* [Cake] improving inbound shaping
@ 2017-03-03 6:54 Dave Taht
2017-03-03 9:22 ` Sebastian Moeller
0 siblings, 1 reply; 3+ messages in thread
From: Dave Taht @ 2017-03-03 6:54 UTC (permalink / raw)
To: Cake List
As that's the highest cpu user there is, (and the biggest problem I
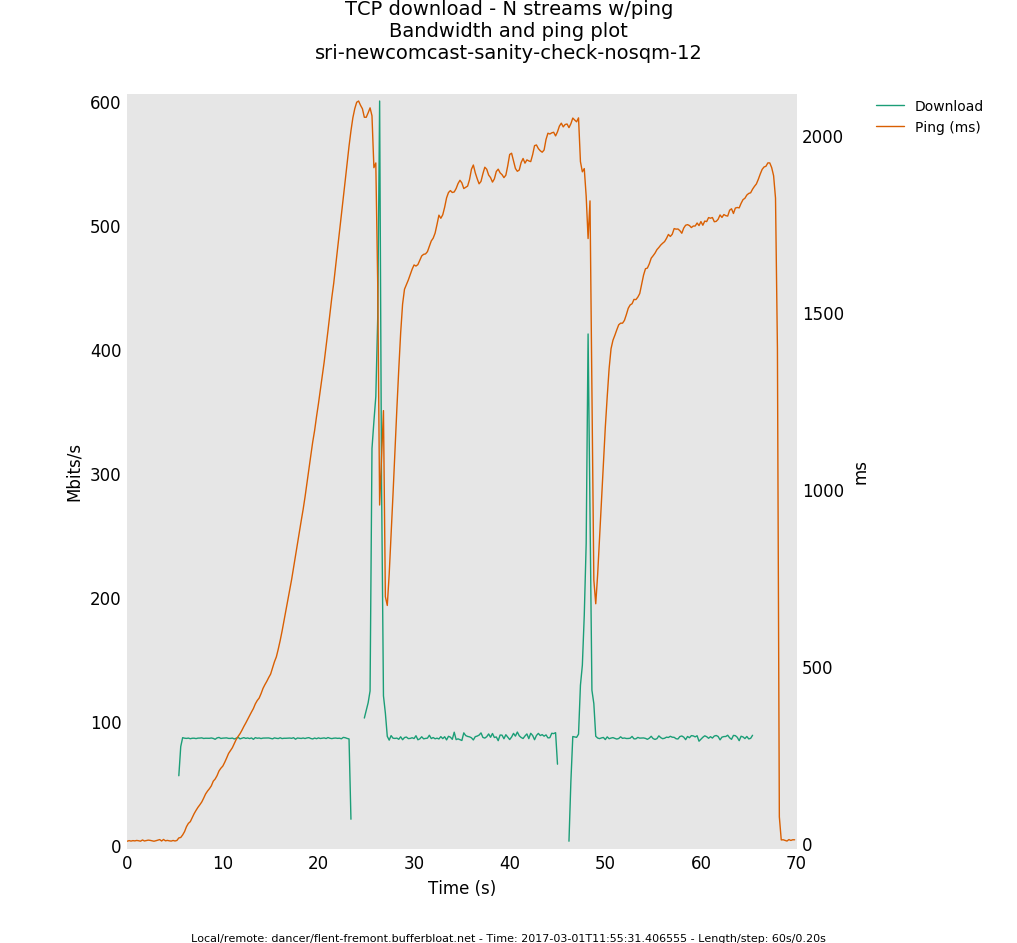
have, on comcast, there's 2 sec of latency at 100mbit without shaping:
http://www.taht.net/~d/comcast2/asmiserabledlasever.png
(more flent data there).
It's always been a daydream to somehow bypass the existing tc_mirred
facility we use and be able to express:
tc qdisc add dev eth0 ingress cake bandwidth 990mbit
and have that "just work". My hope would be that that would halve
the packet copies needed (don't know if that's the case in the first place)...
When I last looked at it (2+ years ago), that portion of linux was a
hairball that extended back to the late 90s, and I gave up.
There were a few commits there recently - adding hardware offload
support for the flower classifier and this one:
commit d2788d34885d4ce5ba17a8996fd95d28942e574e
Author: Daniel Borkmann <daniel@iogearbox.net>
Date: Sat May 9 22:51:32 2015 +0200
net: sched: further simplify handle_ing
Ingress qdisc has no other purpose than calling into tc_classify()
that executes attached classifier(s) and action(s).
It has a 1:1 relationship to dev->ingress_queue. After having commit
087c1a601ad7 ("net: sched: run ingress qdisc without locks") removed
the central ingress lock, one major contention point is gone.
The extra indirection layers however, are not necessary for calling
into ingress qdisc. pktgen calling locally into netif_receive_skb()
with a dummy u32, single CPU result on a Supermicro X10SLM-F, Xeon
E3-1240: before ~21,1 Mpps, after patch ~22,9 Mpps.
--
Dave Täht
Let's go make home routers and wifi faster! With better software!
http://blog.cerowrt.org
^ permalink raw reply [flat|nested] 3+ messages in thread* Re: [Cake] improving inbound shaping 2017-03-03 6:54 [Cake] improving inbound shaping Dave Taht @ 2017-03-03 9:22 ` Sebastian Moeller 2017-03-03 14:23 ` Dave Taht 0 siblings, 1 reply; 3+ messages in thread From: Sebastian Moeller @ 2017-03-03 9:22 UTC (permalink / raw) To: cake, Dave Taht Hi Dave, Last time I tested this I came to the conclusion, that going via ifb and mirred cost something like 5% shaper sqm performance on ingress. While not nothing I am not sure this as big a performance issue as you seem to argue. Your proposal would improve usability quite a lot though if we could avoid the whole ifb-dance... To assess the cost of the mirred ifb ingress, I simply instantiated the shaper for internet download not on ingress of the wan interface, but on egress of the LAN interface connecting the sole testing host, so I believe the only difference in work for the system should be the ifb/mirred processing. On March 3, 2017 7:54:23 AM GMT+01:00, Dave Taht <dave.taht@gmail.com> wrote: >As that's the highest cpu user there is, (and the biggest problem I >have, on comcast, there's 2 sec of latency at 100mbit without shaping: > > http://www.taht.net/~d/comcast2/asmiserabledlasever.png >(more flent data there). > >It's always been a daydream to somehow bypass the existing tc_mirred >facility we use and be able to express: > >tc qdisc add dev eth0 ingress cake bandwidth 990mbit > >and have that "just work". My hope would be that that would halve >the packet copies needed (don't know if that's the case in the first >place)... > >When I last looked at it (2+ years ago), that portion of linux was a >hairball that extended back to the late 90s, and I gave up. > >There were a few commits there recently - adding hardware offload >support for the flower classifier and this one: > >commit d2788d34885d4ce5ba17a8996fd95d28942e574e >Author: Daniel Borkmann <daniel@iogearbox.net> >Date: Sat May 9 22:51:32 2015 +0200 > > net: sched: further simplify handle_ing > > Ingress qdisc has no other purpose than calling into tc_classify() > that executes attached classifier(s) and action(s). > > It has a 1:1 relationship to dev->ingress_queue. After having commit > 087c1a601ad7 ("net: sched: run ingress qdisc without locks") removed > the central ingress lock, one major contention point is gone. > > The extra indirection layers however, are not necessary for calling > into ingress qdisc. pktgen calling locally into netif_receive_skb() > with a dummy u32, single CPU result on a Supermicro X10SLM-F, Xeon > E3-1240: before ~21,1 Mpps, after patch ~22,9 Mpps. > > > > >-- >Dave Täht >Let's go make home routers and wifi faster! With better software! >http://blog.cerowrt.org >_______________________________________________ >Cake mailing list >Cake@lists.bufferbloat.net >https://lists.bufferbloat.net/listinfo/cake ^ permalink raw reply [flat|nested] 3+ messages in thread
* Re: [Cake] improving inbound shaping 2017-03-03 9:22 ` Sebastian Moeller @ 2017-03-03 14:23 ` Dave Taht 0 siblings, 0 replies; 3+ messages in thread From: Dave Taht @ 2017-03-03 14:23 UTC (permalink / raw) To: Sebastian Moeller; +Cc: Cake List On Fri, Mar 3, 2017 at 1:22 AM, Sebastian Moeller <moeller0@gmx.de> wrote: > Hi Dave, > > > Last time I tested this I came to the conclusion, that going via ifb and mirred cost something like 5% shaper sqm performance on ingress. While not nothing I am not sure this as big a performance issue as you seem to argue. Didn't say double the performance, I said "halve the packet copies". Amdahl's law applies. 5% is a foothold. > Your proposal would improve usability quite a lot though if we could avoid the whole ifb-dance... > > To assess the cost of the mirred ifb ingress, I simply instantiated the shaper for internet download not on ingress of the wan interface, but on egress of the LAN interface connecting the sole testing host, so I believe the only difference in work for the system should be the ifb/mirred processing. Well, I plan to fiddle with a new tp-link AC2600 at these higher speeds. That's a dual core arm, and my initial tests with it were quite nice... well, I couldn't crash it, anyway. There's a mcast bug easily fixed in the ethernet driver, the wifi is an ath10k alike that doesn't currently have the make-wifi-fast fixes and I can profile, a bit on it. They're 128 bucks on amazon. https://www.amazon.com/TP-Link-Wireless-Technology-Archer-C2600/dp/B010UR8AM2 > > On March 3, 2017 7:54:23 AM GMT+01:00, Dave Taht <dave.taht@gmail.com> wrote: >>As that's the highest cpu user there is, (and the biggest problem I >>have, on comcast, there's 2 sec of latency at 100mbit without shaping: >> >> http://www.taht.net/~d/comcast2/asmiserabledlasever.png >>(more flent data there). >> >>It's always been a daydream to somehow bypass the existing tc_mirred >>facility we use and be able to express: >> >>tc qdisc add dev eth0 ingress cake bandwidth 990mbit >> >>and have that "just work". My hope would be that that would halve >>the packet copies needed (don't know if that's the case in the first >>place)... >> >>When I last looked at it (2+ years ago), that portion of linux was a >>hairball that extended back to the late 90s, and I gave up. >> >>There were a few commits there recently - adding hardware offload >>support for the flower classifier and this one: >> >>commit d2788d34885d4ce5ba17a8996fd95d28942e574e >>Author: Daniel Borkmann <daniel@iogearbox.net> >>Date: Sat May 9 22:51:32 2015 +0200 >> >> net: sched: further simplify handle_ing >> >> Ingress qdisc has no other purpose than calling into tc_classify() >> that executes attached classifier(s) and action(s). >> >> It has a 1:1 relationship to dev->ingress_queue. After having commit >> 087c1a601ad7 ("net: sched: run ingress qdisc without locks") removed >> the central ingress lock, one major contention point is gone. >> >> The extra indirection layers however, are not necessary for calling >> into ingress qdisc. pktgen calling locally into netif_receive_skb() >> with a dummy u32, single CPU result on a Supermicro X10SLM-F, Xeon >> E3-1240: before ~21,1 Mpps, after patch ~22,9 Mpps. >> >> >> >> >>-- >>Dave Täht >>Let's go make home routers and wifi faster! With better software! >>http://blog.cerowrt.org >>_______________________________________________ >>Cake mailing list >>Cake@lists.bufferbloat.net >>https://lists.bufferbloat.net/listinfo/cake -- Dave Täht Let's go make home routers and wifi faster! With better software! http://blog.cerowrt.org ^ permalink raw reply [flat|nested] 3+ messages in thread
end of thread, other threads:[~2017-03-03 14:23 UTC | newest] Thread overview: 3+ messages (download: mbox.gz / follow: Atom feed) -- links below jump to the message on this page -- 2017-03-03 6:54 [Cake] improving inbound shaping Dave Taht 2017-03-03 9:22 ` Sebastian Moeller 2017-03-03 14:23 ` Dave Taht
This is a public inbox, see mirroring instructions for how to clone and mirror all data and code used for this inbox
{kind=link}