wrote: >> Recently Ryan Mounce added ack filtering cabilities to the cake qdisc. >> The benefits were pretty impressive at a 50x1 Down/Up ratio: > > If I read this posting right, you're only measuring bulk performance. > What about interactive traffic, when there's only one or two data segments in > flight at a given time In this design, you can only filter out an ack when you have a queue of them. I am thinking saying "filter" has been misleading. Tho plenty stateless ack filters exist. ack-queue-compression? >> I'd rather like to have a compelling list of reasons why not to do >> this! > > I haven't looked at Cake in detail, and I haven't put much thought into > ACK filtering, but off the top of my head: > > - not risking breaking any of the TCP-related algorithms that depend on > ACKs arriving in a timely manner (AIMD, Nagle, Eifel, etc.), > especially in the case of just one segment in flight; > - not contributing to the ossification of the Internet by giving an > unfair advantage to TCP over other protocols; > - limiting the amount of knowledge that middleboxes have of the > transport-layer protocols, which leads to further ossification; > - avoiding complexity in middleboxes, which leads to a more brittle > Internet; > - not encouraging ISPs to deploy highly asymmetric links. I'll add these to my list! > > This is not my area of expertise, and therefore I don't feel competent to > have an opinion, but I think that before you deploy ACK filtering, you > really should consider the worries expressed above and whatever other > worries more competent people might have. been worrying ever since I touched the wet paint! > -- Juliusz -- Dave Täht CEO, TekLibre, LLC http://www.teklibre.com Tel: 1-669-226-2619 ^ permalink raw reply [flat|nested] 76+ messages in thread
* Re: [Bloat] benefits of ack filtering 2017-11-29 18:28 ` Juliusz Chroboczek 2017-11-29 18:48 ` Dave Taht @ 2017-12-11 18:30 ` Jonathan Morton 1 sibling, 0 replies; 76+ messages in thread From: Jonathan Morton @ 2017-12-11 18:30 UTC (permalink / raw) To: Juliusz Chroboczek; +Cc: Dave Taht, bloat [-- Attachment #1: Type: text/plain, Size: 505 bytes --] While I haven't yet studied the ack filtering code in depth, Ryan indicated that some of those concerns were considered in its design. In particular, it won't ever delete the last remaining ack in a flow's queue, only replace it with a more recently arrived one. That should take care of interactive performance, which has always been high on Cake's design considerations. Cake itself is also careful to not drop the last packet (of any type) in a flow's queue, for similar reasons. - Jonathan Morton [-- Attachment #2: Type: text/html, Size: 602 bytes --] ^ permalink raw reply [flat|nested] 76+ messages in thread
end of thread, other threads:[~2017-12-13 12:39 UTC | newest]
Thread overview: 76+ messages (download: mbox.gz / follow: Atom feed)
-- links below jump to the message on this page --
2017-11-28 21:48 [Bloat] benefits of ack filtering Dave Taht
2017-11-29 6:09 ` Mikael Abrahamsson
2017-11-29 9:34 ` Sebastian Moeller
2017-11-29 12:49 ` Mikael Abrahamsson
2017-11-29 13:13 ` Luca Muscariello
2017-11-29 14:31 ` Mikael Abrahamsson
2017-11-29 14:36 ` Jonathan Morton
2017-11-29 15:24 ` Andrés Arcia-Moret
2017-11-29 15:53 ` Luca Muscariello
[not found] ` <CAJq5cE3qsmy8EFYZmQsLL_frm8Tty9Gkm92MQPZ649+kpM1oMw@mail.gmail.com>
2017-11-29 16:13 ` Jonathan Morton
2017-11-30 7:03 ` Michael Welzl
2017-11-30 7:24 ` Dave Taht
2017-11-30 7:45 ` Dave Taht
2017-11-30 7:48 ` Jonathan Morton
2017-11-30 8:00 ` Luca Muscariello
2017-11-30 10:24 ` Eric Dumazet
2017-11-30 13:04 ` Mikael Abrahamsson
2017-11-30 15:51 ` Eric Dumazet
2017-12-01 0:28 ` David Lang
2017-12-01 7:09 ` Jan Ceuleers
2017-12-01 12:53 ` Toke Høiland-Jørgensen
2017-12-01 13:13 ` [Bloat] [Make-wifi-fast] " Кирилл Луконин
2017-12-01 13:22 ` Luca Muscariello
2017-12-11 17:42 ` Simon Barber
2017-12-01 13:17 ` [Bloat] " Luca Muscariello
2017-12-01 13:40 ` Toke Høiland-Jørgensen
2017-12-01 17:42 ` Dave Taht
2017-12-01 20:39 ` Juliusz Chroboczek
2017-12-03 5:20 ` [Bloat] [Make-wifi-fast] " Bob McMahon
2017-12-03 10:35 ` Juliusz Chroboczek
2017-12-03 11:40 ` Jan Ceuleers
2017-12-03 13:57 ` Juliusz Chroboczek
2017-12-03 14:07 ` Mikael Abrahamsson
2017-12-03 19:53 ` Juliusz Chroboczek
2017-12-03 14:09 ` Ryan Mounce
2017-12-03 19:54 ` Juliusz Chroboczek
2017-12-03 20:14 ` Sebastian Moeller
2017-12-03 22:27 ` Dave Taht
2017-12-03 15:25 ` Robert Bradley
2017-12-04 3:44 ` Dave Taht
2017-12-04 14:38 ` David Collier-Brown
2017-12-04 15:44 ` Juliusz Chroboczek
2017-12-04 17:17 ` David Collier-Brown
2017-12-03 19:04 ` Bob McMahon
2017-12-01 21:17 ` Bob McMahon
2017-12-01 8:45 ` [Bloat] " Sebastian Moeller
2017-12-01 10:45 ` Luca Muscariello
2017-12-01 18:43 ` Dave Taht
2017-12-01 18:57 ` Luca Muscariello
2017-12-01 19:36 ` Dave Taht
2017-11-30 14:51 ` Neal Cardwell
2017-11-30 15:55 ` Eric Dumazet
2017-11-30 15:57 ` Neal Cardwell
2017-11-29 16:50 ` Sebastian Moeller
2017-12-12 19:27 ` Benjamin Cronce
2017-12-12 20:04 ` Dave Taht
2017-12-12 21:03 ` David Lang
2017-12-12 21:29 ` Jonathan Morton
2017-12-12 22:03 ` Jonathan Morton
2017-12-12 22:21 ` David Lang
[not found] ` <CAJq5cE3nfSQP0GCLjp=X0T-iHHgAs=YUCcr34e3ARgkrGZe-wg@mail.gmail.com>
2017-12-12 22:41 ` Jonathan Morton
2017-12-13 9:46 ` Mikael Abrahamsson
2017-12-13 10:03 ` Jonathan Morton
2017-12-13 12:11 ` Sebastian Moeller
2017-12-13 12:18 ` Jonathan Morton
2017-12-13 12:36 ` Sebastian Moeller
2017-12-13 12:39 ` Luca Muscariello
2017-11-29 18:21 ` Juliusz Chroboczek
2017-11-29 18:41 ` Dave Taht
2017-11-29 23:29 ` Steinar H. Gunderson
2017-11-29 23:59 ` Stephen Hemminger
2017-11-30 0:21 ` Eric Dumazet
2017-12-11 20:15 ` Benjamin Cronce
2017-11-29 18:28 ` Juliusz Chroboczek
2017-11-29 18:48 ` Dave Taht
2017-12-11 18:30 ` Jonathan Morton
This is a public inbox, see mirroring instructions for how to clone and mirror all data and code used for this inbox
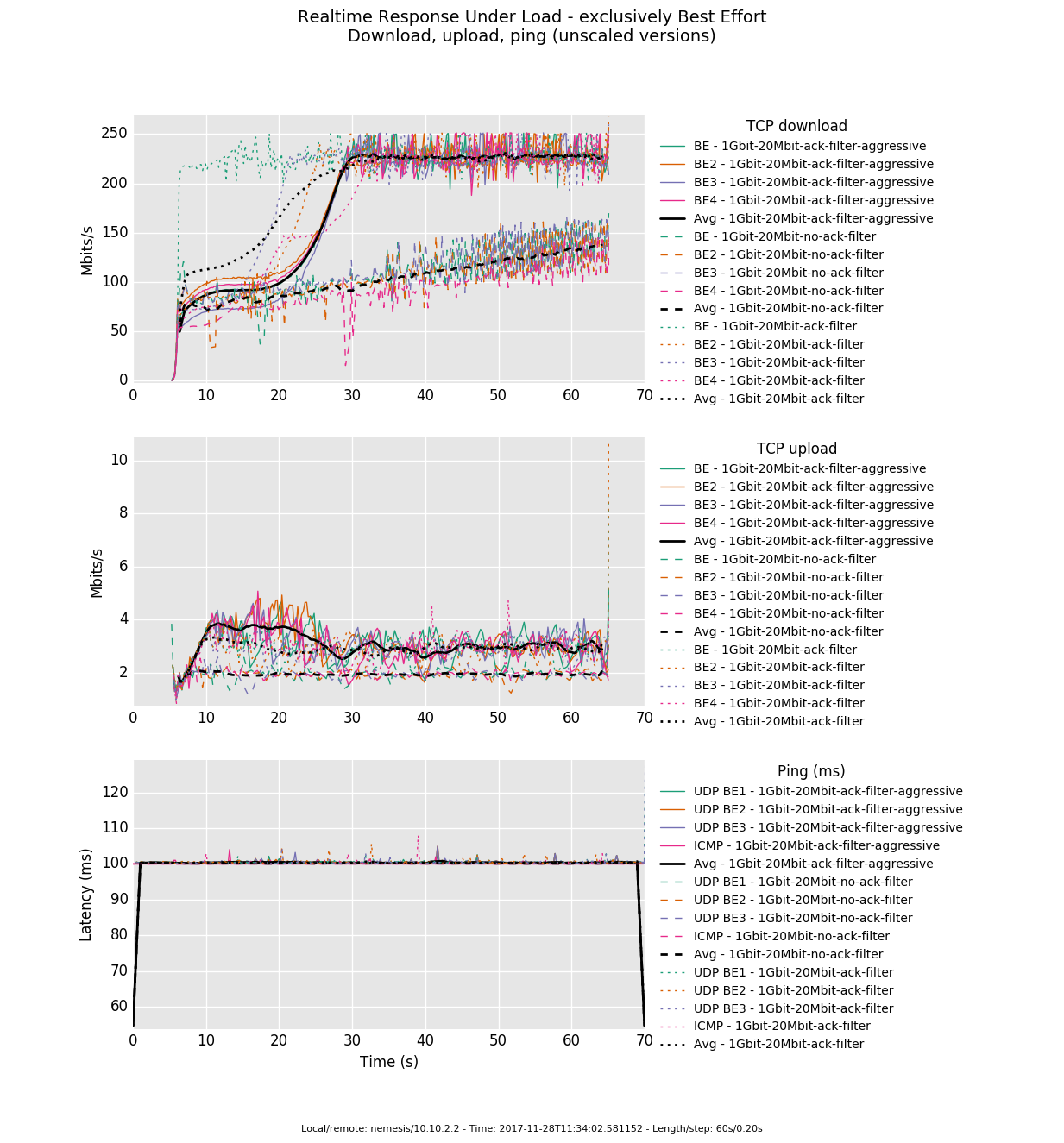{kind=link}