* Re: [Starlink] [Rpm] On FiWi
@ 2023-03-17 16:54 David Fernández
2023-03-17 17:05 ` [Starlink] GPON vs Active Fiber Ethernet Dave Taht
0 siblings, 1 reply; 14+ messages in thread
From: David Fernández @ 2023-03-17 16:54 UTC (permalink / raw)
To: starlink
Hi Dave,
Telefonica achieved considerable gains in efficiency dismantling the
copper network (85% gains in energy efficiency).
Read here: https://www.xataka.com/empresas-y-economia/paso-cobre-adsl-a-fibra-ha-sido-beneficioso-para-todos-especialmente-para-telefonica
Regards,
David
> Date: Fri, 17 Mar 2023 09:38:03 -0700
> From: Dave Taht <dave.taht@gmail.com>
> To: Mike Puchol <mike@starlink.sx>
> Cc: Dave Taht via Starlink <starlink@lists.bufferbloat.net>, Rpm
> <rpm@lists.bufferbloat.net>, libreqos
> <libreqos@lists.bufferbloat.net>, bloat <bloat@lists.bufferbloat.net>
> Subject: Re: [Starlink] [Rpm] On FiWi
> Message-ID:
> <CAA93jw6EWH19Jo-pUJMX7QCi=GfHD8iWTDKCcRY=0tEOe4Vt1Q@mail.gmail.com>
> Content-Type: text/plain; charset="utf-8"
>
> This is a pretty neat box:
>
> https://mikrotik.com/product/netpower_lite_7r
>
> What are the compelling arguments for fiber vs copper, again?
>
>
> On Tue, Mar 14, 2023 at 4:10 AM Mike Puchol via Rpm <
> rpm@lists.bufferbloat.net> wrote:
>
>> Hi Bob,
>>
>> You hit on a set of very valid points, which I'll complement with my views
>> on where the industry (the bit of it that affects WISPs) is heading, and
>> what I saw at the MWC in Barcelona. Love the FiWi term :-)
>>
>> I have seen the vendors that supply WISPs, such as Ubiquiti, Cambium, and
>> Mimosa, but also newer entrants such as Tarana, increase the performance
>> and on-paper specs of their equipment. My examples below are centered on
>> the African market, if you operate in Europe or the US, where you can
>> charge customers a higher install fee, or even charge them a break-up fee
>> if they don't return equipment, the economics work.
>>
>> Where currently a ~$500 sector radio could serve ~60 endpoints, at a cost
>> of ~$50 per endpoint (I use this term in place of ODU/CPE, the antenna
>> that
>> you mount on the roof), and supply ~2.5 Mbps CIR per endpoint, the
>> evolution is now a ~$2,000+ sector radio, a $200 endpoint, capability for
>> ~150 endpoints per sector, and ~25 Mbps CIR per endpoint.
>>
>> If every customer a WISP installs represents, say, $100 CAPEX at install
>> time ($50 for the antenna + cabling, router, etc), and you charge a $30
>> install fee, you have $70 to recover, and you recover from the monthly
>> contribution the customer makes. If the contribution after OPEX is, say,
>> $10, it takes you 7 months to recover the full install cost. Not bad,
>> doable even in low-income markets.
>>
>> Fast-forward to the next-generation version. Now, the CAPEX at install is
>> $250, you need to recover $220, and it will take you 22 months, which is
>> above the usual 18 months that investors look for.
>>
>> The focus, thereby, has to be the lever that has the largest effect on the
>> unit economics - which is the per-customer cost. I have drawn what my
>> ideal
>> FiWi network would look like:
>>
>>
>>
>> Taking you through this - we start with a 1-port, low-cost EPON OLT (or
>> you could go for 2, 4, 8 ports as you add capacity). This OLT has capacity
>> for 64 ONUs on its single port. Instead of connecting the typical fiber
>> infrastructure with kilometers of cables which break, require maintenance,
>> etc. we insert an EPON to Ethernet converter (I added "magic" because
>> these
>> don't exist AFAIK).
>>
>> This converter allows us to connect our $2k sector radio, and serve the
>> $200 endpoints (ODUs) over wireless point-to-multipoint up to 10km away.
>> Each ODU then has a reverse converter, which gives us EPON again.
>>
>> Once we are back on EPON, we can insert splitters, for example,
>> pre-connectorized outdoor 1:16 boxes. Every customer install now involves
>> a
>> 100 meter roll of pre-connectorized 2-core drop cable, and a $20 EPON ONU.
>>
>> Using this deployment method, we could connect up to 16 customers to a
>> single $200 endpoint, so the enpoint CAPEX per customer is now $12.5. Add
>> the ONU, cable, etc. and we have a per-install CAPEX of $82.5 (assuming
>> the
>> same $50 of extras we had before), and an even shorter break-even. In
>> addition, as the endpoints support higher capacity, we can provision at
>> least the same, if not more, capacity per customer.
>>
>> Other advantages: the $200 ODU is no longer customer equipment and CAPEX,
>> but network equipment, and as such, can operate under a longer break-even
>> timeline, and be financed by infrastructure PE funds, for example. As a
>> result, churn has a much lower financial impact on the operator.
>>
>> The main reason why this wouldn't work today is that EPON, as we know, is
>> synchronous, and requires the OLT to orchestrate the amount of time each
>> ONU can transmit, and when. Having wireless hops and media conversions
>> will
>> introduce latencies which can break down the communications (e.g. one ONU
>> may transmit, get delayed on the radio link, and end up overlapping
>> another
>> ONU that transmitted on the next slot). Thus, either the "magic" box needs
>> to account for this, or an new hybrid EPON-wireless protocol developed.
>>
>> My main point here: the industry is moving away from the unconnected. All
>> the claims I heard and saw at MWC about "connecting the unconnected" had
>> zero resonance with the financial drivers that the unconnected really
>> operate under, on top of IT literacy, digital skills, devices, power...
>>
>> Best,
>>
>> Mike
>> On Mar 14, 2023 at 05:27 +0100, rjmcmahon via Starlink <
>> starlink@lists.bufferbloat.net>, wrote:
>>
>> To change the topic - curious to thoughts on FiWi.
>>
>> Imagine a world with no copper cable called FiWi (Fiber,VCSEL/CMOS
>> Radios, Antennas) and which is point to point inside a building
>> connected to virtualized APs fiber hops away. Each remote radio head
>> (RRH) would consume 5W or less and only when active. No need for things
>> like zigbee, or meshes, or threads as each radio has a fiber connection
>> via Corning's actifi or equivalent. Eliminate the AP/Client power
>> imbalance. Plastics also can house smoke or other sensors.
>>
>> Some reminders from Paul Baran in 1994 (and from David Reed)
>>
>> o) Shorter range rf transceivers connected to fiber could produce a
>> significant improvement - - tremendous improvement, really.
>> o) a mixture of terrestrial links plus shorter range radio links has the
>> effect of increasing by orders and orders of magnitude the amount of
>> frequency spectrum that can be made available.
>> o) By authorizing high power to support a few users to reach slightly
>> longer distances we deprive ourselves of the opportunity to serve the
>> many.
>> o) Communications systems can be built with 10dB ratio
>> o) Digital transmission when properly done allows a small signal to
>> noise ratio to be used successfully to retrieve an error free signal.
>> o) And, never forget, any transmission capacity not used is wasted
>> forever, like water over the dam. Not using such techniques represent
>> lost opportunity.
>>
>> And on waveguides:
>>
>> o) "Fiber transmission loss is ~0.5dB/km for single mode fiber,
>> independent of modulation"
>> o) “Copper cables and PCB traces are very frequency dependent. At
>> 100Gb/s, the loss is in dB/inch."
>> o) "Free space: the power density of the radio waves decreases with the
>> square of distance from the transmitting antenna due to spreading of the
>> electromagnetic energy in space according to the inverse square law"
>>
>> The sunk costs & long-lived parts of FiWi are the fiber and the CPE
>> plastics & antennas, as CMOS radios+ & fiber/laser, e.g. VCSEL could be
>> pluggable, allowing for field upgrades. Just like swapping out SFP in a
>> data center.
>>
>> This approach basically drives out WiFi latency by eliminating shared
>> queues and increases capacity by orders of magnitude by leveraging 10dB
>> in the spatial dimension, all of which is achieved by a physical design.
>> Just place enough RRHs as needed (similar to a pop up sprinkler in an
>> irrigation system.)
>>
>> Start and build this for an MDU and the value of the building improves.
>> Sadly, there seems no way to capture that value other than over long
>> term use. It doesn't matter whether the leader of the HOA tries to
>> capture the value or if a last mile provider tries. The value remains
>> sunk or hidden with nothing on the asset side of the balance sheet.
>> We've got a CAPEX spend that has to be made up via "OPEX returns" over
>> years.
>>
>> But the asset is there.
>>
>> How do we do this?
>>
>> Bob
>> _______________________________________________
>> Starlink mailing list
>> Starlink@lists.bufferbloat.net
>> https://lists.bufferbloat.net/listinfo/starlink
>>
>> _______________________________________________
>> Rpm mailing list
>> Rpm@lists.bufferbloat.net
>> https://lists.bufferbloat.net/listinfo/rpm
>>
>
>
> --
> Come Heckle Mar 6-9 at: https://www.understandinglatency.com
> <https://www.understandinglatency.com/Dave>/
> Dave Täht CEO, TekLibre, LLC
> -------------- next part --------------
> An HTML attachment was scrubbed...
> URL:
> <https://lists.bufferbloat.net/pipermail/starlink/attachments/20230317/c9c62be3/attachment.html>
> -------------- next part --------------
> A non-text attachment was scrubbed...
> Name: Hybrid EPON-Wireless network.png
> Type: image/png
> Size: 149871 bytes
> Desc: not available
> URL:
> <https://lists.bufferbloat.net/pipermail/starlink/attachments/20230317/c9c62be3/attachment.png>
>
> ------------------------------
>
> Subject: Digest Footer
>
> _______________________________________________
> Starlink mailing list
> Starlink@lists.bufferbloat.net
> https://lists.bufferbloat.net/listinfo/starlink
>
>
> ------------------------------
>
> End of Starlink Digest, Vol 24, Issue 39
> ****************************************
>
^ permalink raw reply [flat|nested] 14+ messages in thread* [Starlink] GPON vs Active Fiber Ethernet 2023-03-17 16:54 [Starlink] [Rpm] On FiWi David Fernández @ 2023-03-17 17:05 ` Dave Taht 2023-03-17 20:36 ` Sebastian Moeller 0 siblings, 1 reply; 14+ messages in thread From: Dave Taht @ 2023-03-17 17:05 UTC (permalink / raw) To: David Fernández; +Cc: Dave Taht via Starlink, libreqos On Fri, Mar 17, 2023 at 9:54 AM David Fernández via Starlink <starlink@lists.bufferbloat.net> wrote: > > Hi Dave, > > Telefonica achieved considerable gains in efficiency dismantling the > copper network (85% gains in energy efficiency). > > Read here: https://www.xataka.com/empresas-y-economia/paso-cobre-adsl-a-fibra-ha-sido-beneficioso-para-todos-especialmente-para-telefonica I am not prepared to make a coherent argument (although I enjoy them), but I look at the serialization delay of gpon of 250us and other potential multiplexing problems, and go, "yuck". It really, really, really is the RTT that dominates the performance of all our networking technologies, and no matter how much bandwidth you have, nearly every per-sub tech I know of has a floor above 250us today. Multiple hops of mmwave are particularly bad here. Modern active fiber ethernet is 10000x quicker (nanoseconds!), very standardized, increasingly low power (with a ton of bang for the buck/gbit), with gear available everywhere that "just works", leveraging the past decade of rapid development in the data center, with USED 1Gbit SFPs going into trashbins everywhere. ... while gpon is, if anything, more proprietary than cable, the gear, more expensive, and did I mention the latency? /me dons flame retardant suit > > Regards, > > David > > > Date: Fri, 17 Mar 2023 09:38:03 -0700 > > From: Dave Taht <dave.taht@gmail.com> > > To: Mike Puchol <mike@starlink.sx> > > Cc: Dave Taht via Starlink <starlink@lists.bufferbloat.net>, Rpm > > <rpm@lists.bufferbloat.net>, libreqos > > <libreqos@lists.bufferbloat.net>, bloat <bloat@lists.bufferbloat.net> > > Subject: Re: [Starlink] [Rpm] On FiWi > > Message-ID: > > <CAA93jw6EWH19Jo-pUJMX7QCi=GfHD8iWTDKCcRY=0tEOe4Vt1Q@mail.gmail.com> > > Content-Type: text/plain; charset="utf-8" > > > > This is a pretty neat box: > > > > https://mikrotik.com/product/netpower_lite_7r > > > > What are the compelling arguments for fiber vs copper, again? > > > > > > On Tue, Mar 14, 2023 at 4:10 AM Mike Puchol via Rpm < > > rpm@lists.bufferbloat.net> wrote: > > > >> Hi Bob, > >> > >> You hit on a set of very valid points, which I'll complement with my views > >> on where the industry (the bit of it that affects WISPs) is heading, and > >> what I saw at the MWC in Barcelona. Love the FiWi term :-) > >> > >> I have seen the vendors that supply WISPs, such as Ubiquiti, Cambium, and > >> Mimosa, but also newer entrants such as Tarana, increase the performance > >> and on-paper specs of their equipment. My examples below are centered on > >> the African market, if you operate in Europe or the US, where you can > >> charge customers a higher install fee, or even charge them a break-up fee > >> if they don't return equipment, the economics work. > >> > >> Where currently a ~$500 sector radio could serve ~60 endpoints, at a cost > >> of ~$50 per endpoint (I use this term in place of ODU/CPE, the antenna > >> that > >> you mount on the roof), and supply ~2.5 Mbps CIR per endpoint, the > >> evolution is now a ~$2,000+ sector radio, a $200 endpoint, capability for > >> ~150 endpoints per sector, and ~25 Mbps CIR per endpoint. > >> > >> If every customer a WISP installs represents, say, $100 CAPEX at install > >> time ($50 for the antenna + cabling, router, etc), and you charge a $30 > >> install fee, you have $70 to recover, and you recover from the monthly > >> contribution the customer makes. If the contribution after OPEX is, say, > >> $10, it takes you 7 months to recover the full install cost. Not bad, > >> doable even in low-income markets. > >> > >> Fast-forward to the next-generation version. Now, the CAPEX at install is > >> $250, you need to recover $220, and it will take you 22 months, which is > >> above the usual 18 months that investors look for. > >> > >> The focus, thereby, has to be the lever that has the largest effect on the > >> unit economics - which is the per-customer cost. I have drawn what my > >> ideal > >> FiWi network would look like: > >> > >> > >> > >> Taking you through this - we start with a 1-port, low-cost EPON OLT (or > >> you could go for 2, 4, 8 ports as you add capacity). This OLT has capacity > >> for 64 ONUs on its single port. Instead of connecting the typical fiber > >> infrastructure with kilometers of cables which break, require maintenance, > >> etc. we insert an EPON to Ethernet converter (I added "magic" because > >> these > >> don't exist AFAIK). > >> > >> This converter allows us to connect our $2k sector radio, and serve the > >> $200 endpoints (ODUs) over wireless point-to-multipoint up to 10km away. > >> Each ODU then has a reverse converter, which gives us EPON again. > >> > >> Once we are back on EPON, we can insert splitters, for example, > >> pre-connectorized outdoor 1:16 boxes. Every customer install now involves > >> a > >> 100 meter roll of pre-connectorized 2-core drop cable, and a $20 EPON ONU. > >> > >> Using this deployment method, we could connect up to 16 customers to a > >> single $200 endpoint, so the enpoint CAPEX per customer is now $12.5. Add > >> the ONU, cable, etc. and we have a per-install CAPEX of $82.5 (assuming > >> the > >> same $50 of extras we had before), and an even shorter break-even. In > >> addition, as the endpoints support higher capacity, we can provision at > >> least the same, if not more, capacity per customer. > >> > >> Other advantages: the $200 ODU is no longer customer equipment and CAPEX, > >> but network equipment, and as such, can operate under a longer break-even > >> timeline, and be financed by infrastructure PE funds, for example. As a > >> result, churn has a much lower financial impact on the operator. > >> > >> The main reason why this wouldn't work today is that EPON, as we know, is > >> synchronous, and requires the OLT to orchestrate the amount of time each > >> ONU can transmit, and when. Having wireless hops and media conversions > >> will > >> introduce latencies which can break down the communications (e.g. one ONU > >> may transmit, get delayed on the radio link, and end up overlapping > >> another > >> ONU that transmitted on the next slot). Thus, either the "magic" box needs > >> to account for this, or an new hybrid EPON-wireless protocol developed. > >> > >> My main point here: the industry is moving away from the unconnected. All > >> the claims I heard and saw at MWC about "connecting the unconnected" had > >> zero resonance with the financial drivers that the unconnected really > >> operate under, on top of IT literacy, digital skills, devices, power... > >> > >> Best, > >> > >> Mike > >> On Mar 14, 2023 at 05:27 +0100, rjmcmahon via Starlink < > >> starlink@lists.bufferbloat.net>, wrote: > >> > >> To change the topic - curious to thoughts on FiWi. > >> > >> Imagine a world with no copper cable called FiWi (Fiber,VCSEL/CMOS > >> Radios, Antennas) and which is point to point inside a building > >> connected to virtualized APs fiber hops away. Each remote radio head > >> (RRH) would consume 5W or less and only when active. No need for things > >> like zigbee, or meshes, or threads as each radio has a fiber connection > >> via Corning's actifi or equivalent. Eliminate the AP/Client power > >> imbalance. Plastics also can house smoke or other sensors. > >> > >> Some reminders from Paul Baran in 1994 (and from David Reed) > >> > >> o) Shorter range rf transceivers connected to fiber could produce a > >> significant improvement - - tremendous improvement, really. > >> o) a mixture of terrestrial links plus shorter range radio links has the > >> effect of increasing by orders and orders of magnitude the amount of > >> frequency spectrum that can be made available. > >> o) By authorizing high power to support a few users to reach slightly > >> longer distances we deprive ourselves of the opportunity to serve the > >> many. > >> o) Communications systems can be built with 10dB ratio > >> o) Digital transmission when properly done allows a small signal to > >> noise ratio to be used successfully to retrieve an error free signal. > >> o) And, never forget, any transmission capacity not used is wasted > >> forever, like water over the dam. Not using such techniques represent > >> lost opportunity. > >> > >> And on waveguides: > >> > >> o) "Fiber transmission loss is ~0.5dB/km for single mode fiber, > >> independent of modulation" > >> o) “Copper cables and PCB traces are very frequency dependent. At > >> 100Gb/s, the loss is in dB/inch." > >> o) "Free space: the power density of the radio waves decreases with the > >> square of distance from the transmitting antenna due to spreading of the > >> electromagnetic energy in space according to the inverse square law" > >> > >> The sunk costs & long-lived parts of FiWi are the fiber and the CPE > >> plastics & antennas, as CMOS radios+ & fiber/laser, e.g. VCSEL could be > >> pluggable, allowing for field upgrades. Just like swapping out SFP in a > >> data center. > >> > >> This approach basically drives out WiFi latency by eliminating shared > >> queues and increases capacity by orders of magnitude by leveraging 10dB > >> in the spatial dimension, all of which is achieved by a physical design. > >> Just place enough RRHs as needed (similar to a pop up sprinkler in an > >> irrigation system.) > >> > >> Start and build this for an MDU and the value of the building improves. > >> Sadly, there seems no way to capture that value other than over long > >> term use. It doesn't matter whether the leader of the HOA tries to > >> capture the value or if a last mile provider tries. The value remains > >> sunk or hidden with nothing on the asset side of the balance sheet. > >> We've got a CAPEX spend that has to be made up via "OPEX returns" over > >> years. > >> > >> But the asset is there. > >> > >> How do we do this? > >> > >> Bob > >> _______________________________________________ > >> Starlink mailing list > >> Starlink@lists.bufferbloat.net > >> https://lists.bufferbloat.net/listinfo/starlink > >> > >> _______________________________________________ > >> Rpm mailing list > >> Rpm@lists.bufferbloat.net > >> https://lists.bufferbloat.net/listinfo/rpm > >> > > > > > > -- > > Come Heckle Mar 6-9 at: https://www.understandinglatency.com > > <https://www.understandinglatency.com/Dave>/ > > Dave Täht CEO, TekLibre, LLC > > -------------- next part -------------- > > An HTML attachment was scrubbed... > > URL: > > <https://lists.bufferbloat.net/pipermail/starlink/attachments/20230317/c9c62be3/attachment.html> > > -------------- next part -------------- > > A non-text attachment was scrubbed... > > Name: Hybrid EPON-Wireless network.png > > Type: image/png > > Size: 149871 bytes > > Desc: not available > > URL: > > <https://lists.bufferbloat.net/pipermail/starlink/attachments/20230317/c9c62be3/attachment.png> > > > > ------------------------------ > > > > Subject: Digest Footer > > > > _______________________________________________ > > Starlink mailing list > > Starlink@lists.bufferbloat.net > > https://lists.bufferbloat.net/listinfo/starlink > > > > > > ------------------------------ > > > > End of Starlink Digest, Vol 24, Issue 39 > > **************************************** > > > _______________________________________________ > Starlink mailing list > Starlink@lists.bufferbloat.net > https://lists.bufferbloat.net/listinfo/starlink -- Come Heckle Mar 6-9 at: https://www.understandinglatency.com/ Dave Täht CEO, TekLibre, LLC ^ permalink raw reply [flat|nested] 14+ messages in thread
* Re: [Starlink] GPON vs Active Fiber Ethernet 2023-03-17 17:05 ` [Starlink] GPON vs Active Fiber Ethernet Dave Taht @ 2023-03-17 20:36 ` Sebastian Moeller 2023-03-17 23:48 ` [Starlink] [LibreQoS] " dan 0 siblings, 1 reply; 14+ messages in thread From: Sebastian Moeller @ 2023-03-17 20:36 UTC (permalink / raw) To: Dave Täht; +Cc: David Fernández, Dave Taht via Starlink, libreqos Hi Dave, > On Mar 17, 2023, at 18:05, Dave Taht via Starlink <starlink@lists.bufferbloat.net> wrote: > > On Fri, Mar 17, 2023 at 9:54 AM David Fernández via Starlink > <starlink@lists.bufferbloat.net> wrote: >> >> Hi Dave, >> >> Telefonica achieved considerable gains in efficiency dismantling the >> copper network (85% gains in energy efficiency). >> >> Read here: https://www.xataka.com/empresas-y-economia/paso-cobre-adsl-a-fibra-ha-sido-beneficioso-para-todos-especialmente-para-telefonica > > I am not prepared to make a coherent argument (although I enjoy them), > but I look at the serialization delay of gpon of 250us and other GPON has no strict 250µs serialization delay, it uses time slots of 250µs... for its accounting... that is IMHO the timescale for the grant-request cycle and considerably below what DOCSIS gets away with today. > potential multiplexing problems, For downstream the OLT simply encrypts with the target ONT's key and "broadcasts it to all ONTs that are listening on the PON-tree. For upstream we have a rather typical request grant scheme like in DOCSIS where the OLT assigns transmit slots to the ONT's so these do not step on each other (the ONTs as far as I can tell can not see/hear each other's transmissions so the OLT needs to arbitrate.) > and go, "yuck". It really, really, > really is the RTT that dominates the performance of all our networking > technologies, and no matter how much bandwidth you have, nearly every > per-sub tech I know of has a floor above 250us today. Multiple hops of > mmwave are particularly bad here. I would assume that the actual delay from sending a request to sending the first bit is probably more than one cycle, so the access delay is likely >> 250µs, compared to other delays this still seems to be quite fine to me... (DSL operate with a 4 KHz "clock" as well, but without request-grant since the last mile is not directly shared*) *) Vectoring bring in a certain fate sharing, but still does not bring request grant delays. > Modern active fiber ethernet is 10000x quicker (nanoseconds!), very > standardized, increasingly low power (with a ton of bang for the > buck/gbit), with gear available everywhere that "just works", > leveraging the past decade of rapid development in the data center, > with USED 1Gbit SFPs going into trashbins everywhere. > > ... while gpon is, if anything, more proprietary than cable, the gear, > more expensive, and did I mention the latency? > > /me dons flame retardant suit No need, I am not a PON fan, but given its cost benefits (power and central office space, a single OLT port can terminate anywhere from 64 (GPON) to 128 (XGSPON) ONTs**, and finally regulatory control***) that is what we are going to get, and honestly it could be worse. I am not sure GPON is more expensive than cable stuff, it seems less proprietary than DOCSIS (which is CableLabs or nothing) and is described in ITU standards. I think there is an open source OLT software stack (voltha?) so this looks not that bad compared to what I know about DOCSIS... and latency wise it smokes DOCSIS... heck look at low-latency docsis instead of tackling the elephant in the room the slow request-grant cycling they essentially added L4S... (they also propose a slight speed-up of the grant mechanism IIRC, but nothing close to 250µs epochs). Regards Sebastian **) The big incumbent over here mosty aims for <= 32 users on an OLT port... ***) An ISP operating PONs can no really be forced to rent out dark fibers to competitors, with a PON realistic worst case is having to offer some sort of bitstream access where the original ISP is still tightly in control. As enduser I do not think this to be a good outcome, yet it seems to factor in technology decisions ISPs make. E.g. deutsche glasfaser started with AON but mostly switched to PON for new build outs. P.S.: One thing I always thought great about any kind of AON is that direct traffic to my neighbors would never have to leave the local switch, but that is not how ISPs over here operate, all links are terminated somewhere semi-centrally (incumbent ~900 places, my ISP ~9 places) and any traffic will only cross over at that central site anyway. > >> >> Regards, >> >> David >> >>> Date: Fri, 17 Mar 2023 09:38:03 -0700 >>> From: Dave Taht <dave.taht@gmail.com> >>> To: Mike Puchol <mike@starlink.sx> >>> Cc: Dave Taht via Starlink <starlink@lists.bufferbloat.net>, Rpm >>> <rpm@lists.bufferbloat.net>, libreqos >>> <libreqos@lists.bufferbloat.net>, bloat <bloat@lists.bufferbloat.net> >>> Subject: Re: [Starlink] [Rpm] On FiWi >>> Message-ID: >>> <CAA93jw6EWH19Jo-pUJMX7QCi=GfHD8iWTDKCcRY=0tEOe4Vt1Q@mail.gmail.com> >>> Content-Type: text/plain; charset="utf-8" >>> >>> This is a pretty neat box: >>> >>> https://mikrotik.com/product/netpower_lite_7r >>> >>> What are the compelling arguments for fiber vs copper, again? >>> >>> >>> On Tue, Mar 14, 2023 at 4:10 AM Mike Puchol via Rpm < >>> rpm@lists.bufferbloat.net> wrote: >>> >>>> Hi Bob, >>>> >>>> You hit on a set of very valid points, which I'll complement with my views >>>> on where the industry (the bit of it that affects WISPs) is heading, and >>>> what I saw at the MWC in Barcelona. Love the FiWi term :-) >>>> >>>> I have seen the vendors that supply WISPs, such as Ubiquiti, Cambium, and >>>> Mimosa, but also newer entrants such as Tarana, increase the performance >>>> and on-paper specs of their equipment. My examples below are centered on >>>> the African market, if you operate in Europe or the US, where you can >>>> charge customers a higher install fee, or even charge them a break-up fee >>>> if they don't return equipment, the economics work. >>>> >>>> Where currently a ~$500 sector radio could serve ~60 endpoints, at a cost >>>> of ~$50 per endpoint (I use this term in place of ODU/CPE, the antenna >>>> that >>>> you mount on the roof), and supply ~2.5 Mbps CIR per endpoint, the >>>> evolution is now a ~$2,000+ sector radio, a $200 endpoint, capability for >>>> ~150 endpoints per sector, and ~25 Mbps CIR per endpoint. >>>> >>>> If every customer a WISP installs represents, say, $100 CAPEX at install >>>> time ($50 for the antenna + cabling, router, etc), and you charge a $30 >>>> install fee, you have $70 to recover, and you recover from the monthly >>>> contribution the customer makes. If the contribution after OPEX is, say, >>>> $10, it takes you 7 months to recover the full install cost. Not bad, >>>> doable even in low-income markets. >>>> >>>> Fast-forward to the next-generation version. Now, the CAPEX at install is >>>> $250, you need to recover $220, and it will take you 22 months, which is >>>> above the usual 18 months that investors look for. >>>> >>>> The focus, thereby, has to be the lever that has the largest effect on the >>>> unit economics - which is the per-customer cost. I have drawn what my >>>> ideal >>>> FiWi network would look like: >>>> >>>> >>>> >>>> Taking you through this - we start with a 1-port, low-cost EPON OLT (or >>>> you could go for 2, 4, 8 ports as you add capacity). This OLT has capacity >>>> for 64 ONUs on its single port. Instead of connecting the typical fiber >>>> infrastructure with kilometers of cables which break, require maintenance, >>>> etc. we insert an EPON to Ethernet converter (I added "magic" because >>>> these >>>> don't exist AFAIK). >>>> >>>> This converter allows us to connect our $2k sector radio, and serve the >>>> $200 endpoints (ODUs) over wireless point-to-multipoint up to 10km away. >>>> Each ODU then has a reverse converter, which gives us EPON again. >>>> >>>> Once we are back on EPON, we can insert splitters, for example, >>>> pre-connectorized outdoor 1:16 boxes. Every customer install now involves >>>> a >>>> 100 meter roll of pre-connectorized 2-core drop cable, and a $20 EPON ONU. >>>> >>>> Using this deployment method, we could connect up to 16 customers to a >>>> single $200 endpoint, so the enpoint CAPEX per customer is now $12.5. Add >>>> the ONU, cable, etc. and we have a per-install CAPEX of $82.5 (assuming >>>> the >>>> same $50 of extras we had before), and an even shorter break-even. In >>>> addition, as the endpoints support higher capacity, we can provision at >>>> least the same, if not more, capacity per customer. >>>> >>>> Other advantages: the $200 ODU is no longer customer equipment and CAPEX, >>>> but network equipment, and as such, can operate under a longer break-even >>>> timeline, and be financed by infrastructure PE funds, for example. As a >>>> result, churn has a much lower financial impact on the operator. >>>> >>>> The main reason why this wouldn't work today is that EPON, as we know, is >>>> synchronous, and requires the OLT to orchestrate the amount of time each >>>> ONU can transmit, and when. Having wireless hops and media conversions >>>> will >>>> introduce latencies which can break down the communications (e.g. one ONU >>>> may transmit, get delayed on the radio link, and end up overlapping >>>> another >>>> ONU that transmitted on the next slot). Thus, either the "magic" box needs >>>> to account for this, or an new hybrid EPON-wireless protocol developed. >>>> >>>> My main point here: the industry is moving away from the unconnected. All >>>> the claims I heard and saw at MWC about "connecting the unconnected" had >>>> zero resonance with the financial drivers that the unconnected really >>>> operate under, on top of IT literacy, digital skills, devices, power... >>>> >>>> Best, >>>> >>>> Mike >>>> On Mar 14, 2023 at 05:27 +0100, rjmcmahon via Starlink < >>>> starlink@lists.bufferbloat.net>, wrote: >>>> >>>> To change the topic - curious to thoughts on FiWi. >>>> >>>> Imagine a world with no copper cable called FiWi (Fiber,VCSEL/CMOS >>>> Radios, Antennas) and which is point to point inside a building >>>> connected to virtualized APs fiber hops away. Each remote radio head >>>> (RRH) would consume 5W or less and only when active. No need for things >>>> like zigbee, or meshes, or threads as each radio has a fiber connection >>>> via Corning's actifi or equivalent. Eliminate the AP/Client power >>>> imbalance. Plastics also can house smoke or other sensors. >>>> >>>> Some reminders from Paul Baran in 1994 (and from David Reed) >>>> >>>> o) Shorter range rf transceivers connected to fiber could produce a >>>> significant improvement - - tremendous improvement, really. >>>> o) a mixture of terrestrial links plus shorter range radio links has the >>>> effect of increasing by orders and orders of magnitude the amount of >>>> frequency spectrum that can be made available. >>>> o) By authorizing high power to support a few users to reach slightly >>>> longer distances we deprive ourselves of the opportunity to serve the >>>> many. >>>> o) Communications systems can be built with 10dB ratio >>>> o) Digital transmission when properly done allows a small signal to >>>> noise ratio to be used successfully to retrieve an error free signal. >>>> o) And, never forget, any transmission capacity not used is wasted >>>> forever, like water over the dam. Not using such techniques represent >>>> lost opportunity. >>>> >>>> And on waveguides: >>>> >>>> o) "Fiber transmission loss is ~0.5dB/km for single mode fiber, >>>> independent of modulation" >>>> o) “Copper cables and PCB traces are very frequency dependent. At >>>> 100Gb/s, the loss is in dB/inch." >>>> o) "Free space: the power density of the radio waves decreases with the >>>> square of distance from the transmitting antenna due to spreading of the >>>> electromagnetic energy in space according to the inverse square law" >>>> >>>> The sunk costs & long-lived parts of FiWi are the fiber and the CPE >>>> plastics & antennas, as CMOS radios+ & fiber/laser, e.g. VCSEL could be >>>> pluggable, allowing for field upgrades. Just like swapping out SFP in a >>>> data center. >>>> >>>> This approach basically drives out WiFi latency by eliminating shared >>>> queues and increases capacity by orders of magnitude by leveraging 10dB >>>> in the spatial dimension, all of which is achieved by a physical design. >>>> Just place enough RRHs as needed (similar to a pop up sprinkler in an >>>> irrigation system.) >>>> >>>> Start and build this for an MDU and the value of the building improves. >>>> Sadly, there seems no way to capture that value other than over long >>>> term use. It doesn't matter whether the leader of the HOA tries to >>>> capture the value or if a last mile provider tries. The value remains >>>> sunk or hidden with nothing on the asset side of the balance sheet. >>>> We've got a CAPEX spend that has to be made up via "OPEX returns" over >>>> years. >>>> >>>> But the asset is there. >>>> >>>> How do we do this? >>>> >>>> Bob >>>> _______________________________________________ >>>> Starlink mailing list >>>> Starlink@lists.bufferbloat.net >>>> https://lists.bufferbloat.net/listinfo/starlink >>>> >>>> _______________________________________________ >>>> Rpm mailing list >>>> Rpm@lists.bufferbloat.net >>>> https://lists.bufferbloat.net/listinfo/rpm >>>> >>> >>> >>> -- >>> Come Heckle Mar 6-9 at: https://www.understandinglatency.com >>> <https://www.understandinglatency.com/Dave>/ >>> Dave Täht CEO, TekLibre, LLC >>> -------------- next part -------------- >>> An HTML attachment was scrubbed... >>> URL: >>> <https://lists.bufferbloat.net/pipermail/starlink/attachments/20230317/c9c62be3/attachment.html> >>> -------------- next part -------------- >>> A non-text attachment was scrubbed... >>> Name: Hybrid EPON-Wireless network.png >>> Type: image/png >>> Size: 149871 bytes >>> Desc: not available >>> URL: >>> <https://lists.bufferbloat.net/pipermail/starlink/attachments/20230317/c9c62be3/attachment.png> >>> >>> ------------------------------ >>> >>> Subject: Digest Footer >>> >>> _______________________________________________ >>> Starlink mailing list >>> Starlink@lists.bufferbloat.net >>> https://lists.bufferbloat.net/listinfo/starlink >>> >>> >>> ------------------------------ >>> >>> End of Starlink Digest, Vol 24, Issue 39 >>> **************************************** >>> >> _______________________________________________ >> Starlink mailing list >> Starlink@lists.bufferbloat.net >> https://lists.bufferbloat.net/listinfo/starlink > > > > -- > Come Heckle Mar 6-9 at: https://www.understandinglatency.com/ > Dave Täht CEO, TekLibre, LLC > _______________________________________________ > Starlink mailing list > Starlink@lists.bufferbloat.net > https://lists.bufferbloat.net/listinfo/starlink ^ permalink raw reply [flat|nested] 14+ messages in thread
* Re: [Starlink] [LibreQoS] GPON vs Active Fiber Ethernet 2023-03-17 20:36 ` Sebastian Moeller @ 2023-03-17 23:48 ` dan 0 siblings, 0 replies; 14+ messages in thread From: dan @ 2023-03-17 23:48 UTC (permalink / raw) To: Sebastian Moeller Cc: Dave Täht, Dave Taht via Starlink, David Fernández, libreqos [-- Attachment #1: Type: text/plain, Size: 2312 bytes --] per copper vs gpon. There are a lot of parts to this but I think it's safe to say that any *DSL product is inferior to ethernet or gpon so aren't part of the conversation. We're really talking ethernet vs *GPON here. No other fiber options are widespread and viable for most. I don't want to play both sides here so I'm just talking pros on 'ethernet'. not 'copper'... but also copper. Ethernet lives on copper or fiber. Copper 'last meter' is cheap, CHEAPER than any fiber product. Copper is cheaper until you hit 100m and then fiber wins. Ethernet is near wire speed *routed* on a number of modern and weather resistant outdoor products. Backhauling on multi-strand fiber eliminates one primary negative with copper in that cost over 100m number. There's likely some wash in having fiber to the home and the cost of termination and ONUs vs PoE injectors in home pushing up to powered switches. Pro for powered switch is that routing option. Dramatically easier (as in, it's actually possible) to build rings and meshy routed networks on ethernet allowing for much more backhoe-fade safe networks. While not as future proof as fiber strands to the door, it's capable of 1G, 2.5G today and really 10G for the most part though there is a lack of hardware with those ports so leave that up in the air. XGSPON wins the max per port speed here, but that same network with active ethernet over fiber backhauls and copper can EASILY do 100G on the backhaul and 2.5G/port and even go hybrid with mostly copper last meter and some active fiber off 10,40,100G ports when profitable. It's not all roses, but there are real world scenarios where a methodical buildout of ethernet can be a better choice especially if we're talking about maximum performance. I don't want to lean too heavily on mikrotik here, lots of people aren't in love with them, but they are definitely pushing boundaries here. https://mikrotik.com/product/crs504_4xq_out 4x100G switch, outdoor grade, supports 4x breakout cables so can do 4x4x25G or 2x100G feeds + 2x4x25 or 2x4x10G on a Marvell Prestera switch (presents as individual interfaces). XGSPON can't touch it. Heck, you could do remote XGSPON with a TIBIT port if you really wanted to, or feed an Netpower 7R units with 10Gbps each and get reverse PoE to power everything. [-- Attachment #2: Type: text/html, Size: 2620 bytes --] ^ permalink raw reply [flat|nested] 14+ messages in thread
[parent not found: <mailman.2651.1672779463.1281.starlink@lists.bufferbloat.net>]
* Re: [Starlink] Researchers Seeking Probe Volunteers in USA [not found] <mailman.2651.1672779463.1281.starlink@lists.bufferbloat.net> @ 2023-01-03 22:58 ` David P. Reed 2023-01-09 14:44 ` Livingood, Jason 2023-01-09 18:54 ` [Starlink] [EXTERNAL] " Livingood, Jason 1 sibling, 1 reply; 14+ messages in thread From: David P. Reed @ 2023-01-03 22:58 UTC (permalink / raw) To: starlink [-- Attachment #1: Type: text/plain, Size: 9233 bytes --] A serious question: > ... The QMap Probe is > preconfigured to automatically test various network metrics with little burden on > your available bandwidth. Those of us here, like me and Dave Taht, who have measured the big elephants in the room (esp. for Starlink) like "lag under load" and "fairness with respect to competing traffic on the same <link>" probably were not consulted, if the goal is "little burden on your available bandwidth". I've spent many years reading papers about "low cost metrics" for lag and fairness in the Internet context, starting with the old "packet-pair" techniques, and basically they are almost impossible to interpret and compare between service provider architectures. It's hard enough to compare DOCSIS 3 setups with other DOCSIS 3 CMTS's in other cities, or LTE data networks between different cities. Frankly, I expect the results will be treated like other "quality metrics" - J.D. Power comes to mind from consulting experience in the automotive industry - and be cherry-picked to distort the results. > This data is used to estimate the quality of internet > service. I have NEVER seen a technical definition of "quality of service" that made sense in terms of how the users experience their use of the Internet. It would be wonderful if such a definition actually existed. So how does relative "estimation" of an undefined concept work? What questions really matter to users, in particular? Well, "availability" might matter, but availability is relative to "momentary need". A network that is 99.9% available, but the 0.1% of the time that the user NEEDS it is what matters to the user, not the rest of the 86,400 seconds each day. [As an aside, in a proceeding I participated under the CRTC, Canada's "FCC" regulator on Network Management that focused on "quality", we queried that since none of the operators in Canada actually measured "response time" of their networks in any way, so how could they know that they were improving service? The response on the record from some of the largest Broadband ISPs in Canada was discouraging. They said I was wrong, and that they constantly measured "utilization" of the network capacity at every router, and the *average* utilization was almost always < 85%. They then invoked Little's Lemma in queueing theory to say that proved that the quality of service was *perfect*. This was in a legal regulatory proceeding, *under oath*. I just cannot understand how folks technical enough to invoke Little's Lemma could be so ignorant. Little's Lemma isn't at all good at converting "average utilization" to "user experienced lag under load", it's mathematically *invalid*. But what is worse is that they had no idea of what user experienced "quality" was. It's like a software vendor saying they have no bugs, that they know about, when they have no way for users to report bugs at all. OR in the modern context, where reporting bugs is a hassle and there's no "bug bounty" or expectation that the company will fix a reported bug in a timely manner.] > A public report of our findings will be published on our website in 2023. By all means participate if you want, but I suspect that the "raw data" will not be made available, and looking at the existing reports, it will be hard to extract meaningful comparisons relevant to real user experience at the test sites. > Please check out some of our existing reports to get a better feel of what we > measure: > https://www.netforecast.com/audit-reports/<https://urldefense.com/v3/__https:/www.netforecast.com/audit-reports/__;!!CQl3mcHX2A!FrL2Yijo-63gS4PMToq0adfntj2fhza8ekyba1EbS8-tCgsQpg5MsIAYAvP5xUzLdDRa667bslUTtw_s0WpvvBpJEFKpAJeQfQ$>. > > The QMap Probe requires no regular maintenance or monitoring by you. It may > occasionally need rebooting (turning off and on), and we would contact you via > email or text to request this. The device sends various test packets to the > internet and records their response characteristics. Our device has no knowledge > of -- and does not communicate out -- any information about you or any devices in > your home. > > We will include a prepaid shipping label for returning the QMap Probe in the > original box (please keep this!). Once we receive the device back, we will send > you a $200 Amazon gift card (one per household). > > To volunteer, please fill out this relatively painless survey: > https://www.surveymonkey.com/r/8VZSB3M<https://urldefense.com/v3/__https:/www.surveymonkey.com/r/8VZSB3M__;!!CQl3mcHX2A!FrL2Yijo-63gS4PMToq0adfntj2fhza8ekyba1EbS8-tCgsQpg5MsIAYAvP5xUzLdDRa667bslUTtw_s0WpvvBpJEFJ_EHoUnA$>. > Thank you! > > ///END/// > -------------- next part -------------- > An HTML attachment was scrubbed... > URL: > <https://lists.bufferbloat.net/pipermail/starlink/attachments/20230103/aa1e6019/attachment-0001.html> > > ------------------------------ > > Message: 2 > Date: Tue, 3 Jan 2023 15:57:30 -0500 > From: Vint Cerf <vint@google.com> > To: "Livingood, Jason" <Jason_Livingood@comcast.com> > Cc: Dave Taht via Starlink <starlink@lists.bufferbloat.net> > Subject: Re: [Starlink] Researchers Seeking Probe Volunteers in USA > Message-ID: > <CAHxHgge6sTffAqaMLv7z1k0ZnYtWw7s+OgXBJOBnm5zAwHjR+w@mail.gmail.com> > Content-Type: text/plain; charset="utf-8" > > netforecast was started by a good friend of mine - they are first rate. > > v > > > On Tue, Jan 3, 2023 at 3:53 PM Livingood, Jason via Starlink < > starlink@lists.bufferbloat.net> wrote: > > > Forwarding on from a group doing some Starlink research. I am aware of at > > least one other researcher that will soon do the same and will forward that > > later (guessing a week or two). > > > > > > > > Jason > > > > ///FORWARD/// > > > > We need volunteers! NetForecast, a leader in measuring the quality of > > internet service, is conducting a performance study of several types of > > internet delivery technologies, including low-earth-orbit satellite like > > Starlink. > > > > > > > > As a volunteer, you will host one of our proprietary QMap Probes in your > > home network. This will connect to the internet via an available ethernet > > port on your gateway/router and plug into a standard power outlet. The QMap > > Probe is preconfigured to automatically test various network metrics with > > little burden on your available bandwidth. This data is used to estimate > > the quality of internet service. A public report of our findings will be > > published on our website in 2023. Please check out some of our existing > > reports to get a better feel of what we measure: > > https://www.netforecast.com/audit-reports/ > > > <https://urldefense.com/v3/__https:/www.netforecast.com/audit-reports/__;!!CQl3mcHX2A!FrL2Yijo-63gS4PMToq0adfntj2fhza8ekyba1EbS8-tCgsQpg5MsIAYAvP5xUzLdDRa667bslUTtw_s0WpvvBpJEFKpAJeQfQ$> > > . > > > > > > > > The QMap Probe requires no regular maintenance or monitoring by you. It > > may occasionally need rebooting (turning off and on), and we would contact > > you via email or text to request this. The device sends various test > > packets to the internet and records their response characteristics. Our > > device has no knowledge of -- and does not communicate out -- any > > information about you or any devices in your home. > > > > > > > > We will include a prepaid shipping label for returning the QMap Probe in > > the original box (please keep this!). Once we receive the device back, we > > will send you a $200 Amazon gift card (one per household). > > > > > > > > To volunteer, please fill out this relatively painless survey: > > https://www.surveymonkey.com/r/8VZSB3M > > > <https://urldefense.com/v3/__https:/www.surveymonkey.com/r/8VZSB3M__;!!CQl3mcHX2A!FrL2Yijo-63gS4PMToq0adfntj2fhza8ekyba1EbS8-tCgsQpg5MsIAYAvP5xUzLdDRa667bslUTtw_s0WpvvBpJEFJ_EHoUnA$>. > > Thank you! > > > > > > > > ///END/// > > _______________________________________________ > > Starlink mailing list > > Starlink@lists.bufferbloat.net > > https://lists.bufferbloat.net/listinfo/starlink > > > > > -- > Please send any postal/overnight deliveries to: > Vint Cerf > Google, LLC > 1900 Reston Metro Plaza, 16th Floor > Reston, VA 20190 > +1 (571) 213 1346 > > > until further notice > -------------- next part -------------- > An HTML attachment was scrubbed... > URL: > <https://lists.bufferbloat.net/pipermail/starlink/attachments/20230103/e49cfc9f/attachment.html> > -------------- next part -------------- > A non-text attachment was scrubbed... > Name: smime.p7s > Type: application/pkcs7-signature > Size: 3995 bytes > Desc: S/MIME Cryptographic Signature > URL: > <https://lists.bufferbloat.net/pipermail/starlink/attachments/20230103/e49cfc9f/attachment.bin> > > ------------------------------ > > Subject: Digest Footer > > _______________________________________________ > Starlink mailing list > Starlink@lists.bufferbloat.net > https://lists.bufferbloat.net/listinfo/starlink > > > ------------------------------ > > End of Starlink Digest, Vol 22, Issue 6 > *************************************** > [-- Attachment #2: Type: text/html, Size: 13560 bytes --] ^ permalink raw reply [flat|nested] 14+ messages in thread
* Re: [Starlink] Researchers Seeking Probe Volunteers in USA 2023-01-03 22:58 ` [Starlink] Researchers Seeking Probe Volunteers in USA David P. Reed @ 2023-01-09 14:44 ` Livingood, Jason 2023-01-09 15:26 ` Dave Taht 0 siblings, 1 reply; 14+ messages in thread From: Livingood, Jason @ 2023-01-09 14:44 UTC (permalink / raw) To: David P. Reed, starlink; +Cc: mike.reynolds [-- Attachment #1: Type: text/plain, Size: 1428 bytes --] > Those of us here, like me and Dave Taht, who have measured the big elephants in the room (esp. for Starlink) like "lag under load" and "fairness with respect to competing traffic on the same <link>" probably were not consulted, if the goal is "little burden on your available bandwidth". I don’t have specifics for their test config, but most of the platforms would determine ‘little burden’ by looking for cross traffic (aka user demand on the connection) and if it is non-existent/low then running tests that can highly utilize the link capacity – whether for a working latency test or whatever. > Frankly, I expect the results will be treated like other "quality metrics" - J.D. Power comes to mind from consulting experience in the automotive industry - and be cherry-picked to distort the results. I dunno – I think the research & measurement community seems to be coalescing around certain types of working latency / responsiveness measures as being pretty good & predictive of real end user application QoE. > By all means participate if you want, but I suspect that the "raw data" will not be made available, and looking at the existing reports, it will be hard to extract meaningful comparisons relevant to real user experience at the test sites. Not sure if the raw data will be available. Even if not, they may publish the parameters of the tests themselves. JL [-- Attachment #2: Type: text/html, Size: 4222 bytes --] ^ permalink raw reply [flat|nested] 14+ messages in thread
* Re: [Starlink] Researchers Seeking Probe Volunteers in USA 2023-01-09 14:44 ` Livingood, Jason @ 2023-01-09 15:26 ` Dave Taht 0 siblings, 0 replies; 14+ messages in thread From: Dave Taht @ 2023-01-09 15:26 UTC (permalink / raw) To: Livingood, Jason Cc: David P. Reed, starlink, mike.reynolds, Rpm, bloat, libreqos I have many kvetches about the new latency under load tests being designed and distributed over the past year. I am delighted! that they are happening, but most really need third party evaluation, and calibration, and a solid explanation of what network pathologies they do and don't cover. Also a RED team attitude towards them, as well as thinking hard about what you are not measuring (operations research). I actually rather love the new cloudflare speedtest, because it tests a single TCP connection, rather than dozens, and at the same time folk are complaining that it doesn't find the actual "speed!". yet... the test itself more closely emulates a user experience than speedtest.net does. I am personally pretty convinced that the fewer numbers of flows that a web page opens improves the likelihood of a good user experience, but lack data on it. To try to tackle the evaluation and calibration part, I've reached out to all the new test designers in the hope that we could get together and produce a report of what each new test is actually doing. I've tweeted, linked in, emailed, and spammed every measurement list I know of, and only to some response, please reach out to other test designer folks and have them join the rpm email list? My principal kvetches in the new tests so far are: 0) None of the tests last long enough. Ideally there should be a mode where they at least run to "time of first loss", or periodically, just run longer than the industry-stupid^H^H^H^H^H^Hstandard 20 seconds. There be dragons there! It's really bad science to optimize the internet for 20 seconds. It's like optimizing a car, to handle well, for just 20 seconds. 1) Not testing up + down + ping at the same time None of the new tests actually test the same thing that the infamous rrul test does - all the others still test up, then down, and ping. It was/remains my hope that the simpler parts of the flent test suite - such as the tcp_up_squarewave tests, the rrul test, and the rtt_fair tests would provide calibration to the test designers. we've got zillions of flent results in the archive published here: https://blog.cerowrt.org/post/found_in_flent/ The new tests have all added up + ping and down + ping, but not up + down + ping. Why?? The behaviors of what happens in that case are really non-intuitive, I know, but... it's just one more phase to add to any one of those new tests. I'd be deliriously happy if someone(s) new to the field started doing that, even optionally, and boggled at how it defeated their assumptions. Among other things that would show... It's the home router industry's dirty secret than darn few "gigabit" home routers can actually forward in both directions at a gigabit. I'd like to smash that perception thoroughly, but given our starting point is a gigabit router was a "gigabit switch" - and historically been something that couldn't even forward at 200Mbit - we have a long way to go there. Only in the past year have non-x86 home routers appeared that could actually do a gbit in both directions. 2) Few are actually testing within-stream latency Apple's rpm project is making a stab in that direction. It looks highly likely, that with a little more work, crusader and go-responsiveness can finally start sampling the tcp RTT, loss and markings, more directly. As for the rest... sampling TCP_INFO on windows, and Linux, at least, always appeared simple to me, but I'm discovering how hard it is by delving deep into the rust behind crusader. the goresponsiveness thing is also IMHO running WAY too many streams at the same time, I guess motivated by an attempt to have the test complete quickly? B) To try and tackle the validation problem: In the libreqos.io project we've established a testbed where tests can be plunked through various ISP plan network emulations. It's here: https://payne.taht.net (run bandwidth test for what's currently hooked up) We could rather use an AS number and at least a ipv4/24 and ipv6/48 to leverage with that, so I don't have to nat the various emulations. (and funding, anyone got funding?) Or, as the code is GPLv2 licensed, to see more test designers setup a testbed like this to calibrate their own stuff. Presently we're able to test: flent netperf iperf2 iperf3 speedtest-cli crusader the broadband forum udp based test: https://github.com/BroadbandForum/obudpst trexx There's also a virtual machine setup that we can remotely drive a web browser from (but I didn't want to nat the results to the world) to test other web services. ^ permalink raw reply [flat|nested] 14+ messages in thread
* Re: [Starlink] [EXTERNAL] Re: Researchers Seeking Probe Volunteers in USA 2023-01-09 15:26 ` Dave Taht (?) @ 2023-01-09 18:54 ` Livingood, Jason 2023-01-09 19:19 ` [Starlink] [Rpm] " rjmcmahon -1 siblings, 1 reply; 14+ messages in thread From: Livingood, Jason @ 2023-01-09 18:54 UTC (permalink / raw) To: Dave Taht; +Cc: starlink, Rpm, bloat, libreqos > 0) None of the tests last long enough. The user-initiated ones tend to be shorter - likely because the average user does not want to wait several minutes for a test to complete. But IMO this is where a test platform like SamKnows, Ookla's embedded client, NetMicroscope, and others can come in - since they run in the background on some randomized schedule w/o user intervention. Thus, the user's time-sensitivity is no longer a factor and a longer duration test can be performed. > 1) Not testing up + down + ping at the same time You should consider publishing a LUL BCP I-D in the IRTF/IETF - like in IPPM... JL ^ permalink raw reply [flat|nested] 14+ messages in thread
* Re: [Starlink] [Rpm] [EXTERNAL] Re: Researchers Seeking Probe Volunteers in USA 2023-01-09 18:54 ` [Starlink] [EXTERNAL] " Livingood, Jason @ 2023-01-09 19:19 ` rjmcmahon 2023-01-09 19:56 ` [Starlink] [LibreQoS] " dan 0 siblings, 1 reply; 14+ messages in thread From: rjmcmahon @ 2023-01-09 19:19 UTC (permalink / raw) To: Livingood, Jason; +Cc: Dave Taht, starlink, Rpm, libreqos, bloat User based, long duration tests seem fundamentally flawed. QoE for users is driven by user expectations. And if a user won't wait on a long test they for sure aren't going to wait minutes for a web page download. If it's a long duration use case, e.g. a file download, then latency isn't typically driving QoE. Not: Even for internal tests, we try to keep our automated tests down to 2 seconds. There are reasons to test for minutes (things like phy cals in our chips) but it's more of the exception than the rule. Bob >> 0) None of the tests last long enough. > > The user-initiated ones tend to be shorter - likely because the > average user does not want to wait several minutes for a test to > complete. But IMO this is where a test platform like SamKnows, Ookla's > embedded client, NetMicroscope, and others can come in - since they > run in the background on some randomized schedule w/o user > intervention. Thus, the user's time-sensitivity is no longer a factor > and a longer duration test can be performed. > >> 1) Not testing up + down + ping at the same time > > You should consider publishing a LUL BCP I-D in the IRTF/IETF - like in > IPPM... > > JL > > _______________________________________________ > Rpm mailing list > Rpm@lists.bufferbloat.net > https://lists.bufferbloat.net/listinfo/rpm ^ permalink raw reply [flat|nested] 14+ messages in thread
* Re: [Starlink] [LibreQoS] [Rpm] [EXTERNAL] Re: Researchers Seeking Probe Volunteers in USA 2023-01-09 19:19 ` [Starlink] [Rpm] " rjmcmahon @ 2023-01-09 19:56 ` dan 2023-03-13 10:02 ` [Starlink] [Rpm] [LibreQoS] " Sebastian Moeller 0 siblings, 1 reply; 14+ messages in thread From: dan @ 2023-01-09 19:56 UTC (permalink / raw) To: rjmcmahon; +Cc: Livingood, Jason, starlink, Rpm, bloat, libreqos I'm not offering a complete solution here.... I'm not so keen on speed tests. It's akin to testing your car's performance by flooring it til you hit the governor and hard breaking til you stop *while in traffic*. That doesn't demonstrate the utility of the car. Data is already being transferred, let's measure that. Doing some routine simple tests intentionally during low, mid, high congestion periods to see how the service is actually performing for the end user. You don't need to generate the traffic on a link to measure how much traffic a link can handle. And determining congestion on a service in a fairly rudimentary way would be frequent latency tests to 'known good' service ie high capacity services that are unlikely to experience congestion. There are few use cases that matche a 2 minute speed test outside of 'wonder what my internet connection can do'. And in those few use cases such as a big file download, a routine latency test is a really great measure of the quality of a service. Sure, troubleshooting by the ISP might include a full bore multi-minute speed test but that's really not useful for the consumer. Further, exposing this data to the end users, IMO, is likely better as a chart of congestion and flow durations and some scoring. ie, slice out 7-8pm, during this segment you were able to pull 427Mbps without congestion, netflix or streaming service use approximately 6% of capacity. Your service was busy for 100% of this time ( likely measuring buffer bloat ). Expressed as a pretty chart with consumer friendly language. When you guys are talking about per segment latency testing, you're really talking about metrics for operators to be concerned with, not end users. It's useless information for them. I had a woman about 2 months ago complain about her frame rates because her internet connection was 15 emm ess's and that was terrible and I needed to fix it. (slow computer was the problem, obviously) but that data from speedtest.net didn't actually help her at all, it just confused her. Running timed speed tests at 3am (Eero, I'm looking at you) is pretty pointless. Running speed tests during busy hours is a little bit harmful overall considering it's pushing into oversells on every ISP. I could talk endlessly about how useless speed tests are to end user experience. On Mon, Jan 9, 2023 at 12:20 PM rjmcmahon via LibreQoS <libreqos@lists.bufferbloat.net> wrote: > > User based, long duration tests seem fundamentally flawed. QoE for users > is driven by user expectations. And if a user won't wait on a long test > they for sure aren't going to wait minutes for a web page download. If > it's a long duration use case, e.g. a file download, then latency isn't > typically driving QoE. > > Not: Even for internal tests, we try to keep our automated tests down to > 2 seconds. There are reasons to test for minutes (things like phy cals > in our chips) but it's more of the exception than the rule. > > Bob > >> 0) None of the tests last long enough. > > > > The user-initiated ones tend to be shorter - likely because the > > average user does not want to wait several minutes for a test to > > complete. But IMO this is where a test platform like SamKnows, Ookla's > > embedded client, NetMicroscope, and others can come in - since they > > run in the background on some randomized schedule w/o user > > intervention. Thus, the user's time-sensitivity is no longer a factor > > and a longer duration test can be performed. > > > >> 1) Not testing up + down + ping at the same time > > > > You should consider publishing a LUL BCP I-D in the IRTF/IETF - like in > > IPPM... > > > > JL > > > > _______________________________________________ > > Rpm mailing list > > Rpm@lists.bufferbloat.net > > https://lists.bufferbloat.net/listinfo/rpm > _______________________________________________ > LibreQoS mailing list > LibreQoS@lists.bufferbloat.net > https://lists.bufferbloat.net/listinfo/libreqos ^ permalink raw reply [flat|nested] 14+ messages in thread
* Re: [Starlink] [Rpm] [LibreQoS] [EXTERNAL] Re: Researchers Seeking Probe Volunteers in USA 2023-01-09 19:56 ` [Starlink] [LibreQoS] " dan @ 2023-03-13 10:02 ` Sebastian Moeller 2023-03-13 15:08 ` Jeremy Austin 0 siblings, 1 reply; 14+ messages in thread From: Sebastian Moeller @ 2023-03-13 10:02 UTC (permalink / raw) To: dan Cc: rjmcmahon, Dave Taht via Starlink, Rpm, Livingood, Jason, libreqos, bloat Hi Dan, > On Jan 9, 2023, at 20:56, dan via Rpm <rpm@lists.bufferbloat.net> wrote: > > I'm not offering a complete solution here.... I'm not so keen on > speed tests. It's akin to testing your car's performance by flooring > it til you hit the governor and hard breaking til you stop *while in > traffic*. That doesn't demonstrate the utility of the car. > > Data is already being transferred, let's measure that. [SM] For a home link that means you need to measure on the router, as end-hosts will only ever see the fraction of traffic they sink/source themselves... > Doing some > routine simple tests intentionally during low, mid, high congestion > periods to see how the service is actually performing for the end > user. [SM] No ISP I know of publishes which periods are low, mid, high congestion so end-users will need to make some assumptions here (e.g. by looking at per day load graphs of big traffic exchanges like DE-CIX here https://www.de-cix.net/en/locations/frankfurt/statistics ) > You don't need to generate the traffic on a link to measure how > much traffic a link can handle. [SM] OK, I will bite, how do you measure achievable throughput without actually generating it? Packet-pair techniques are notoriously imprecise and have funny failure modes. > And determining congestion on a > service in a fairly rudimentary way would be frequent latency tests to > 'known good' service ie high capacity services that are unlikely to > experience congestion. [SM] Yes, that sort of works, see e.g. https://github.com/lynxthecat/cake-autorate for a home-made approach by non-networking people to estimate whether the immediate load is at capacity or not, and using that information to control a traffic shaper to "bound" latency under load. > > There are few use cases that matche a 2 minute speed test outside of > 'wonder what my internet connection can do'. [SM] I would have agreed some months ago, but ever since the kids started to play more modern games than tetris/minecraft long duration multi-flow downloads have become a staple in our networking. OK, noone really cares about the intra-flow latency of these download flows, but we do care that the rest of our traffic stays responsive. > And in those few use > cases such as a big file download, a routine latency test is a really > great measure of the quality of a service. Sure, troubleshooting by > the ISP might include a full bore multi-minute speed test but that's > really not useful for the consumer. [SM] I mildly disagree, if it is informative for the ISP's technicians it is also informative for the end-customers; not all ISPs are so enlightened that they pro-actively solve issues for their customers (but some are!) so occasionally it helps to be able to do such diagnostic measurements one-self. > > Further, exposing this data to the end users, IMO, is likely better as > a chart of congestion and flow durations and some scoring. ie, slice > out 7-8pm, during this segment you were able to pull 427Mbps without > congestion, netflix or streaming service use approximately 6% of > capacity. Your service was busy for 100% of this time ( likely > measuring buffer bloat ). Expressed as a pretty chart with consumer > friendly language. [SM] Sounds nice. > When you guys are talking about per segment latency testing, you're > really talking about metrics for operators to be concerned with, not > end users. It's useless information for them. [SM] Well is it really useless? If I know the to be expected latency-under-load increase I can eye-ball e.h. how far away a server I can still interact with in a "snappy" way. > I had a woman about 2 > months ago complain about her frame rates because her internet > connection was 15 emm ess's and that was terrible and I needed to fix > it. (slow computer was the problem, obviously) but that data from > speedtest.net didn't actually help her at all, it just confused her. [SM The solution to lack of knowledge, IMHO should be to teach people what they need to know, not hide information that could be mis-interpreted (because that applies to all information). > > Running timed speed tests at 3am (Eero, I'm looking at you) is pretty > pointless. [SM] I would argue that this is likely a decent period to establish baseline values for uncongested conditions (that is uncongested by other traffic sources than the measuring network). > Running speed tests during busy hours is a little bit > harmful overall considering it's pushing into oversells on every ISP. [SM] Oversell, or under-provisioning, IMHO is a viable technique to reduce costs, but it is not an excuse for short-shifting one's customers; if an ISP advertised and sells X Mbps, he/she needs to be willing to actually deliver independent on how "active" a given shared segment is. By this I do NOT mean that the contracted speed needs to be available 100% at all times, but that there is a reasonably high chance of getting close to the contracted rates. If that means either increasing prices to match cost targets or reduce maximally advertised contracted rates, or going to completely different kind of contracts (say, 1/Nth of a Gigabit link with equitable sharing among all N users on the link). Under-provisioning is fine as an optimization method to increase profitability, but IMHO no excuse on not delivering on one's contract. > I could talk endlessly about how useless speed tests are to end user experience. [SM] My take on this is a satisfied customer is unlikely to make a big fuss. And delivering great responsiveness is a great way for an ISP to make end-customers care less about achievable throughput. Yes, some will, e.g. gamers that insist on loading multi-gigabit updates just before playing instead of over-night (a strategy I have some sympathy for, shutting down power consumers fully over night instead of wasting watts on "stand-by" of some sort is a more reliable way to save power/cost). Regards Sebastian > > > On Mon, Jan 9, 2023 at 12:20 PM rjmcmahon via LibreQoS > <libreqos@lists.bufferbloat.net> wrote: >> >> User based, long duration tests seem fundamentally flawed. QoE for users >> is driven by user expectations. And if a user won't wait on a long test >> they for sure aren't going to wait minutes for a web page download. If >> it's a long duration use case, e.g. a file download, then latency isn't >> typically driving QoE. >> >> Not: Even for internal tests, we try to keep our automated tests down to >> 2 seconds. There are reasons to test for minutes (things like phy cals >> in our chips) but it's more of the exception than the rule. >> >> Bob >>>> 0) None of the tests last long enough. >>> >>> The user-initiated ones tend to be shorter - likely because the >>> average user does not want to wait several minutes for a test to >>> complete. But IMO this is where a test platform like SamKnows, Ookla's >>> embedded client, NetMicroscope, and others can come in - since they >>> run in the background on some randomized schedule w/o user >>> intervention. Thus, the user's time-sensitivity is no longer a factor >>> and a longer duration test can be performed. >>> >>>> 1) Not testing up + down + ping at the same time >>> >>> You should consider publishing a LUL BCP I-D in the IRTF/IETF - like in >>> IPPM... >>> >>> JL >>> >>> _______________________________________________ >>> Rpm mailing list >>> Rpm@lists.bufferbloat.net >>> https://lists.bufferbloat.net/listinfo/rpm >> _______________________________________________ >> LibreQoS mailing list >> LibreQoS@lists.bufferbloat.net >> https://lists.bufferbloat.net/listinfo/libreqos > _______________________________________________ > Rpm mailing list > Rpm@lists.bufferbloat.net > https://lists.bufferbloat.net/listinfo/rpm ^ permalink raw reply [flat|nested] 14+ messages in thread
* Re: [Starlink] [Rpm] [LibreQoS] [EXTERNAL] Re: Researchers Seeking Probe Volunteers in USA 2023-03-13 10:02 ` [Starlink] [Rpm] [LibreQoS] " Sebastian Moeller @ 2023-03-13 15:08 ` Jeremy Austin 2023-03-13 15:50 ` Sebastian Moeller 0 siblings, 1 reply; 14+ messages in thread From: Jeremy Austin @ 2023-03-13 15:08 UTC (permalink / raw) To: Sebastian Moeller Cc: dan, Rpm, libreqos, Dave Taht via Starlink, rjmcmahon, bloat [-- Attachment #1: Type: text/plain, Size: 1275 bytes --] On Mon, Mar 13, 2023 at 3:02 AM Sebastian Moeller via Starlink < starlink@lists.bufferbloat.net> wrote: > Hi Dan, > > > > On Jan 9, 2023, at 20:56, dan via Rpm <rpm@lists.bufferbloat.net> wrote: > > > > You don't need to generate the traffic on a link to measure how > > much traffic a link can handle. > > [SM] OK, I will bite, how do you measure achievable throughput > without actually generating it? Packet-pair techniques are notoriously > imprecise and have funny failure modes. > I am also looking forward to the full answer to this question. While one can infer when a link is saturated by mapping network topology onto latency sampling, it can have on the order of 30% error, given that there are multiple causes of increased latency beyond proximal congestion. A question I commonly ask network engineers or academics is "How can I accurately distinguish a constraint in supply from a reduction in demand?" -- -- Jeremy Austin Sr. Product Manager Preseem | Aterlo Networks preseem.com Book a Call: https://app.hubspot.com/meetings/jeremy548 Phone: 1-833-733-7336 x718 Email: jeremy@preseem.com Stay Connected with Newsletters & More: *https://preseem.com/stay-connected/* <https://preseem.com/stay-connected/> [-- Attachment #2: Type: text/html, Size: 2685 bytes --] ^ permalink raw reply [flat|nested] 14+ messages in thread
* Re: [Starlink] [Rpm] [LibreQoS] [EXTERNAL] Re: Researchers Seeking Probe Volunteers in USA 2023-03-13 15:08 ` Jeremy Austin @ 2023-03-13 15:50 ` Sebastian Moeller 2023-03-13 16:12 ` dan 0 siblings, 1 reply; 14+ messages in thread From: Sebastian Moeller @ 2023-03-13 15:50 UTC (permalink / raw) To: Jeremy Austin Cc: dan, Rpm, libreqos, Dave Taht via Starlink, rjmcmahon, bloat Hi Jeremy, > On Mar 13, 2023, at 16:08, Jeremy Austin <jeremy@aterlo.com> wrote: > > > > On Mon, Mar 13, 2023 at 3:02 AM Sebastian Moeller via Starlink <starlink@lists.bufferbloat.net> wrote: > Hi Dan, > > > > On Jan 9, 2023, at 20:56, dan via Rpm <rpm@lists.bufferbloat.net> wrote: > > > > You don't need to generate the traffic on a link to measure how > > much traffic a link can handle. > > [SM] OK, I will bite, how do you measure achievable throughput without actually generating it? Packet-pair techniques are notoriously imprecise and have funny failure modes. > > I am also looking forward to the full answer to this question. While one can infer when a link is saturated by mapping network topology onto latency sampling, it can have on the order of 30% error, given that there are multiple causes of increased latency beyond proximal congestion. So in the "autorates" a family of automatic tracking/setting methods for a cake shaper that (in friendly competition to each other) we use active measurements of RTT/OWD increases and there we try to vary our set of reflectors and then take a vote over a set of reflectors to decide "is it cake^W congestion", that helps to weed out a few alternative reasons for congestion detection (like distal congestion to individual reflectors). But that dies not answer the tricky question how to estimate capacity without actually creating a sufficient load (and doubly so on variable rate links). > A question I commonly ask network engineers or academics is "How can I accurately distinguish a constraint in suppl from a reduction in demand?" Good question. The autorates can not, but then they do not need to as they basically work by upping the shaper limit in correlation with the offered load until it detects sufficiently increased delay and reduces the shaper rates. A reduction n demand will lead to a reduction in load and bufferbloat... so the shaper is adapted based on the demand, aka "give the user as much thoughput as can be done within the users configured delay threshold, but not more"... If we had a reliable method to "measure how much traffic a link can handle." without having to track load and delay that would save us a ton of work ;) Regards Sebastian > > -- > -- > Jeremy Austin > Sr. Product Manager > Preseem | Aterlo Networks > preseem.com > > Book a Call: https://app.hubspot.com/meetings/jeremy548 > Phone: 1-833-733-7336 x718 > Email: jeremy@preseem.com > > Stay Connected with Newsletters & More: https://preseem.com/stay-connected/ ^ permalink raw reply [flat|nested] 14+ messages in thread
* Re: [Starlink] [Rpm] [LibreQoS] [EXTERNAL] Re: Researchers Seeking Probe Volunteers in USA 2023-03-13 15:50 ` Sebastian Moeller @ 2023-03-13 16:12 ` dan 2023-03-13 16:36 ` Sebastian Moeller 0 siblings, 1 reply; 14+ messages in thread From: dan @ 2023-03-13 16:12 UTC (permalink / raw) To: Sebastian Moeller Cc: Jeremy Austin, Rpm, libreqos, Dave Taht via Starlink, rjmcmahon, bloat " [SM] For a home link that means you need to measure on the router, as end-hosts will only ever see the fraction of traffic they sink/source themselves..." & [SM] OK, I will bite, how do you measure achievable throughput without actually generating it? Packet-pair techniques are notoriously imprecise and have funny failure modes. High water mark on their router. Highwater mark on our CPE, on our shaper, etc. Modern services are very happy to burst traffic. Nearly every customer we have will hit the top of their service place each day, even if only briefly and even if their average usage is quite low. Customers on 600Mbps mmwave services have a usage charge that is flat lines and ~600Mbps blips. " [SM] No ISP I know of publishes which periods are low, mid, high congestion so end-users will need to make some assumptions here (e.g. by looking at per day load graphs of big traffic exchanges like DE-CIX here https://www.de-cix.net/en/locations/frankfurt/statistics )" You read this wrong. Consumer routers run their daily speeds tests in the middle of the night. Eero at 3am for example. Netgear 230-430am. THAT is a bad measurement of the experience the consumer will have. It's essentially useless data for the consumer unless they are scheduling their downloads at 3am. Only a speed test during use hours is useful and that's also basically destructive unless a shaper makes sure it isn't. re per segment latency tests " [SM] Well is it really useless? If I know the to be expected latency-under-load increase I can eye-ball e.h. how far away a server I can still interact with in a "snappy" way." Yes it's completely useless to the customer. only their service latency matters. My (ISP) latency from hop 2 to 3 on the network has zero value to them. only the aggregate. per segment latency testing is ONLY valuable to the service providers for us to troubleshoot, repair, and upgrade. Even if a consumer does a traceroute and get's that 'one way' testing, it's irrelevant as they can't do anything about latency at hop 8 etc, and often they actually don't know which hops are which because they'll hidden in a tunnel/MPLS/etc. On Mon, Mar 13, 2023 at 9:50 AM Sebastian Moeller <moeller0@gmx.de> wrote: > > Hi Jeremy, > > > On Mar 13, 2023, at 16:08, Jeremy Austin <jeremy@aterlo.com> wrote: > > > > > > > > On Mon, Mar 13, 2023 at 3:02 AM Sebastian Moeller via Starlink <starlink@lists.bufferbloat.net> wrote: > > Hi Dan, > > > > > > > On Jan 9, 2023, at 20:56, dan via Rpm <rpm@lists.bufferbloat.net> wrote: > > > > > > You don't need to generate the traffic on a link to measure how > > > much traffic a link can handle. > > > > [SM] OK, I will bite, how do you measure achievable throughput without actually generating it? Packet-pair techniques are notoriously imprecise and have funny failure modes. > > > > I am also looking forward to the full answer to this question. While one can infer when a link is saturated by mapping network topology onto latency sampling, it can have on the order of 30% error, given that there are multiple causes of increased latency beyond proximal congestion. > > So in the "autorates" a family of automatic tracking/setting methods for a cake shaper that (in friendly competition to each other) we use active measurements of RTT/OWD increases and there we try to vary our set of reflectors and then take a vote over a set of reflectors to decide "is it cake^W congestion", that helps to weed out a few alternative reasons for congestion detection (like distal congestion to individual reflectors). But that dies not answer the tricky question how to estimate capacity without actually creating a sufficient load (and doubly so on variable rate links). > > > > A question I commonly ask network engineers or academics is "How can I accurately distinguish a constraint in suppl from a reduction in demand?" > > Good question. The autorates can not, but then they do not need to as they basically work by upping the shaper limit in correlation with the offered load until it detects sufficiently increased delay and reduces the shaper rates. A reduction n demand will lead to a reduction in load and bufferbloat... so the shaper is adapted based on the demand, aka "give the user as much thoughput as can be done within the users configured delay threshold, but not more"... > > If we had a reliable method to "measure how much traffic a link can handle." without having to track load and delay that would save us a ton of work ;) > > Regards > Sebastian > > > > > > -- > > -- > > Jeremy Austin > > Sr. Product Manager > > Preseem | Aterlo Networks > > preseem.com > > > > Book a Call: https://app.hubspot.com/meetings/jeremy548 > > Phone: 1-833-733-7336 x718 > > Email: jeremy@preseem.com > > > > Stay Connected with Newsletters & More: https://preseem.com/stay-connected/ > ^ permalink raw reply [flat|nested] 14+ messages in thread
* Re: [Starlink] [Rpm] [LibreQoS] [EXTERNAL] Re: Researchers Seeking Probe Volunteers in USA 2023-03-13 16:12 ` dan @ 2023-03-13 16:36 ` Sebastian Moeller 2023-03-13 17:26 ` dan 0 siblings, 1 reply; 14+ messages in thread From: Sebastian Moeller @ 2023-03-13 16:36 UTC (permalink / raw) To: dan Cc: Jeremy Austin, Rpm, libreqos, Dave Taht via Starlink, rjmcmahon, bloat Hi Dan, > On Mar 13, 2023, at 17:12, dan <dandenson@gmail.com> wrote: > > " [SM] For a home link that means you need to measure on the router, > as end-hosts will only ever see the fraction of traffic they > sink/source themselves..." > & > [SM] OK, I will bite, how do you measure achievable throughput > without actually generating it? Packet-pair techniques are notoriously > imprecise and have funny failure modes. > > High water mark on their router. [SM] Nope, my router is connected to my (bridged) modem via gigabit ethernet, with out a traffic shaper there is never going to be any noticeable water mark on the router side... sure the modem will built up a queue, but alas it does not expose the length of that DSL queue to me... A high water mark on my traffic shaped router informs me about my shaper setting (which I already know, after al I set it) but little about the capacity over the bottleneck link. And we are still talking about the easy egress direction, in the download direction Jeremy's question aplied is the achieved thoughput I measure limited by the link's capacity of are there simply not enoiugh packet available/sent to fill the pipe. > Highwater mark on our CPE, on our > shaper, etc. Modern services are very happy to burst traffic. [SM] Yes, this is also one of the readons, why too-little-buffering is problematic, I like the Nichols/Jacobsen analogy of buffers as shiock (burst) absorbers. > Nearly > every customer we have will hit the top of their service place each > day, even if only briefly and even if their average usage is quite > low. Customers on 600Mbps mmwave services have a usage charge that is > flat lines and ~600Mbps blips. [SM] Fully agree. most links are essentially idle most of the time, but that does not answer what instantaneous capacity is actually available, no? > > " [SM] No ISP I know of publishes which periods are low, mid, high > congestion so end-users will need to make some assumptions here (e.g. > by looking at per day load graphs of big traffic exchanges like DE-CIX > here https://www.de-cix.net/en/locations/frankfurt/statistics )" > > You read this wrong. Consumer routers run their daily speeds tests in > the middle of the night. [SM] So on my turris omnia I run a speedtest roughly every 2 hours exactly so I get coverage through low and high demand epochs. The only consumer router I know that does repeated tests is the IQrouter, which as far as I know schedules them regularly so it can adjust the traffic shaper to still deliver acceptale responsiveness even during peak hour. > Eero at 3am for example. Netgear 230-430am. [SM] That sounds"specisl" not a useless daa point per se, but of limited utility during normal usage times. > THAT is a bad measurement of the experience the consumer will have. [SM] Sure, but it still gives a usable reference for "what is the best my ISP actually delivers" if if the odds are stacked in his direction. > It's essentially useless data for the consumer unless they are > scheduling their downloads at 3am. Only a speed test during use hours > is useful and that's also basically destructive unless a shaper makes > sure it isn't. > > re per segment latency tests " [SM] Well is it really useless? If I > know the to be expected latency-under-load increase I can eye-ball > e.h. how far away a server I can still interact with in a "snappy" > way." > > Yes it's completely useless to the customer. only their service > latency matters. [SM] There is no single "service latency" it really depends on he specific network paths to the remote end and back. Unless you are talking about the latency over the access link only tere we have a single number but one of limited utility. > My (ISP) latency from hop 2 to 3 on the network has > zero value to them. only the aggregate. per segment latency testing > is ONLY valuable to the service providers for us to troubleshoot, > repair, and upgrade. Even if a consumer does a traceroute and get's > that 'one way' testing, it's irrelevant as they can't do anything > about latency at hop 8 etc, and often they actually don't know which > hops are which because they'll hidden in a tunnel/MPLS/etc. [SM] Yes, end-users can do little, but not nothing, e.g. one can often work-around shitty peering by using a VPN to route one's packets into an AS that is both well connected with one's ISP as well as with one's remote ASs. And I accept your point of one-way testing, getting a remote site at the ight location to do e.g. reverse tracerputes mtrs is tricky (sometimes RIPE ATLAS can help) to impossible (like my ISP that does not offer even simple lookingglas servers at all)). > > > > On Mon, Mar 13, 2023 at 9:50 AM Sebastian Moeller <moeller0@gmx.de> wrote: >> >> Hi Jeremy, >> >>> On Mar 13, 2023, at 16:08, Jeremy Austin <jeremy@aterlo.com> wrote: >>> >>> >>> >>> On Mon, Mar 13, 2023 at 3:02 AM Sebastian Moeller via Starlink <starlink@lists.bufferbloat.net> wrote: >>> Hi Dan, >>> >>> >>>> On Jan 9, 2023, at 20:56, dan via Rpm <rpm@lists.bufferbloat.net> wrote: >>>> >>>> You don't need to generate the traffic on a link to measure how >>>> much traffic a link can handle. >>> >>> [SM] OK, I will bite, how do you measure achievable throughput without actually generating it? Packet-pair techniques are notoriously imprecise and have funny failure modes. >>> >>> I am also looking forward to the full answer to this question. While one can infer when a link is saturated by mapping network topology onto latency sampling, it can have on the order of 30% error, given that there are multiple causes of increased latency beyond proximal congestion. >> >> So in the "autorates" a family of automatic tracking/setting methods for a cake shaper that (in friendly competition to each other) we use active measurements of RTT/OWD increases and there we try to vary our set of reflectors and then take a vote over a set of reflectors to decide "is it cake^W congestion", that helps to weed out a few alternative reasons for congestion detection (like distal congestion to individual reflectors). But that dies not answer the tricky question how to estimate capacity without actually creating a sufficient load (and doubly so on variable rate links). >> >> >>> A question I commonly ask network engineers or academics is "How can I accurately distinguish a constraint in suppl from a reduction in demand?" >> >> Good question. The autorates can not, but then they do not need to as they basically work by upping the shaper limit in correlation with the offered load until it detects sufficiently increased delay and reduces the shaper rates. A reduction n demand will lead to a reduction in load and bufferbloat... so the shaper is adapted based on the demand, aka "give the user as much thoughput as can be done within the users configured delay threshold, but not more"... >> >> If we had a reliable method to "measure how much traffic a link can handle." without having to track load and delay that would save us a ton of work ;) >> >> Regards >> Sebastian >> >> >>> >>> -- >>> -- >>> Jeremy Austin >>> Sr. Product Manager >>> Preseem | Aterlo Networks >>> preseem.com >>> >>> Book a Call: https://app.hubspot.com/meetings/jeremy548 >>> Phone: 1-833-733-7336 x718 >>> Email: jeremy@preseem.com >>> >>> Stay Connected with Newsletters & More: https://preseem.com/stay-connected/ >> ^ permalink raw reply [flat|nested] 14+ messages in thread
* Re: [Starlink] [Rpm] [LibreQoS] [EXTERNAL] Re: Researchers Seeking Probe Volunteers in USA 2023-03-13 16:36 ` Sebastian Moeller @ 2023-03-13 17:26 ` dan 2023-03-13 18:14 ` Sebastian Moeller 0 siblings, 1 reply; 14+ messages in thread From: dan @ 2023-03-13 17:26 UTC (permalink / raw) To: Sebastian Moeller Cc: Jeremy Austin, Rpm, libreqos, Dave Taht via Starlink, rjmcmahon, bloat On Mon, Mar 13, 2023 at 10:36 AM Sebastian Moeller <moeller0@gmx.de> wrote: > > Hi Dan, > > > > On Mar 13, 2023, at 17:12, dan <dandenson@gmail.com> wrote: > >... > > > > High water mark on their router. > > [SM] Nope, my router is connected to my (bridged) modem via gigabit ethernet, with out a traffic shaper there is never going to be any noticeable water mark on the router side... sure the modem will built up a queue, but alas it does not expose the length of that DSL queue to me... A high water mark on my traffic shaped router informs me about my shaper setting (which I already know, after al I set it) but little about the capacity over the bottleneck link. And we are still talking about the easy egress direction, in the download direction Jeremy's question aplied is the achieved thoughput I measure limited by the link's capacity of are there simply not enoiugh packet available/sent to fill the pipe. > And yet it can still see the flow of data on it's ports. The queue is irelevant to the measurement of data across a port. turn off the shaper and run anything. run your speed test. don't look at the speed test results, just use it to generate some traffic. you'll find your peak and where you hit the buffers on the DSL modem by measuring on the interface and measuring latency. That speed test isn't giving you this data and more than Disney+, other than you get to pick when it runs. > > Highwater mark on our CPE, on our > > shaper, etc. Modern services are very happy to burst traffic. > > [SM] Yes, this is also one of the readons, why too-little-buffering is problematic, I like the Nichols/Jacobsen analogy of buffers as shiock (burst) absorbers. > > > Nearly > > every customer we have will hit the top of their service place each > > day, even if only briefly and even if their average usage is quite > > low. Customers on 600Mbps mmwave services have a usage charge that is > > flat lines and ~600Mbps blips. > > [SM] Fully agree. most links are essentially idle most of the time, but that does not answer what instantaneous capacity is actually available, no? yes, because most services burst. That Roku Ultra or Apple TV is going to running a 'speed test' every time it goes to fill it's buffer. Windows and Apple updates are asking for everything. Again, I'm measuring even the lowly grandma's house as consuming the entire connection for a few seconds before it sits idle for a minute. That instantaneous capacity is getting used up so long as there is a device/connection on the network capable of using it up. > > > > > " [SM] No ISP I know of publishes which periods are low, mid, high > > congestion so end-users will need to make some assumptions here (e.g. > > by looking at per day load graphs of big traffic exchanges like DE-CIX > > here https://www.de-cix.net/en/locations/frankfurt/statistics )" > > > > You read this wrong. Consumer routers run their daily speeds tests in > > the middle of the night. > > [SM] So on my turris omnia I run a speedtest roughly every 2 hours exactly so I get coverage through low and high demand epochs. The only consumer router I know that does repeated tests is the IQrouter, which as far as I know schedules them regularly so it can adjust the traffic shaper to still deliver acceptale responsiveness even during peak hour. Consider this. Customer under load, using their plan to the maximum, speed test fires up adding more constraint. Speed test is a stress test, not a capacity test. Speed test cannot return actual capacity because it's being used by other services AND the rest of the internet is in the way of accuracy as well, unless of course you prioritize the speed test and then you cause an effective outage or you're running a speed test on-net which isn't an 'internet' test, it's a network test. Guess what the only way to get an actual measure of the capacity is? my way. measure what's passing the interface and measure what happens to a reliable latency test during that time. > > > > Eero at 3am for example. Netgear 230-430am. > > [SM] That sounds"specisl" not a useless daa point per se, but of limited utility during normal usage times. In practical terms, useless. Like measuring how freeway congestion affects commutes at 3am. > > > THAT is a bad measurement of the experience the consumer will have. > > [SM] Sure, but it still gives a usable reference for "what is the best my ISP actually delivers" if if the odds are stacked in his direction. ehh...... what the ISP could deliver if all other considerations are removed. I mean, it'd be a synthetic test in any other scenario and the only reason it's not is because it's on real hardware. I don't have a single subscriber on network that can't get 2-3x their plan speed at 3am if I opened up their shaper. Very narrow use case here from a consumer point of view. Eero runs speed tests at 3am every single day on a few hundred subs on my network and they look AMAZING every time. no surprise. > > > It's essentially useless data for ... > > [SM] There is no single "service latency" it really depends on he specific network paths to the remote end and back. Unless you are talking about the latency over the access link only tere we have a single number but one of limited utility. The intermediate hops are still useless to the consumer. Only the latency to their door so to speak. again, hop 2 to hop 3 on my network gives them absolutely nothing. > > > > My (ISP) latency from hop 2 to 3 on the network has > ...> > hops are which because they'll hidden in a tunnel/MPLS/etc. > > [SM] Yes, end-users can do little, but not nothing, e.g. one can often work-around shitty peering by using a VPN to route one's packets into an AS that is both well connected with one's ISP as well as with one's remote ASs. And I accept your point of one-way testing, getting a remote site at the ight location to do e.g. reverse tracerputes mtrs is tricky (sometimes RIPE ATLAS can help) to impossible (like my ISP that does not offer even simple lookingglas servers at all)). This is a REALLY narrow use case. Also, irrelevant. Consumer can test to their target, to the datacenter, and datacenter to target and compare, and do that in reverse to get bi-directional latency. per hop latency is still of zero benefit to them because they can't use that in any practical way. Like 1 in maybe a few thousand consumers might be able to use this data to identify the slow hop and find a datacenter before that hop to route around it and they get about 75% of the way with a traditional trace router. and then of course they've added VPN overheads so are they really getting an improvement? I'm not saying that testing is bad in any way, I'm saying that 'speed tests' as they are generally understood in this industry are a bad method. Run 10 speed tests, get 10 results. Run a speed test while netflix buffers, get a bad result. Run a speed test from a weak wifi connection, get a bad result. A tool that is inherently flawed because it's methodology is flawed is of no use to find the truth. If you troubleshoot your ISP based on speed tests you will be chasing your tail. Meanwhile, that internet facing interface can see the true numbers the entire time. The consumer is pulling their full capacity on almost all links routinely even if briefly and can be nudged into pushing more a dozen ways (including a speed test). The only thing lacking is a latency measurement of some sort. Preseem and Libreqos's TCP measurements on the head end are awesome, but that's not available on the subscriber's side but if it were, there's the full testing suite. how much peak data, what happened to latency. If you could get data from the ISP's head end to diff you'd have internet vs isp latencies. 'speed test' is a stress test or a burn in test in effect. ^ permalink raw reply [flat|nested] 14+ messages in thread
* Re: [Starlink] [Rpm] [LibreQoS] [EXTERNAL] Re: Researchers Seeking Probe Volunteers in USA 2023-03-13 17:26 ` dan @ 2023-03-13 18:14 ` Sebastian Moeller 2023-03-13 18:42 ` rjmcmahon 0 siblings, 1 reply; 14+ messages in thread From: Sebastian Moeller @ 2023-03-13 18:14 UTC (permalink / raw) To: dan Cc: Jeremy Austin, Rpm, libreqos, Dave Taht via Starlink, rjmcmahon, bloat Hi Dan, > On Mar 13, 2023, at 18:26, dan <dandenson@gmail.com> wrote: > > On Mon, Mar 13, 2023 at 10:36 AM Sebastian Moeller <moeller0@gmx.de> wrote: >> >> Hi Dan, >> >> >>> On Mar 13, 2023, at 17:12, dan <dandenson@gmail.com> wrote: >>> ... >>> >>> High water mark on their router. >> >> [SM] Nope, my router is connected to my (bridged) modem via gigabit ethernet, with out a traffic shaper there is never going to be any noticeable water mark on the router side... sure the modem will built up a queue, but alas it does not expose the length of that DSL queue to me... A high water mark on my traffic shaped router informs me about my shaper setting (which I already know, after al I set it) but little about the capacity over the bottleneck link. And we are still talking about the easy egress direction, in the download direction Jeremy's question aplied is the achieved thoughput I measure limited by the link's capacity of are there simply not enoiugh packet available/sent to fill the pipe. >> > > And yet it can still see the flow of data on it's ports. The queue is > irelevant to the measurement of data across a port. I respectfully disagree, if say, my modem had a 4 GB queue I could theoretically burst ~4GB worth of data at line rate into that buffer without learning anything about the the modem-link capacity. > turn off the > shaper and run anything. run your speed test. don't look at the > speed test results, just use it to generate some traffic. you'll find > your peak and where you hit the buffers on the DSL modem by measuring > on the interface and measuring latency. Peak of what? Exactly? The peak sending rate of my router is well known, its 1 Gbps gross ethernet rate... > That speed test isn't giving > you this data and more than Disney+, other than you get to pick when > it runs. Hrm, no we sre back at actually saturating the link, > >>> Highwater mark on our CPE, on our >>> shaper, etc. Modern services are very happy to burst traffic. >> >> [SM] Yes, this is also one of the readons, why too-little-buffering is problematic, I like the Nichols/Jacobsen analogy of buffers as shiock (burst) absorbers. >> >>> Nearly >>> every customer we have will hit the top of their service place each >>> day, even if only briefly and even if their average usage is quite >>> low. Customers on 600Mbps mmwave services have a usage charge that is >>> flat lines and ~600Mbps blips. >> >> [SM] Fully agree. most links are essentially idle most of the time, but that does not answer what instantaneous capacity is actually available, no? > > yes, because most services burst. That Roku Ultra or Apple TV is > going to running a 'speed test' every time it goes to fill it's > buffer. [SM] not really, given enough capacity, typical streaming protocols will actually not hit the ceiling, at least the one's I look at every now and then tend to stay well below actual capacity of the link. > Windows and Apple updates are asking for everything. Again, > I'm measuring even the lowly grandma's house as consuming the entire > connection for a few seconds before it sits idle for a minute. That > instantaneous capacity is getting used up so long as there is a > device/connection on the network capable of using it up. [SM] But my problem is that on variable rate links I want to measure the instantaneous capacity such that I can do adaptive admission control and avpid over filling my modem's DSL buffers (I wish they would do something like BQL, but alas they don't). > >> >>> >>> " [SM] No ISP I know of publishes which periods are low, mid, high >>> congestion so end-users will need to make some assumptions here (e.g. >>> by looking at per day load graphs of big traffic exchanges like DE-CIX >>> here https://www.de-cix.net/en/locations/frankfurt/statistics )" >>> >>> You read this wrong. Consumer routers run their daily speeds tests in >>> the middle of the night. >> >> [SM] So on my turris omnia I run a speedtest roughly every 2 hours exactly so I get coverage through low and high demand epochs. The only consumer router I know that does repeated tests is the IQrouter, which as far as I know schedules them regularly so it can adjust the traffic shaper to still deliver acceptale responsiveness even during peak hour. > > Consider this. Customer under load, using their plan to the maximum, > speed test fires up adding more constraint. Speed test is a stress > test, not a capacity test. [SM] With competent AQM (like cake on ingress and egress configured for per-internal-IP isolation) I do not even notice whether a speedtes runs or not, and from the reported capacity I can estimate the concurrent load from other endhosts in my network. > Speed test cannot return actual capacity > because it's being used by other services AND the rest of the internet > is in the way of accuracy as well, unless of course you prioritize the > speed test and then you cause an effective outage or you're running a > speed test on-net which isn't an 'internet' test, it's a network test. [SM] Conventional capcaity tests give a decent enough estimate of current capacity to be useful, I could not care less that they are potential not perfect, sorry. The question still is how to estimate capacity without loading the link... > Guess what the only way to get an actual measure of the capacity is? > my way. measure what's passing the interface and measure what happens > to a reliable latency test during that time. [SM] This is, respectfully, what we do in cake-autorate, but that requires an actual load and only accidentally detects the capacity, if a high enough load is sustained long enough to evoke a latency increase. But I knew that already, what you initially wrote sounded to me like you had a method to detect instantaneous capacity without needing to generate load. (BTW, in cake-autorate we do not generate an artificial load (only artificial/active latency probes) but use the organic user generated traffic as load generator*). *) If all endhosts are idle we do not care much about the capacity, only if there is traffic, however the quicker we can estimate the capacity the tigher our controller can operate. > >> >> >>> Eero at 3am for example. Netgear 230-430am. >> >> [SM] That sounds"specisl" not a useless daa point per se, but of limited utility during normal usage times. > > In practical terms, useless. Like measuring how freeway congestion > affects commutes at 3am. [SM] That is not "useless" sorry, it gives my a lower bound for my compute (or allows to estimate a lower duration of a transfer of a given size). But I agree it does little to inform me what to expect during peak hour. > >> >>> THAT is a bad measurement of the experience the consumer will have. >> >> [SM] Sure, but it still gives a usable reference for "what is the best my ISP actually delivers" if if the odds are stacked in his direction. > > ehh...... what the ISP could deliver if all other considerations are > removed. [SM] No, this is still a test of the real existing network... > I mean, it'd be a synthetic test in any other scenario and > the only reason it's not is because it's on real hardware. I don't > have a single subscriber on network that can't get 2-3x their plan > speed at 3am if I opened up their shaper. Very narrow use case here > from a consumer point of view. Eero runs speed tests at 3am every > single day on a few hundred subs on my network and they look AMAZING > every time. no surprise. [SM] While I defend some utility for such a test on pronciple, I agree that if eero only runs a single test 3 AM is not the best time to do that, except for night owls. > >> >>> It's essentially useless data for ... >> >> [SM] There is no single "service latency" it really depends on he specific network paths to the remote end and back. Unless you are talking about the latency over the access link only tere we have a single number but one of limited utility. > > The intermediate hops are still useless to the consumer. Only the > latency to their door so to speak. again, hop 2 to hop 3 on my > network gives them absolutely nothing. [SM] I agree if these are mandatory hops I need to traverse every time, but if these are host I can potentially avoid then this changes, even though I am now trying to gsame my ISP to some degree which in the long run is a loosing proposition. > >> >> >>> My (ISP) latency from hop 2 to 3 on the network has >> ...> > hops are which because they'll hidden in a tunnel/MPLS/etc. >> >> [SM] Yes, end-users can do little, but not nothing, e.g. one can often work-around shitty peering by using a VPN to route one's packets into an AS that is both well connected with one's ISP as well as with one's remote ASs. And I accept your point of one-way testing, getting a remote site at the ight location to do e.g. reverse tracerputes mtrs is tricky (sometimes RIPE ATLAS can help) to impossible (like my ISP that does not offer even simple lookingglas servers at all)). > > This is a REALLY narrow use case. Also, irrelevant. [SM] You would think, would you ;). However over here the T1 incumbent telco plays "peering games" and purposefully runs its transit links too hot so in primetime traffic coming from content providers via transit suffers. The telco's idea here is to incentivize these content providers to buy "transit" from that telco that happens to cost integer multiples of transit and hence will only ever be used to access this telco's customers if a content provider actually buys in. As an end-user of that telco, I have three options: a) switch content providers b) switch ISP c) route around my ISPs unfriendly peering (Personally even though not directly affected by this I opted for b) and found a better connected yet still cheaper ISP). I am not alone in this, actually a lot of gamers do something similar using gaming oriented VPN services. But then gamers are a bit like audiophiles to me, some of the things they do look like cargo-cult to me, but I digress/ > Consumer can test > to their target, to the datacenter, and datacenter to target and > compare, and do that in reverse to get bi-directional latency. [SM] I have been tought thst does not actually work as the true return path is essentially invisible without a probe for a reverse traceroute at the site of the remote server, no? > per > hop latency is still of zero benefit to them because they can't use > that in any practical way. [SM] And again I disagree, I can within reason diagnose congested path elements from an mtr... say if on a path across three AS that at best takes 10 milliseconds, I see at primetime that from the link between AS1 and AS2 all hops including the endpoint show an RTT of say 100ms, I can form the hypothsis that somewhere between AS1 and AS2 there is a undue queue build-up. Pratically this can mean I need to rpute my own traffic differentky, either by VPN, or by switching the used application content provider hoping to avoid the apparently congested link. What I can not do is fix the problem, that is true ;) > Like 1 in maybe a few thousand consumers > might be able to use this data to identify the slow hop and find a > datacenter before that hop to route around it and they get about 75% > of the way with a traditional trace router. and then of course they've > added VPN overheads so are they really getting an improvement? [SM] In the german telco case peak rate to some datacenters/VPS (single-homed at cogent) dropped into the low Kbps range, while a VPN route-around returned that into the high double digit Mbps, so yes the improvement can be tangible. Again, my soluton to that possibility was to "vote with my feet" and change ISPs (a pity, because outside of that unpleasant peering/transit behaviour that telco is a pretty competent ISP; case in point the transit links run too hot, but are are competently managed to actually stay at the selected "temperature" and do not progress into to total overload territory.) > I'm not saying that testing is bad in any way, I'm saying that 'speed > tests' as they are generally understood in this industry are a bad > method. [SM] +1, with that I can agree. But I see some mild improvements, with e.g. Ookla reporting latency numbers from during the load phases. Sure the chosen measure inter-quartil mean, is sub-optimal, but infinitely better than hat they had before, no latecny under load numbers. > Run 10 speed tests, get 10 results. Run a speed test while > netflix buffers, get a bad result. Run a speed test from a weak wifi > connection, get a bad result. A tool that is inherently flawed > because it's methodology is flawed is of no use to find the truth. [SM] For most end users speedtests are the one convenient way of generating saturating loads. BUt saturating loads by them selves are not that useful. > > If you troubleshoot your ISP based on speed tests you will be chasing > your tail. My most recent attempt was with mtr traces to document packetloss only when "packed" into one specific IP range, and that packetloss happens even without load at night, so no speedtest required (I did run a few speed.cloudflare.com tests, but mainly because they contain a very simple and short packet loss test, that finishes a tad earlier than my go to 'mtr -ezbw -c 1000 IP_HERE' packet loss test ;) ) > Meanwhile, that internet facing interface can see the true > numbers the entire time. [SM] Only averaged over time... > The consumer is pulling their full capacity > on almost all links routinely even if briefly and can be nudged into > pushing more a dozen ways (including a speed test). The only thing > lacking is a latency measurement of some sort. Preseem and Libreqos's > TCP measurements on the head end are awesome, but that's not available > on the subscriber's side but if it were, there's the full testing > suite. how much peak data, what happened to latency. If you could > get data from the ISP's head end to diff you'd have internet vs isp > latencies. 'speed test' is a stress test or a burn in test in > effect. [SM] I still agree "speedtests" are misnames capacity tests and do have their value (e.g. over here the main determinant of internet access price is the headline capacity number) we even have an "official" capacity test blessed by the national regulatory agency that can be used to defend consumer rights against those ISP that over-promise but under-deliver (few people d though, as it happens if your ISP generally delivers acceptable throughput and generally is not a d*ck, people are fine with not caring all too much). On the last point I believe the more responsiveness an ISP link maintains under load the fewer people will get unhappy about their internet experience and without unhappyness most users I presime have better things to do than fight with their ISP. ;) Regards Sebastian ^ permalink raw reply [flat|nested] 14+ messages in thread
* Re: [Starlink] [Rpm] [LibreQoS] [EXTERNAL] Re: Researchers Seeking Probe Volunteers in USA 2023-03-13 18:14 ` Sebastian Moeller @ 2023-03-13 18:42 ` rjmcmahon 2023-03-13 18:51 ` Sebastian Moeller 0 siblings, 1 reply; 14+ messages in thread From: rjmcmahon @ 2023-03-13 18:42 UTC (permalink / raw) To: Sebastian Moeller Cc: dan, Jeremy Austin, Rpm, libreqos, Dave Taht via Starlink, bloat > [SM] not really, given enough capacity, typical streaming protocols > will actually not hit the ceiling, at least the one's I look at every > now and then tend to stay well below actual capacity of the link. > I think DASH type protocol will hit link peaks. An example with iperf 2's burst option a controlled WiFi test rig, server side first. [root@ctrl1fc35 ~]# iperf -s -i 1 -e --histograms ------------------------------------------------------------ Server listening on TCP port 5001 with pid 23764 Read buffer size: 128 KByte (Dist bin width=16.0 KByte) Enabled receive histograms bin-width=0.100 ms, bins=10000 (clients should use --trip-times) TCP window size: 128 KByte (default) ------------------------------------------------------------ [ 1] local 192.168.1.15%enp2s0 port 5001 connected with 192.168.1.234 port 34894 (burst-period=1.00s) (trip-times) (sock=4) (peer 2.1.9-rc2) (icwnd/mss/irtt=14/1448/5170) on 2023-03-13 11:37:24.500 (PDT) [ ID] Burst (start-end) Transfer Bandwidth XferTime (DC%) Reads=Dist NetPwr [ 1] 0.00-0.13 sec 10.0 MBytes 633 Mbits/sec 132.541 ms (13%) 209=29:31:31:88:11:2:1:16 597 [ 1] 1.00-1.11 sec 10.0 MBytes 755 Mbits/sec 111.109 ms (11%) 205=34:30:22:83:11:2:6:17 849 [ 1] 2.00-2.12 sec 10.0 MBytes 716 Mbits/sec 117.196 ms (12%) 208=33:39:20:81:13:1:5:16 763 [ 1] 3.00-3.11 sec 10.0 MBytes 745 Mbits/sec 112.564 ms (11%) 203=27:36:30:76:6:3:6:19 828 [ 1] 4.00-4.11 sec 10.0 MBytes 787 Mbits/sec 106.621 ms (11%) 193=29:26:19:80:10:4:6:19 922 [ 1] 5.00-5.11 sec 10.0 MBytes 769 Mbits/sec 109.148 ms (11%) 208=36:25:32:86:6:1:5:17 880 [ 1] 6.00-6.11 sec 10.0 MBytes 760 Mbits/sec 110.403 ms (11%) 206=42:30:22:73:8:3:5:23 860 [ 1] 7.00-7.11 sec 10.0 MBytes 775 Mbits/sec 108.261 ms (11%) 171=20:21:21:58:12:1:11:27 895 [ 1] 8.00-8.11 sec 10.0 MBytes 746 Mbits/sec 112.405 ms (11%) 203=36:31:28:70:9:3:2:24 830 [ 1] 9.00-9.11 sec 10.0 MBytes 748 Mbits/sec 112.133 ms (11%) 228=41:56:27:73:7:2:3:19 834 [ 1] 0.00-10.00 sec 100 MBytes 83.9 Mbits/sec 113.238/106.621/132.541/7.367 ms 2034=327:325:252:768:93:22:50:197 [ 1] 0.00-10.00 sec F8(f)-PDF: bin(w=100us):cnt(10)=1067:1,1083:1,1092:1,1105:1,1112:1,1122:1,1125:1,1126:1,1172:1,1326:1 (5.00/95.00/99.7%=1067/1326/1326,Outliers=0,obl/obu=0/0) (132.541 ms/1678732644.500333) [root@fedora ~]# iperf -c 192.168.1.15 -i 1 -t 10 --burst-size 10M --burst-period 1 --trip-times ------------------------------------------------------------ Client connecting to 192.168.1.15, TCP port 5001 with pid 132332 (1 flows) Write buffer size: 131072 Byte Bursting: 10.0 MByte every 1.00 second(s) TOS set to 0x0 (Nagle on) TCP window size: 16.0 KByte (default) Event based writes (pending queue watermark at 16384 bytes) ------------------------------------------------------------ [ 1] local 192.168.1.234%eth1 port 34894 connected with 192.168.1.15 port 5001 (prefetch=16384) (trip-times) (sock=3) (icwnd/mss/irtt=14/1448/5489) (ct=5.58 ms) on 2023-03-13 11:37:24.494 (PDT) [ ID] Interval Transfer Bandwidth Write/Err Rtry Cwnd/RTT(var) NetPwr [ 1] 0.00-1.00 sec 10.0 MBytes 83.9 Mbits/sec 80/0 0 5517K/18027(1151) us 582 [ 1] 1.00-2.00 sec 10.0 MBytes 83.9 Mbits/sec 80/0 0 5584K/13003(2383) us 806 [ 1] 2.00-3.00 sec 10.0 MBytes 83.9 Mbits/sec 80/0 0 5613K/16462(962) us 637 [ 1] 3.00-4.00 sec 10.0 MBytes 83.9 Mbits/sec 80/0 0 5635K/19523(671) us 537 [ 1] 4.00-5.00 sec 10.0 MBytes 83.9 Mbits/sec 80/0 0 5594K/10013(1685) us 1047 [ 1] 5.00-6.00 sec 10.0 MBytes 83.9 Mbits/sec 80/0 0 5479K/14008(654) us 749 [ 1] 6.00-7.00 sec 10.0 MBytes 83.9 Mbits/sec 80/0 0 5613K/17752(283) us 591 [ 1] 7.00-8.00 sec 10.0 MBytes 83.9 Mbits/sec 80/0 0 5599K/17743(436) us 591 [ 1] 8.00-9.00 sec 10.0 MBytes 83.9 Mbits/sec 80/0 0 5577K/11214(2538) us 935 [ 1] 9.00-10.00 sec 10.0 MBytes 83.9 Mbits/sec 80/0 0 4178K/7251(993) us 1446 [ 1] 0.00-10.01 sec 100 MBytes 83.8 Mbits/sec 800/0 0 4178K/7725(1694) us 1356 [root@fedora ~]# Note: Client side output is being updated to support outputs based upon the bursts. This allows one to see that a DASH type protocol can drive the bw bottleneck queue. Bob ^ permalink raw reply [flat|nested] 14+ messages in thread
* Re: [Starlink] [Rpm] [LibreQoS] [EXTERNAL] Re: Researchers Seeking Probe Volunteers in USA 2023-03-13 18:42 ` rjmcmahon @ 2023-03-13 18:51 ` Sebastian Moeller 2023-03-13 19:32 ` rjmcmahon 0 siblings, 1 reply; 14+ messages in thread From: Sebastian Moeller @ 2023-03-13 18:51 UTC (permalink / raw) To: rjmcmahon Cc: dan, Jeremy Austin, Rpm, libreqos, Dave Taht via Starlink, bloat Hi Bob, > On Mar 13, 2023, at 19:42, rjmcmahon <rjmcmahon@rjmcmahon.com> wrote: > >> [SM] not really, given enough capacity, typical streaming protocols >> will actually not hit the ceiling, at least the one's I look at every >> now and then tend to stay well below actual capacity of the link. > I think DASH type protocol will hit link peaks. An example with iperf 2's burst option a controlled WiFi test rig, server side first. [SM] I think that depends, each segment has only a finite length and if this can delivered before slow start ends that burst might never hit the capacity? Regards Sebastian > > > [root@ctrl1fc35 ~]# iperf -s -i 1 -e --histograms > ------------------------------------------------------------ > Server listening on TCP port 5001 with pid 23764 > Read buffer size: 128 KByte (Dist bin width=16.0 KByte) > Enabled receive histograms bin-width=0.100 ms, bins=10000 (clients should use --trip-times) > TCP window size: 128 KByte (default) > ------------------------------------------------------------ > [ 1] local 192.168.1.15%enp2s0 port 5001 connected with 192.168.1.234 port 34894 (burst-period=1.00s) (trip-times) (sock=4) (peer 2.1.9-rc2) (icwnd/mss/irtt=14/1448/5170) on 2023-03-13 11:37:24.500 (PDT) > [ ID] Burst (start-end) Transfer Bandwidth XferTime (DC%) Reads=Dist NetPwr > [ 1] 0.00-0.13 sec 10.0 MBytes 633 Mbits/sec 132.541 ms (13%) 209=29:31:31:88:11:2:1:16 597 > [ 1] 1.00-1.11 sec 10.0 MBytes 755 Mbits/sec 111.109 ms (11%) 205=34:30:22:83:11:2:6:17 849 > [ 1] 2.00-2.12 sec 10.0 MBytes 716 Mbits/sec 117.196 ms (12%) 208=33:39:20:81:13:1:5:16 763 > [ 1] 3.00-3.11 sec 10.0 MBytes 745 Mbits/sec 112.564 ms (11%) 203=27:36:30:76:6:3:6:19 828 > [ 1] 4.00-4.11 sec 10.0 MBytes 787 Mbits/sec 106.621 ms (11%) 193=29:26:19:80:10:4:6:19 922 > [ 1] 5.00-5.11 sec 10.0 MBytes 769 Mbits/sec 109.148 ms (11%) 208=36:25:32:86:6:1:5:17 880 > [ 1] 6.00-6.11 sec 10.0 MBytes 760 Mbits/sec 110.403 ms (11%) 206=42:30:22:73:8:3:5:23 860 > [ 1] 7.00-7.11 sec 10.0 MBytes 775 Mbits/sec 108.261 ms (11%) 171=20:21:21:58:12:1:11:27 895 > [ 1] 8.00-8.11 sec 10.0 MBytes 746 Mbits/sec 112.405 ms (11%) 203=36:31:28:70:9:3:2:24 830 > [ 1] 9.00-9.11 sec 10.0 MBytes 748 Mbits/sec 112.133 ms (11%) 228=41:56:27:73:7:2:3:19 834 > [ 1] 0.00-10.00 sec 100 MBytes 83.9 Mbits/sec 113.238/106.621/132.541/7.367 ms 2034=327:325:252:768:93:22:50:197 > [ 1] 0.00-10.00 sec F8(f)-PDF: bin(w=100us):cnt(10)=1067:1,1083:1,1092:1,1105:1,1112:1,1122:1,1125:1,1126:1,1172:1,1326:1 (5.00/95.00/99.7%=1067/1326/1326,Outliers=0,obl/obu=0/0) (132.541 ms/1678732644.500333) > > > [root@fedora ~]# iperf -c 192.168.1.15 -i 1 -t 10 --burst-size 10M --burst-period 1 --trip-times > ------------------------------------------------------------ > Client connecting to 192.168.1.15, TCP port 5001 with pid 132332 (1 flows) > Write buffer size: 131072 Byte > Bursting: 10.0 MByte every 1.00 second(s) > TOS set to 0x0 (Nagle on) > TCP window size: 16.0 KByte (default) > Event based writes (pending queue watermark at 16384 bytes) > ------------------------------------------------------------ > [ 1] local 192.168.1.234%eth1 port 34894 connected with 192.168.1.15 port 5001 (prefetch=16384) (trip-times) (sock=3) (icwnd/mss/irtt=14/1448/5489) (ct=5.58 ms) on 2023-03-13 11:37:24.494 (PDT) > [ ID] Interval Transfer Bandwidth Write/Err Rtry Cwnd/RTT(var) NetPwr > [ 1] 0.00-1.00 sec 10.0 MBytes 83.9 Mbits/sec 80/0 0 5517K/18027(1151) us 582 > [ 1] 1.00-2.00 sec 10.0 MBytes 83.9 Mbits/sec 80/0 0 5584K/13003(2383) us 806 > [ 1] 2.00-3.00 sec 10.0 MBytes 83.9 Mbits/sec 80/0 0 5613K/16462(962) us 637 > [ 1] 3.00-4.00 sec 10.0 MBytes 83.9 Mbits/sec 80/0 0 5635K/19523(671) us 537 > [ 1] 4.00-5.00 sec 10.0 MBytes 83.9 Mbits/sec 80/0 0 5594K/10013(1685) us 1047 > [ 1] 5.00-6.00 sec 10.0 MBytes 83.9 Mbits/sec 80/0 0 5479K/14008(654) us 749 > [ 1] 6.00-7.00 sec 10.0 MBytes 83.9 Mbits/sec 80/0 0 5613K/17752(283) us 591 > [ 1] 7.00-8.00 sec 10.0 MBytes 83.9 Mbits/sec 80/0 0 5599K/17743(436) us 591 > [ 1] 8.00-9.00 sec 10.0 MBytes 83.9 Mbits/sec 80/0 0 5577K/11214(2538) us 935 > [ 1] 9.00-10.00 sec 10.0 MBytes 83.9 Mbits/sec 80/0 0 4178K/7251(993) us 1446 > [ 1] 0.00-10.01 sec 100 MBytes 83.8 Mbits/sec 800/0 0 4178K/7725(1694) us 1356 > [root@fedora ~]# > > Note: Client side output is being updated to support outputs based upon the bursts. This allows one to see that a DASH type protocol can drive the bw bottleneck queue. > > Bob > ^ permalink raw reply [flat|nested] 14+ messages in thread
* Re: [Starlink] [Rpm] [LibreQoS] [EXTERNAL] Re: Researchers Seeking Probe Volunteers in USA 2023-03-13 18:51 ` Sebastian Moeller @ 2023-03-13 19:32 ` rjmcmahon 2023-03-13 20:00 ` Sebastian Moeller 0 siblings, 1 reply; 14+ messages in thread From: rjmcmahon @ 2023-03-13 19:32 UTC (permalink / raw) To: Sebastian Moeller Cc: dan, Jeremy Austin, Rpm, libreqos, Dave Taht via Starlink, bloat On 2023-03-13 11:51, Sebastian Moeller wrote: > Hi Bob, > > >> On Mar 13, 2023, at 19:42, rjmcmahon <rjmcmahon@rjmcmahon.com> wrote: >> >>> [SM] not really, given enough capacity, typical streaming protocols >>> will actually not hit the ceiling, at least the one's I look at every >>> now and then tend to stay well below actual capacity of the link. >> I think DASH type protocol will hit link peaks. An example with iperf >> 2's burst option a controlled WiFi test rig, server side first. > > [SM] I think that depends, each segment has only a finite length and > if this can delivered before slow start ends that burst might never > hit the capacity? > > Regards I believe most CDNs are setting the initial CWND so TCP can bypass slow start. Slow start seems an engineering flaw from the perspective of low latency. It's done for "fairness" whatever that means. Bob ^ permalink raw reply [flat|nested] 14+ messages in thread
* Re: [Starlink] [Rpm] [LibreQoS] [EXTERNAL] Re: Researchers Seeking Probe Volunteers in USA 2023-03-13 19:32 ` rjmcmahon @ 2023-03-13 20:00 ` Sebastian Moeller 2023-03-13 20:28 ` rjmcmahon 0 siblings, 1 reply; 14+ messages in thread From: Sebastian Moeller @ 2023-03-13 20:00 UTC (permalink / raw) To: rjmcmahon Cc: dan, Jeremy Austin, Rpm, libreqos, Dave Taht via Starlink, bloat Hi Bob, > On Mar 13, 2023, at 20:32, rjmcmahon <rjmcmahon@rjmcmahon.com> wrote: > > On 2023-03-13 11:51, Sebastian Moeller wrote: >> Hi Bob, >>> On Mar 13, 2023, at 19:42, rjmcmahon <rjmcmahon@rjmcmahon.com> wrote: >>>> [SM] not really, given enough capacity, typical streaming protocols >>>> will actually not hit the ceiling, at least the one's I look at every >>>> now and then tend to stay well below actual capacity of the link. >>> I think DASH type protocol will hit link peaks. An example with iperf 2's burst option a controlled WiFi test rig, server side first. >> [SM] I think that depends, each segment has only a finite length and >> if this can delivered before slow start ends that burst might never >> hit the capacity? >> Regards > > I believe most CDNs are setting the initial CWND so TCP can bypass slow start. [SM] My take is not necessarily to bypass slow start, but to kick it off with a higher starting point... which is the conservative way to expedite slow-start. Real man actually increase the multiplication factor instead, but there are few real men around (luckily)... s I see both the desire to finish many smaller transfers within the initial window (so the first RTT after the handshake IIUC). > Slow start seems an engineering flaw from the perspective of low latency. [SM] Yes, exponential search, doubling every RTT is pretty aggressive. > It's done for "fairness" whatever that means. [SM] It is doe because: a) TCP needs some capacity estimate b) preferably quickly c) in a way gentler than what was used before the congestion collapse. we are calling it slow-start not because it is slow in absolute terms (it is pretty aggressive already) but IIUC because before slow start people where even more aggressive (immediately sending at line rate?) I think we need immediate queue build-up feedback so each flow can look at its own growth projection and the queue space shrinkage projection and then determine where these two will meet. Essentially we need a gently way of ending slow-start instead of the old chestnut, dump twice as much data in flight into the network before we notice... it is this part that is at odds with low latency. L4s, true to form with its essential bit-banging of queue filling status over all flows in the LL queue is essentially givvin too little information too late. If I had a better proposal for a slow-start altenative I would make it, but for me slow-start is similar to what Churchill is supposed to have said about democracy "democracy is the worst form of government – except for all the others that have been tried."... > > Bob ^ permalink raw reply [flat|nested] 14+ messages in thread
* Re: [Starlink] [Rpm] [LibreQoS] [EXTERNAL] Re: Researchers Seeking Probe Volunteers in USA 2023-03-13 20:00 ` Sebastian Moeller @ 2023-03-13 20:28 ` rjmcmahon 2023-03-14 4:27 ` [Starlink] On FiWi rjmcmahon 0 siblings, 1 reply; 14+ messages in thread From: rjmcmahon @ 2023-03-13 20:28 UTC (permalink / raw) To: Sebastian Moeller Cc: dan, Jeremy Austin, Rpm, libreqos, Dave Taht via Starlink, bloat > [SM] It is doe because: > a) TCP needs some capacity estimate > b) preferably quickly > c) in a way gentler than what was used before the congestion collapse. Right, but we're moving away from capacity shortages to a focus on better latencies. The speed of distributed compute (or speed of causality) is now mostly latency constrained. Also, it's impossible per Jaffe & others for a TCP link to figure out the on-demand capacity so trying to get one via a "broken control loop" seems futile. I believe control theory states control loops need to be an order greater than what they're trying to control. I don't think an app or transport layer can do more than make educated guesses at for its control loop. Using a rating might help with that but for sure it's not accurate in space-time samples. (Note: many APs are rated 60+ Watts. What's the actual? Has to be sampled and that's only a sample. This leads to poor PoE designs - but I digress.) Let's assume the transport layer should be designed to optimize the speed of causality. This also seems impossible because the e2e jitter is worse with respect to end host discovery so there seems no way to adapt from end host only. If it's true that the end can only guess, maybe the solution domain comes from incorporating network measurements via telemetry with the ECN or equivalent? And an app can signal to the network elements to capture the e2e telemetry. I think this all has to happen within a few RTTs if the transport or host app is going to adjust. Bob ^ permalink raw reply [flat|nested] 14+ messages in thread
* [Starlink] On FiWi 2023-03-13 20:28 ` rjmcmahon @ 2023-03-14 4:27 ` rjmcmahon 2023-03-14 11:10 ` Mike Puchol 0 siblings, 1 reply; 14+ messages in thread From: rjmcmahon @ 2023-03-14 4:27 UTC (permalink / raw) To: Sebastian Moeller Cc: dan, Jeremy Austin, Rpm, libreqos, Dave Taht via Starlink, bloat To change the topic - curious to thoughts on FiWi. Imagine a world with no copper cable called FiWi (Fiber,VCSEL/CMOS Radios, Antennas) and which is point to point inside a building connected to virtualized APs fiber hops away. Each remote radio head (RRH) would consume 5W or less and only when active. No need for things like zigbee, or meshes, or threads as each radio has a fiber connection via Corning's actifi or equivalent. Eliminate the AP/Client power imbalance. Plastics also can house smoke or other sensors. Some reminders from Paul Baran in 1994 (and from David Reed) o) Shorter range rf transceivers connected to fiber could produce a significant improvement - - tremendous improvement, really. o) a mixture of terrestrial links plus shorter range radio links has the effect of increasing by orders and orders of magnitude the amount of frequency spectrum that can be made available. o) By authorizing high power to support a few users to reach slightly longer distances we deprive ourselves of the opportunity to serve the many. o) Communications systems can be built with 10dB ratio o) Digital transmission when properly done allows a small signal to noise ratio to be used successfully to retrieve an error free signal. o) And, never forget, any transmission capacity not used is wasted forever, like water over the dam. Not using such techniques represent lost opportunity. And on waveguides: o) "Fiber transmission loss is ~0.5dB/km for single mode fiber, independent of modulation" o) “Copper cables and PCB traces are very frequency dependent. At 100Gb/s, the loss is in dB/inch." o) "Free space: the power density of the radio waves decreases with the square of distance from the transmitting antenna due to spreading of the electromagnetic energy in space according to the inverse square law" The sunk costs & long-lived parts of FiWi are the fiber and the CPE plastics & antennas, as CMOS radios+ & fiber/laser, e.g. VCSEL could be pluggable, allowing for field upgrades. Just like swapping out SFP in a data center. This approach basically drives out WiFi latency by eliminating shared queues and increases capacity by orders of magnitude by leveraging 10dB in the spatial dimension, all of which is achieved by a physical design. Just place enough RRHs as needed (similar to a pop up sprinkler in an irrigation system.) Start and build this for an MDU and the value of the building improves. Sadly, there seems no way to capture that value other than over long term use. It doesn't matter whether the leader of the HOA tries to capture the value or if a last mile provider tries. The value remains sunk or hidden with nothing on the asset side of the balance sheet. We've got a CAPEX spend that has to be made up via "OPEX returns" over years. But the asset is there. How do we do this? Bob ^ permalink raw reply [flat|nested] 14+ messages in thread
* Re: [Starlink] On FiWi 2023-03-14 4:27 ` [Starlink] On FiWi rjmcmahon @ 2023-03-14 11:10 ` Mike Puchol 2023-03-14 16:54 ` [Starlink] [Rpm] " Robert McMahon 2023-03-17 16:38 ` Dave Taht 0 siblings, 2 replies; 14+ messages in thread From: Mike Puchol @ 2023-03-14 11:10 UTC (permalink / raw) To: Dave Taht via Starlink; +Cc: libreqos, Rpm, bloat [-- Attachment #1: Type: text/plain, Size: 7399 bytes --] Hi Bob, You hit on a set of very valid points, which I'll complement with my views on where the industry (the bit of it that affects WISPs) is heading, and what I saw at the MWC in Barcelona. Love the FiWi term :-) I have seen the vendors that supply WISPs, such as Ubiquiti, Cambium, and Mimosa, but also newer entrants such as Tarana, increase the performance and on-paper specs of their equipment. My examples below are centered on the African market, if you operate in Europe or the US, where you can charge customers a higher install fee, or even charge them a break-up fee if they don't return equipment, the economics work. Where currently a ~$500 sector radio could serve ~60 endpoints, at a cost of ~$50 per endpoint (I use this term in place of ODU/CPE, the antenna that you mount on the roof), and supply ~2.5 Mbps CIR per endpoint, the evolution is now a ~$2,000+ sector radio, a $200 endpoint, capability for ~150 endpoints per sector, and ~25 Mbps CIR per endpoint. If every customer a WISP installs represents, say, $100 CAPEX at install time ($50 for the antenna + cabling, router, etc), and you charge a $30 install fee, you have $70 to recover, and you recover from the monthly contribution the customer makes. If the contribution after OPEX is, say, $10, it takes you 7 months to recover the full install cost. Not bad, doable even in low-income markets. Fast-forward to the next-generation version. Now, the CAPEX at install is $250, you need to recover $220, and it will take you 22 months, which is above the usual 18 months that investors look for. The focus, thereby, has to be the lever that has the largest effect on the unit economics - which is the per-customer cost. I have drawn what my ideal FiWi network would look like: Taking you through this - we start with a 1-port, low-cost EPON OLT (or you could go for 2, 4, 8 ports as you add capacity). This OLT has capacity for 64 ONUs on its single port. Instead of connecting the typical fiber infrastructure with kilometers of cables which break, require maintenance, etc. we insert an EPON to Ethernet converter (I added "magic" because these don't exist AFAIK). This converter allows us to connect our $2k sector radio, and serve the $200 endpoints (ODUs) over wireless point-to-multipoint up to 10km away. Each ODU then has a reverse converter, which gives us EPON again. Once we are back on EPON, we can insert splitters, for example, pre-connectorized outdoor 1:16 boxes. Every customer install now involves a 100 meter roll of pre-connectorized 2-core drop cable, and a $20 EPON ONU. Using this deployment method, we could connect up to 16 customers to a single $200 endpoint, so the enpoint CAPEX per customer is now $12.5. Add the ONU, cable, etc. and we have a per-install CAPEX of $82.5 (assuming the same $50 of extras we had before), and an even shorter break-even. In addition, as the endpoints support higher capacity, we can provision at least the same, if not more, capacity per customer. Other advantages: the $200 ODU is no longer customer equipment and CAPEX, but network equipment, and as such, can operate under a longer break-even timeline, and be financed by infrastructure PE funds, for example. As a result, churn has a much lower financial impact on the operator. The main reason why this wouldn't work today is that EPON, as we know, is synchronous, and requires the OLT to orchestrate the amount of time each ONU can transmit, and when. Having wireless hops and media conversions will introduce latencies which can break down the communications (e.g. one ONU may transmit, get delayed on the radio link, and end up overlapping another ONU that transmitted on the next slot). Thus, either the "magic" box needs to account for this, or an new hybrid EPON-wireless protocol developed. My main point here: the industry is moving away from the unconnected. All the claims I heard and saw at MWC about "connecting the unconnected" had zero resonance with the financial drivers that the unconnected really operate under, on top of IT literacy, digital skills, devices, power... Best, Mike On Mar 14, 2023 at 05:27 +0100, rjmcmahon via Starlink <starlink@lists.bufferbloat.net>, wrote: > To change the topic - curious to thoughts on FiWi. > > Imagine a world with no copper cable called FiWi (Fiber,VCSEL/CMOS > Radios, Antennas) and which is point to point inside a building > connected to virtualized APs fiber hops away. Each remote radio head > (RRH) would consume 5W or less and only when active. No need for things > like zigbee, or meshes, or threads as each radio has a fiber connection > via Corning's actifi or equivalent. Eliminate the AP/Client power > imbalance. Plastics also can house smoke or other sensors. > > Some reminders from Paul Baran in 1994 (and from David Reed) > > o) Shorter range rf transceivers connected to fiber could produce a > significant improvement - - tremendous improvement, really. > o) a mixture of terrestrial links plus shorter range radio links has the > effect of increasing by orders and orders of magnitude the amount of > frequency spectrum that can be made available. > o) By authorizing high power to support a few users to reach slightly > longer distances we deprive ourselves of the opportunity to serve the > many. > o) Communications systems can be built with 10dB ratio > o) Digital transmission when properly done allows a small signal to > noise ratio to be used successfully to retrieve an error free signal. > o) And, never forget, any transmission capacity not used is wasted > forever, like water over the dam. Not using such techniques represent > lost opportunity. > > And on waveguides: > > o) "Fiber transmission loss is ~0.5dB/km for single mode fiber, > independent of modulation" > o) “Copper cables and PCB traces are very frequency dependent. At > 100Gb/s, the loss is in dB/inch." > o) "Free space: the power density of the radio waves decreases with the > square of distance from the transmitting antenna due to spreading of the > electromagnetic energy in space according to the inverse square law" > > The sunk costs & long-lived parts of FiWi are the fiber and the CPE > plastics & antennas, as CMOS radios+ & fiber/laser, e.g. VCSEL could be > pluggable, allowing for field upgrades. Just like swapping out SFP in a > data center. > > This approach basically drives out WiFi latency by eliminating shared > queues and increases capacity by orders of magnitude by leveraging 10dB > in the spatial dimension, all of which is achieved by a physical design. > Just place enough RRHs as needed (similar to a pop up sprinkler in an > irrigation system.) > > Start and build this for an MDU and the value of the building improves. > Sadly, there seems no way to capture that value other than over long > term use. It doesn't matter whether the leader of the HOA tries to > capture the value or if a last mile provider tries. The value remains > sunk or hidden with nothing on the asset side of the balance sheet. > We've got a CAPEX spend that has to be made up via "OPEX returns" over > years. > > But the asset is there. > > How do we do this? > > Bob > _______________________________________________ > Starlink mailing list > Starlink@lists.bufferbloat.net > https://lists.bufferbloat.net/listinfo/starlink [-- Attachment #2.1: Type: text/html, Size: 8415 bytes --] [-- Attachment #2.2: Hybrid EPON-Wireless network.png --] [-- Type: image/png, Size: 149871 bytes --] ^ permalink raw reply [flat|nested] 14+ messages in thread
* Re: [Starlink] [Rpm] On FiWi 2023-03-14 11:10 ` Mike Puchol @ 2023-03-14 16:54 ` Robert McMahon 2023-03-14 17:06 ` Robert McMahon 2023-03-17 16:38 ` Dave Taht 1 sibling, 1 reply; 14+ messages in thread From: Robert McMahon @ 2023-03-14 16:54 UTC (permalink / raw) To: Mike Puchol; +Cc: Dave Taht via Starlink, Rpm, libreqos, bloat [-- Attachment #1: Type: text/plain, Size: 8913 bytes --] Hi Mike, I'm thinking more of fiber to the room. The last few meters are wifi everything else is fiber.. Those radios would be a max of 20' from the associated STA. Then at phy rates of 2.8Gb/s per spatial stream. The common MIMO is 2x2 so each radio head or wifi transceiver supports 5.6G, no queueing delay. Wholesale is $5 and retail $19.95 per pluggable transceiver. Sold at Home Depot next to the irrigation aisle. 10 per house is $199 and each room gets a dedicated 5.8G phy rate. Need more devices in a space? Pick an RRH with more cmos radios. Also, the antennas would be patch antenna and fill the room properly. Then plug in an optional sensor for fire alerting. A digression. A lot of signal processing engineers have been working on TX beam forming. The best beam is fiber. Just do that. It even can turn corners and goes exactly to where it's needed at very low energies. This is similar to pvc pipes in irrigation systems. They're designed to take water to spray heads. The cost is the cable plant. That's labor more than materials. Similar for irrigation, pvc is inexpensive and lasts decades. A return labor means use future proof materials, e.g. fiber. Bob On Mar 14, 2023, 4:10 AM, at 4:10 AM, Mike Puchol via Rpm <rpm@lists.bufferbloat.net> wrote: >Hi Bob, > >You hit on a set of very valid points, which I'll complement with my >views on where the industry (the bit of it that affects WISPs) is >heading, and what I saw at the MWC in Barcelona. Love the FiWi term :-) > >I have seen the vendors that supply WISPs, such as Ubiquiti, Cambium, >and Mimosa, but also newer entrants such as Tarana, increase the >performance and on-paper specs of their equipment. My examples below >are centered on the African market, if you operate in Europe or the US, >where you can charge customers a higher install fee, or even charge >them a break-up fee if they don't return equipment, the economics work. > >Where currently a ~$500 sector radio could serve ~60 endpoints, at a >cost of ~$50 per endpoint (I use this term in place of ODU/CPE, the >antenna that you mount on the roof), and supply ~2.5 Mbps CIR per >endpoint, the evolution is now a ~$2,000+ sector radio, a $200 >endpoint, capability for ~150 endpoints per sector, and ~25 Mbps CIR >per endpoint. > >If every customer a WISP installs represents, say, $100 CAPEX at >install time ($50 for the antenna + cabling, router, etc), and you >charge a $30 install fee, you have $70 to recover, and you recover from >the monthly contribution the customer makes. If the contribution after >OPEX is, say, $10, it takes you 7 months to recover the full install >cost. Not bad, doable even in low-income markets. > >Fast-forward to the next-generation version. Now, the CAPEX at install >is $250, you need to recover $220, and it will take you 22 months, >which is above the usual 18 months that investors look for. > >The focus, thereby, has to be the lever that has the largest effect on >the unit economics - which is the per-customer cost. I have drawn what >my ideal FiWi network would look like: > > > >Taking you through this - we start with a 1-port, low-cost EPON OLT (or >you could go for 2, 4, 8 ports as you add capacity). This OLT has >capacity for 64 ONUs on its single port. Instead of connecting the >typical fiber infrastructure with kilometers of cables which break, >require maintenance, etc. we insert an EPON to Ethernet converter (I >added "magic" because these don't exist AFAIK). > >This converter allows us to connect our $2k sector radio, and serve the >$200 endpoints (ODUs) over wireless point-to-multipoint up to 10km >away. Each ODU then has a reverse converter, which gives us EPON again. > >Once we are back on EPON, we can insert splitters, for example, >pre-connectorized outdoor 1:16 boxes. Every customer install now >involves a 100 meter roll of pre-connectorized 2-core drop cable, and a >$20 EPON ONU. > >Using this deployment method, we could connect up to 16 customers to a >single $200 endpoint, so the enpoint CAPEX per customer is now $12.5. >Add the ONU, cable, etc. and we have a per-install CAPEX of $82.5 >(assuming the same $50 of extras we had before), and an even shorter >break-even. In addition, as the endpoints support higher capacity, we >can provision at least the same, if not more, capacity per customer. > >Other advantages: the $200 ODU is no longer customer equipment and >CAPEX, but network equipment, and as such, can operate under a longer >break-even timeline, and be financed by infrastructure PE funds, for >example. As a result, churn has a much lower financial impact on the >operator. > >The main reason why this wouldn't work today is that EPON, as we know, >is synchronous, and requires the OLT to orchestrate the amount of time >each ONU can transmit, and when. Having wireless hops and media >conversions will introduce latencies which can break down the >communications (e.g. one ONU may transmit, get delayed on the radio >link, and end up overlapping another ONU that transmitted on the next >slot). Thus, either the "magic" box needs to account for this, or an >new hybrid EPON-wireless protocol developed. > >My main point here: the industry is moving away from the unconnected. >All the claims I heard and saw at MWC about "connecting the >unconnected" had zero resonance with the financial drivers that the >unconnected really operate under, on top of IT literacy, digital >skills, devices, power... > >Best, > >Mike >On Mar 14, 2023 at 05:27 +0100, rjmcmahon via Starlink ><starlink@lists.bufferbloat.net>, wrote: >> To change the topic - curious to thoughts on FiWi. >> >> Imagine a world with no copper cable called FiWi (Fiber,VCSEL/CMOS >> Radios, Antennas) and which is point to point inside a building >> connected to virtualized APs fiber hops away. Each remote radio head >> (RRH) would consume 5W or less and only when active. No need for >things >> like zigbee, or meshes, or threads as each radio has a fiber >connection >> via Corning's actifi or equivalent. Eliminate the AP/Client power >> imbalance. Plastics also can house smoke or other sensors. >> >> Some reminders from Paul Baran in 1994 (and from David Reed) >> >> o) Shorter range rf transceivers connected to fiber could produce a >> significant improvement - - tremendous improvement, really. >> o) a mixture of terrestrial links plus shorter range radio links has >the >> effect of increasing by orders and orders of magnitude the amount of >> frequency spectrum that can be made available. >> o) By authorizing high power to support a few users to reach slightly >> longer distances we deprive ourselves of the opportunity to serve the >> many. >> o) Communications systems can be built with 10dB ratio >> o) Digital transmission when properly done allows a small signal to >> noise ratio to be used successfully to retrieve an error free signal. >> o) And, never forget, any transmission capacity not used is wasted >> forever, like water over the dam. Not using such techniques represent >> lost opportunity. >> >> And on waveguides: >> >> o) "Fiber transmission loss is ~0.5dB/km for single mode fiber, >> independent of modulation" >> o) “Copper cables and PCB traces are very frequency dependent. At >> 100Gb/s, the loss is in dB/inch." >> o) "Free space: the power density of the radio waves decreases with >the >> square of distance from the transmitting antenna due to spreading of >the >> electromagnetic energy in space according to the inverse square law" >> >> The sunk costs & long-lived parts of FiWi are the fiber and the CPE >> plastics & antennas, as CMOS radios+ & fiber/laser, e.g. VCSEL could >be >> pluggable, allowing for field upgrades. Just like swapping out SFP in >a >> data center. >> >> This approach basically drives out WiFi latency by eliminating shared >> queues and increases capacity by orders of magnitude by leveraging >10dB >> in the spatial dimension, all of which is achieved by a physical >design. >> Just place enough RRHs as needed (similar to a pop up sprinkler in an >> irrigation system.) >> >> Start and build this for an MDU and the value of the building >improves. >> Sadly, there seems no way to capture that value other than over long >> term use. It doesn't matter whether the leader of the HOA tries to >> capture the value or if a last mile provider tries. The value remains >> sunk or hidden with nothing on the asset side of the balance sheet. >> We've got a CAPEX spend that has to be made up via "OPEX returns" >over >> years. >> >> But the asset is there. >> >> How do we do this? >> >> Bob >> _______________________________________________ >> Starlink mailing list >> Starlink@lists.bufferbloat.net >> https://lists.bufferbloat.net/listinfo/starlink [-- Attachment #2: Type: text/html, Size: 10121 bytes --] ^ permalink raw reply [flat|nested] 14+ messages in thread
* Re: [Starlink] [Rpm] On FiWi 2023-03-14 16:54 ` [Starlink] [Rpm] " Robert McMahon @ 2023-03-14 17:06 ` Robert McMahon 0 siblings, 0 replies; 14+ messages in thread From: Robert McMahon @ 2023-03-14 17:06 UTC (permalink / raw) To: Mike Puchol; +Cc: Dave Taht via Starlink, Rpm, libreqos, bloat [-- Attachment #1: Type: text/plain, Size: 9523 bytes --] The ISP could charge per radio head and manage the system from a FiWi head end which they own. Virtualize the APs. Get rid of SoC complexity and costly O&M via simplicity. Eliminate all the incremental engineering that has gone astray, e.g. bloat and over powered APs. Bob On Mar 14, 2023, 9:49 AM, at 9:49 AM, Robert McMahon <rjmcmahon@rjmcmahon.com> wrote: >Hi Mike, > >I'm thinking more of fiber to the room. The last few meters are wifi >everything else is fiber.. Those radios would be a max of 20' from the >associated STA. Then at phy rates of 2.8Gb/s per spatial stream. The >common MIMO is 2x2 so each radio head or wifi transceiver supports >5.6G, no queueing delay. Wholesale is $5 and retail $19.95 per >pluggable transceiver. Sold at Home Depot next to the irrigation aisle. >10 per house is $199 and each room gets a dedicated 5.8G phy rate. Need >more devices in a space? Pick an RRH with more cmos radios. Also, the >antennas would be patch antenna and fill the room properly. Then plug >in an optional sensor for fire alerting. > > >A digression. A lot of signal processing engineers have been working on >TX beam forming. The best beam is fiber. Just do that. It even can turn >corners and goes exactly to where it's needed at very low energies. >This is similar to pvc pipes in irrigation systems. They're designed to >take water to spray heads. > >The cost is the cable plant. That's labor more than materials. Similar >for irrigation, pvc is inexpensive and lasts decades. A return labor >means use future proof materials, e.g. fiber. > >Bob > > > >On Mar 14, 2023, 4:10 AM, at 4:10 AM, Mike Puchol via Rpm ><rpm@lists.bufferbloat.net> wrote: >>Hi Bob, >> >>You hit on a set of very valid points, which I'll complement with my >>views on where the industry (the bit of it that affects WISPs) is >>heading, and what I saw at the MWC in Barcelona. Love the FiWi term >:-) >> >>I have seen the vendors that supply WISPs, such as Ubiquiti, Cambium, >>and Mimosa, but also newer entrants such as Tarana, increase the >>performance and on-paper specs of their equipment. My examples below >>are centered on the African market, if you operate in Europe or the >US, >>where you can charge customers a higher install fee, or even charge >>them a break-up fee if they don't return equipment, the economics >work. >> >>Where currently a ~$500 sector radio could serve ~60 endpoints, at a >>cost of ~$50 per endpoint (I use this term in place of ODU/CPE, the >>antenna that you mount on the roof), and supply ~2.5 Mbps CIR per >>endpoint, the evolution is now a ~$2,000+ sector radio, a $200 >>endpoint, capability for ~150 endpoints per sector, and ~25 Mbps CIR >>per endpoint. >> >>If every customer a WISP installs represents, say, $100 CAPEX at >>install time ($50 for the antenna + cabling, router, etc), and you >>charge a $30 install fee, you have $70 to recover, and you recover >from >>the monthly contribution the customer makes. If the contribution after >>OPEX is, say, $10, it takes you 7 months to recover the full install >>cost. Not bad, doable even in low-income markets. >> >>Fast-forward to the next-generation version. Now, the CAPEX at install >>is $250, you need to recover $220, and it will take you 22 months, >>which is above the usual 18 months that investors look for. >> >>The focus, thereby, has to be the lever that has the largest effect on >>the unit economics - which is the per-customer cost. I have drawn what >>my ideal FiWi network would look like: >> >> >> >>Taking you through this - we start with a 1-port, low-cost EPON OLT >(or >>you could go for 2, 4, 8 ports as you add capacity). This OLT has >>capacity for 64 ONUs on its single port. Instead of connecting the >>typical fiber infrastructure with kilometers of cables which break, >>require maintenance, etc. we insert an EPON to Ethernet converter (I >>added "magic" because these don't exist AFAIK). >> >>This converter allows us to connect our $2k sector radio, and serve >the >>$200 endpoints (ODUs) over wireless point-to-multipoint up to 10km >>away. Each ODU then has a reverse converter, which gives us EPON >again. >> >>Once we are back on EPON, we can insert splitters, for example, >>pre-connectorized outdoor 1:16 boxes. Every customer install now >>involves a 100 meter roll of pre-connectorized 2-core drop cable, and >a >>$20 EPON ONU. >> >>Using this deployment method, we could connect up to 16 customers to a >>single $200 endpoint, so the enpoint CAPEX per customer is now $12.5. >>Add the ONU, cable, etc. and we have a per-install CAPEX of $82.5 >>(assuming the same $50 of extras we had before), and an even shorter >>break-even. In addition, as the endpoints support higher capacity, we >>can provision at least the same, if not more, capacity per customer. >> >>Other advantages: the $200 ODU is no longer customer equipment and >>CAPEX, but network equipment, and as such, can operate under a longer >>break-even timeline, and be financed by infrastructure PE funds, for >>example. As a result, churn has a much lower financial impact on the >>operator. >> >>The main reason why this wouldn't work today is that EPON, as we know, >>is synchronous, and requires the OLT to orchestrate the amount of time >>each ONU can transmit, and when. Having wireless hops and media >>conversions will introduce latencies which can break down the >>communications (e.g. one ONU may transmit, get delayed on the radio >>link, and end up overlapping another ONU that transmitted on the next >>slot). Thus, either the "magic" box needs to account for this, or an >>new hybrid EPON-wireless protocol developed. >> >>My main point here: the industry is moving away from the unconnected. >>All the claims I heard and saw at MWC about "connecting the >>unconnected" had zero resonance with the financial drivers that the >>unconnected really operate under, on top of IT literacy, digital >>skills, devices, power... >> >>Best, >> >>Mike >>On Mar 14, 2023 at 05:27 +0100, rjmcmahon via Starlink >><starlink@lists.bufferbloat.net>, wrote: >>> To change the topic - curious to thoughts on FiWi. >>> >>> Imagine a world with no copper cable called FiWi (Fiber,VCSEL/CMOS >>> Radios, Antennas) and which is point to point inside a building >>> connected to virtualized APs fiber hops away. Each remote radio head >>> (RRH) would consume 5W or less and only when active. No need for >>things >>> like zigbee, or meshes, or threads as each radio has a fiber >>connection >>> via Corning's actifi or equivalent. Eliminate the AP/Client power >>> imbalance. Plastics also can house smoke or other sensors. >>> >>> Some reminders from Paul Baran in 1994 (and from David Reed) >>> >>> o) Shorter range rf transceivers connected to fiber could produce a >>> significant improvement - - tremendous improvement, really. >>> o) a mixture of terrestrial links plus shorter range radio links has >>the >>> effect of increasing by orders and orders of magnitude the amount of >>> frequency spectrum that can be made available. >>> o) By authorizing high power to support a few users to reach >slightly >>> longer distances we deprive ourselves of the opportunity to serve >the >>> many. >>> o) Communications systems can be built with 10dB ratio >>> o) Digital transmission when properly done allows a small signal to >>> noise ratio to be used successfully to retrieve an error free >signal. >>> o) And, never forget, any transmission capacity not used is wasted >>> forever, like water over the dam. Not using such techniques >represent >>> lost opportunity. >>> >>> And on waveguides: >>> >>> o) "Fiber transmission loss is ~0.5dB/km for single mode fiber, >>> independent of modulation" >>> o) “Copper cables and PCB traces are very frequency dependent. At >>> 100Gb/s, the loss is in dB/inch." >>> o) "Free space: the power density of the radio waves decreases with >>the >>> square of distance from the transmitting antenna due to spreading of >>the >>> electromagnetic energy in space according to the inverse square law" >>> >>> The sunk costs & long-lived parts of FiWi are the fiber and the CPE >>> plastics & antennas, as CMOS radios+ & fiber/laser, e.g. VCSEL could >>be >>> pluggable, allowing for field upgrades. Just like swapping out SFP >in >>a >>> data center. >>> >>> This approach basically drives out WiFi latency by eliminating >shared >>> queues and increases capacity by orders of magnitude by leveraging >>10dB >>> in the spatial dimension, all of which is achieved by a physical >>design. >>> Just place enough RRHs as needed (similar to a pop up sprinkler in >an >>> irrigation system.) >>> >>> Start and build this for an MDU and the value of the building >>improves. >>> Sadly, there seems no way to capture that value other than over long >>> term use. It doesn't matter whether the leader of the HOA tries to >>> capture the value or if a last mile provider tries. The value >remains >>> sunk or hidden with nothing on the asset side of the balance sheet. >>> We've got a CAPEX spend that has to be made up via "OPEX returns" >>over >>> years. >>> >>> But the asset is there. >>> >>> How do we do this? >>> >>> Bob >>> _______________________________________________ >>> Starlink mailing list >>> Starlink@lists.bufferbloat.net >>> https://lists.bufferbloat.net/listinfo/starlink [-- Attachment #2: Type: text/html, Size: 10771 bytes --] ^ permalink raw reply [flat|nested] 14+ messages in thread
* Re: [Starlink] [Rpm] On FiWi 2023-03-14 11:10 ` Mike Puchol 2023-03-14 16:54 ` [Starlink] [Rpm] " Robert McMahon @ 2023-03-17 16:38 ` Dave Taht 2023-03-17 18:21 ` Mike Puchol 2023-03-17 19:01 ` Sebastian Moeller 1 sibling, 2 replies; 14+ messages in thread From: Dave Taht @ 2023-03-17 16:38 UTC (permalink / raw) To: Mike Puchol; +Cc: Dave Taht via Starlink, Rpm, libreqos, bloat [-- Attachment #1.1: Type: text/plain, Size: 8135 bytes --] This is a pretty neat box: https://mikrotik.com/product/netpower_lite_7r What are the compelling arguments for fiber vs copper, again? On Tue, Mar 14, 2023 at 4:10 AM Mike Puchol via Rpm < rpm@lists.bufferbloat.net> wrote: > Hi Bob, > > You hit on a set of very valid points, which I'll complement with my views > on where the industry (the bit of it that affects WISPs) is heading, and > what I saw at the MWC in Barcelona. Love the FiWi term :-) > > I have seen the vendors that supply WISPs, such as Ubiquiti, Cambium, and > Mimosa, but also newer entrants such as Tarana, increase the performance > and on-paper specs of their equipment. My examples below are centered on > the African market, if you operate in Europe or the US, where you can > charge customers a higher install fee, or even charge them a break-up fee > if they don't return equipment, the economics work. > > Where currently a ~$500 sector radio could serve ~60 endpoints, at a cost > of ~$50 per endpoint (I use this term in place of ODU/CPE, the antenna that > you mount on the roof), and supply ~2.5 Mbps CIR per endpoint, the > evolution is now a ~$2,000+ sector radio, a $200 endpoint, capability for > ~150 endpoints per sector, and ~25 Mbps CIR per endpoint. > > If every customer a WISP installs represents, say, $100 CAPEX at install > time ($50 for the antenna + cabling, router, etc), and you charge a $30 > install fee, you have $70 to recover, and you recover from the monthly > contribution the customer makes. If the contribution after OPEX is, say, > $10, it takes you 7 months to recover the full install cost. Not bad, > doable even in low-income markets. > > Fast-forward to the next-generation version. Now, the CAPEX at install is > $250, you need to recover $220, and it will take you 22 months, which is > above the usual 18 months that investors look for. > > The focus, thereby, has to be the lever that has the largest effect on the > unit economics - which is the per-customer cost. I have drawn what my ideal > FiWi network would look like: > > > > Taking you through this - we start with a 1-port, low-cost EPON OLT (or > you could go for 2, 4, 8 ports as you add capacity). This OLT has capacity > for 64 ONUs on its single port. Instead of connecting the typical fiber > infrastructure with kilometers of cables which break, require maintenance, > etc. we insert an EPON to Ethernet converter (I added "magic" because these > don't exist AFAIK). > > This converter allows us to connect our $2k sector radio, and serve the > $200 endpoints (ODUs) over wireless point-to-multipoint up to 10km away. > Each ODU then has a reverse converter, which gives us EPON again. > > Once we are back on EPON, we can insert splitters, for example, > pre-connectorized outdoor 1:16 boxes. Every customer install now involves a > 100 meter roll of pre-connectorized 2-core drop cable, and a $20 EPON ONU. > > Using this deployment method, we could connect up to 16 customers to a > single $200 endpoint, so the enpoint CAPEX per customer is now $12.5. Add > the ONU, cable, etc. and we have a per-install CAPEX of $82.5 (assuming the > same $50 of extras we had before), and an even shorter break-even. In > addition, as the endpoints support higher capacity, we can provision at > least the same, if not more, capacity per customer. > > Other advantages: the $200 ODU is no longer customer equipment and CAPEX, > but network equipment, and as such, can operate under a longer break-even > timeline, and be financed by infrastructure PE funds, for example. As a > result, churn has a much lower financial impact on the operator. > > The main reason why this wouldn't work today is that EPON, as we know, is > synchronous, and requires the OLT to orchestrate the amount of time each > ONU can transmit, and when. Having wireless hops and media conversions will > introduce latencies which can break down the communications (e.g. one ONU > may transmit, get delayed on the radio link, and end up overlapping another > ONU that transmitted on the next slot). Thus, either the "magic" box needs > to account for this, or an new hybrid EPON-wireless protocol developed. > > My main point here: the industry is moving away from the unconnected. All > the claims I heard and saw at MWC about "connecting the unconnected" had > zero resonance with the financial drivers that the unconnected really > operate under, on top of IT literacy, digital skills, devices, power... > > Best, > > Mike > On Mar 14, 2023 at 05:27 +0100, rjmcmahon via Starlink < > starlink@lists.bufferbloat.net>, wrote: > > To change the topic - curious to thoughts on FiWi. > > Imagine a world with no copper cable called FiWi (Fiber,VCSEL/CMOS > Radios, Antennas) and which is point to point inside a building > connected to virtualized APs fiber hops away. Each remote radio head > (RRH) would consume 5W or less and only when active. No need for things > like zigbee, or meshes, or threads as each radio has a fiber connection > via Corning's actifi or equivalent. Eliminate the AP/Client power > imbalance. Plastics also can house smoke or other sensors. > > Some reminders from Paul Baran in 1994 (and from David Reed) > > o) Shorter range rf transceivers connected to fiber could produce a > significant improvement - - tremendous improvement, really. > o) a mixture of terrestrial links plus shorter range radio links has the > effect of increasing by orders and orders of magnitude the amount of > frequency spectrum that can be made available. > o) By authorizing high power to support a few users to reach slightly > longer distances we deprive ourselves of the opportunity to serve the > many. > o) Communications systems can be built with 10dB ratio > o) Digital transmission when properly done allows a small signal to > noise ratio to be used successfully to retrieve an error free signal. > o) And, never forget, any transmission capacity not used is wasted > forever, like water over the dam. Not using such techniques represent > lost opportunity. > > And on waveguides: > > o) "Fiber transmission loss is ~0.5dB/km for single mode fiber, > independent of modulation" > o) “Copper cables and PCB traces are very frequency dependent. At > 100Gb/s, the loss is in dB/inch." > o) "Free space: the power density of the radio waves decreases with the > square of distance from the transmitting antenna due to spreading of the > electromagnetic energy in space according to the inverse square law" > > The sunk costs & long-lived parts of FiWi are the fiber and the CPE > plastics & antennas, as CMOS radios+ & fiber/laser, e.g. VCSEL could be > pluggable, allowing for field upgrades. Just like swapping out SFP in a > data center. > > This approach basically drives out WiFi latency by eliminating shared > queues and increases capacity by orders of magnitude by leveraging 10dB > in the spatial dimension, all of which is achieved by a physical design. > Just place enough RRHs as needed (similar to a pop up sprinkler in an > irrigation system.) > > Start and build this for an MDU and the value of the building improves. > Sadly, there seems no way to capture that value other than over long > term use. It doesn't matter whether the leader of the HOA tries to > capture the value or if a last mile provider tries. The value remains > sunk or hidden with nothing on the asset side of the balance sheet. > We've got a CAPEX spend that has to be made up via "OPEX returns" over > years. > > But the asset is there. > > How do we do this? > > Bob > _______________________________________________ > Starlink mailing list > Starlink@lists.bufferbloat.net > https://lists.bufferbloat.net/listinfo/starlink > > _______________________________________________ > Rpm mailing list > Rpm@lists.bufferbloat.net > https://lists.bufferbloat.net/listinfo/rpm > -- Come Heckle Mar 6-9 at: https://www.understandinglatency.com <https://www.understandinglatency.com/Dave>/ Dave Täht CEO, TekLibre, LLC [-- Attachment #1.2: Type: text/html, Size: 9641 bytes --] [-- Attachment #2: Hybrid EPON-Wireless network.png --] [-- Type: image/png, Size: 149871 bytes --] ^ permalink raw reply [flat|nested] 14+ messages in thread
* Re: [Starlink] [Rpm] On FiWi 2023-03-17 16:38 ` Dave Taht @ 2023-03-17 18:21 ` Mike Puchol 2023-03-17 19:01 ` Sebastian Moeller 1 sibling, 0 replies; 14+ messages in thread From: Mike Puchol @ 2023-03-17 18:21 UTC (permalink / raw) To: Dave Taht; +Cc: Dave Taht via Starlink, Rpm, libreqos, bloat [-- Attachment #1: Type: text/plain, Size: 9113 bytes --] A four-port EPON OLT with modules goes for $500, serves up to 256 customers. To serve same amount you need 36 netPowers, at $140 each, total CAPEX $5,000. What you then spend on PON splitters you also spend on PoE injectors for the netPower, and drop cable is cheaper than Ethernet (at least if you want it to send power further than 10 meters… no CCA allowed). It’s not so clear-cut, each can fit a certain deployment scenario, so I would never argue in antagonistic terms. Best, Mike On Mar 17, 2023 at 17:38 +0100, Dave Taht <dave.taht@gmail.com>, wrote: > This is a pretty neat box: > > https://mikrotik.com/product/netpower_lite_7r > > What are the compelling arguments for fiber vs copper, again? > > > > On Tue, Mar 14, 2023 at 4:10 AM Mike Puchol via Rpm <rpm@lists.bufferbloat.net> wrote: > > > Hi Bob, > > > > > > You hit on a set of very valid points, which I'll complement with my views on where the industry (the bit of it that affects WISPs) is heading, and what I saw at the MWC in Barcelona. Love the FiWi term :-) > > > > > > I have seen the vendors that supply WISPs, such as Ubiquiti, Cambium, and Mimosa, but also newer entrants such as Tarana, increase the performance and on-paper specs of their equipment. My examples below are centered on the African market, if you operate in Europe or the US, where you can charge customers a higher install fee, or even charge them a break-up fee if they don't return equipment, the economics work. > > > > > > Where currently a ~$500 sector radio could serve ~60 endpoints, at a cost of ~$50 per endpoint (I use this term in place of ODU/CPE, the antenna that you mount on the roof), and supply ~2.5 Mbps CIR per endpoint, the evolution is now a ~$2,000+ sector radio, a $200 endpoint, capability for ~150 endpoints per sector, and ~25 Mbps CIR per endpoint. > > > > > > If every customer a WISP installs represents, say, $100 CAPEX at install time ($50 for the antenna + cabling, router, etc), and you charge a $30 install fee, you have $70 to recover, and you recover from the monthly contribution the customer makes. If the contribution after OPEX is, say, $10, it takes you 7 months to recover the full install cost. Not bad, doable even in low-income markets. > > > > > > Fast-forward to the next-generation version. Now, the CAPEX at install is $250, you need to recover $220, and it will take you 22 months, which is above the usual 18 months that investors look for. > > > > > > The focus, thereby, has to be the lever that has the largest effect on the unit economics - which is the per-customer cost. I have drawn what my ideal FiWi network would look like: > > > > > > > > > <Hybrid EPON-Wireless network.png> > > > Taking you through this - we start with a 1-port, low-cost EPON OLT (or you could go for 2, 4, 8 ports as you add capacity). This OLT has capacity for 64 ONUs on its single port. Instead of connecting the typical fiber infrastructure with kilometers of cables which break, require maintenance, etc. we insert an EPON to Ethernet converter (I added "magic" because these don't exist AFAIK). > > > > > > This converter allows us to connect our $2k sector radio, and serve the $200 endpoints (ODUs) over wireless point-to-multipoint up to 10km away. Each ODU then has a reverse converter, which gives us EPON again. > > > > > > Once we are back on EPON, we can insert splitters, for example, pre-connectorized outdoor 1:16 boxes. Every customer install now involves a 100 meter roll of pre-connectorized 2-core drop cable, and a $20 EPON ONU. > > > > > > Using this deployment method, we could connect up to 16 customers to a single $200 endpoint, so the enpoint CAPEX per customer is now $12.5. Add the ONU, cable, etc. and we have a per-install CAPEX of $82.5 (assuming the same $50 of extras we had before), and an even shorter break-even. In addition, as the endpoints support higher capacity, we can provision at least the same, if not more, capacity per customer. > > > > > > Other advantages: the $200 ODU is no longer customer equipment and CAPEX, but network equipment, and as such, can operate under a longer break-even timeline, and be financed by infrastructure PE funds, for example. As a result, churn has a much lower financial impact on the operator. > > > > > > The main reason why this wouldn't work today is that EPON, as we know, is synchronous, and requires the OLT to orchestrate the amount of time each ONU can transmit, and when. Having wireless hops and media conversions will introduce latencies which can break down the communications (e.g. one ONU may transmit, get delayed on the radio link, and end up overlapping another ONU that transmitted on the next slot). Thus, either the "magic" box needs to account for this, or an new hybrid EPON-wireless protocol developed. > > > > > > My main point here: the industry is moving away from the unconnected. All the claims I heard and saw at MWC about "connecting the unconnected" had zero resonance with the financial drivers that the unconnected really operate under, on top of IT literacy, digital skills, devices, power... > > > > > > Best, > > > > > > Mike > > > On Mar 14, 2023 at 05:27 +0100, rjmcmahon via Starlink <starlink@lists.bufferbloat.net>, wrote: > > > > To change the topic - curious to thoughts on FiWi. > > > > > > > > Imagine a world with no copper cable called FiWi (Fiber,VCSEL/CMOS > > > > Radios, Antennas) and which is point to point inside a building > > > > connected to virtualized APs fiber hops away. Each remote radio head > > > > (RRH) would consume 5W or less and only when active. No need for things > > > > like zigbee, or meshes, or threads as each radio has a fiber connection > > > > via Corning's actifi or equivalent. Eliminate the AP/Client power > > > > imbalance. Plastics also can house smoke or other sensors. > > > > > > > > Some reminders from Paul Baran in 1994 (and from David Reed) > > > > > > > > o) Shorter range rf transceivers connected to fiber could produce a > > > > significant improvement - - tremendous improvement, really. > > > > o) a mixture of terrestrial links plus shorter range radio links has the > > > > effect of increasing by orders and orders of magnitude the amount of > > > > frequency spectrum that can be made available. > > > > o) By authorizing high power to support a few users to reach slightly > > > > longer distances we deprive ourselves of the opportunity to serve the > > > > many. > > > > o) Communications systems can be built with 10dB ratio > > > > o) Digital transmission when properly done allows a small signal to > > > > noise ratio to be used successfully to retrieve an error free signal. > > > > o) And, never forget, any transmission capacity not used is wasted > > > > forever, like water over the dam. Not using such techniques represent > > > > lost opportunity. > > > > > > > > And on waveguides: > > > > > > > > o) "Fiber transmission loss is ~0.5dB/km for single mode fiber, > > > > independent of modulation" > > > > o) “Copper cables and PCB traces are very frequency dependent. At > > > > 100Gb/s, the loss is in dB/inch." > > > > o) "Free space: the power density of the radio waves decreases with the > > > > square of distance from the transmitting antenna due to spreading of the > > > > electromagnetic energy in space according to the inverse square law" > > > > > > > > The sunk costs & long-lived parts of FiWi are the fiber and the CPE > > > > plastics & antennas, as CMOS radios+ & fiber/laser, e.g. VCSEL could be > > > > pluggable, allowing for field upgrades. Just like swapping out SFP in a > > > > data center. > > > > > > > > This approach basically drives out WiFi latency by eliminating shared > > > > queues and increases capacity by orders of magnitude by leveraging 10dB > > > > in the spatial dimension, all of which is achieved by a physical design. > > > > Just place enough RRHs as needed (similar to a pop up sprinkler in an > > > > irrigation system.) > > > > > > > > Start and build this for an MDU and the value of the building improves. > > > > Sadly, there seems no way to capture that value other than over long > > > > term use. It doesn't matter whether the leader of the HOA tries to > > > > capture the value or if a last mile provider tries. The value remains > > > > sunk or hidden with nothing on the asset side of the balance sheet. > > > > We've got a CAPEX spend that has to be made up via "OPEX returns" over > > > > years. > > > > > > > > But the asset is there. > > > > > > > > How do we do this? > > > > > > > > Bob > > > > _______________________________________________ > > > > Starlink mailing list > > > > Starlink@lists.bufferbloat.net > > > > https://lists.bufferbloat.net/listinfo/starlink > > > _______________________________________________ > > > Rpm mailing list > > > Rpm@lists.bufferbloat.net > > > https://lists.bufferbloat.net/listinfo/rpm > > > -- > Come Heckle Mar 6-9 at: https://www.understandinglatency.com/ > Dave Täht CEO, TekLibre, LLC [-- Attachment #2: Type: text/html, Size: 10844 bytes --] ^ permalink raw reply [flat|nested] 14+ messages in thread
* Re: [Starlink] [Rpm] On FiWi 2023-03-17 16:38 ` Dave Taht 2023-03-17 18:21 ` Mike Puchol @ 2023-03-17 19:01 ` Sebastian Moeller 2023-03-17 19:19 ` rjmcmahon 1 sibling, 1 reply; 14+ messages in thread From: Sebastian Moeller @ 2023-03-17 19:01 UTC (permalink / raw) To: Dave Täht; +Cc: Mike Puchol, Dave Taht via Starlink, Rpm, libreqos, bloat Hi Dave, > On Mar 17, 2023, at 17:38, Dave Taht via Starlink <starlink@lists.bufferbloat.net> wrote: > > This is a pretty neat box: > > https://mikrotik.com/product/netpower_lite_7r > > What are the compelling arguments for fiber vs copper, again? As far as I can tell: Copper: can carry electric power Fiber-PON: much farther reach even without amplifiers (10 Km, 20 Km, ... depending on loss budget) cheaper operation (less active power needed by the headend/OLT) less space need than all active alternatives (AON, copper ethernet) likely only robust passive components in the field Existing upgrade path for 25G and 50G is on the horizon over the same PON infrastructure mostly resistant to RF ingress along the path (as long as a direct lightning hit does not melt the glas ;) ) Fiber-Ethernet: like fiber-PON but no density advantage (needs 1 port per end device) even wider upgrade paths I guess it really depends on how important "carry electric power" is to you ;) feeding these from the client side is pretty cool for consenting adults, but I would prefer not having to pay the electric bill for my ISPs active gear in the field outside the CPE/ONT... Regards Sebastian > > > On Tue, Mar 14, 2023 at 4:10 AM Mike Puchol via Rpm <rpm@lists.bufferbloat.net> wrote: > Hi Bob, > > You hit on a set of very valid points, which I'll complement with my views on where the industry (the bit of it that affects WISPs) is heading, and what I saw at the MWC in Barcelona. Love the FiWi term :-) > > I have seen the vendors that supply WISPs, such as Ubiquiti, Cambium, and Mimosa, but also newer entrants such as Tarana, increase the performance and on-paper specs of their equipment. My examples below are centered on the African market, if you operate in Europe or the US, where you can charge customers a higher install fee, or even charge them a break-up fee if they don't return equipment, the economics work. > > Where currently a ~$500 sector radio could serve ~60 endpoints, at a cost of ~$50 per endpoint (I use this term in place of ODU/CPE, the antenna that you mount on the roof), and supply ~2.5 Mbps CIR per endpoint, the evolution is now a ~$2,000+ sector radio, a $200 endpoint, capability for ~150 endpoints per sector, and ~25 Mbps CIR per endpoint. > > If every customer a WISP installs represents, say, $100 CAPEX at install time ($50 for the antenna + cabling, router, etc), and you charge a $30 install fee, you have $70 to recover, and you recover from the monthly contribution the customer makes. If the contribution after OPEX is, say, $10, it takes you 7 months to recover the full install cost. Not bad, doable even in low-income markets. > > Fast-forward to the next-generation version. Now, the CAPEX at install is $250, you need to recover $220, and it will take you 22 months, which is above the usual 18 months that investors look for. > > The focus, thereby, has to be the lever that has the largest effect on the unit economics - which is the per-customer cost. I have drawn what my ideal FiWi network would look like: > > > <Hybrid EPON-Wireless network.png> > Taking you through this - we start with a 1-port, low-cost EPON OLT (or you could go for 2, 4, 8 ports as you add capacity). This OLT has capacity for 64 ONUs on its single port. Instead of connecting the typical fiber infrastructure with kilometers of cables which break, require maintenance, etc. we insert an EPON to Ethernet converter (I added "magic" because these don't exist AFAIK). > > This converter allows us to connect our $2k sector radio, and serve the $200 endpoints (ODUs) over wireless point-to-multipoint up to 10km away. Each ODU then has a reverse converter, which gives us EPON again. > > Once we are back on EPON, we can insert splitters, for example, pre-connectorized outdoor 1:16 boxes. Every customer install now involves a 100 meter roll of pre-connectorized 2-core drop cable, and a $20 EPON ONU. > > Using this deployment method, we could connect up to 16 customers to a single $200 endpoint, so the enpoint CAPEX per customer is now $12.5. Add the ONU, cable, etc. and we have a per-install CAPEX of $82.5 (assuming the same $50 of extras we had before), and an even shorter break-even. In addition, as the endpoints support higher capacity, we can provision at least the same, if not more, capacity per customer. > > Other advantages: the $200 ODU is no longer customer equipment and CAPEX, but network equipment, and as such, can operate under a longer break-even timeline, and be financed by infrastructure PE funds, for example. As a result, churn has a much lower financial impact on the operator. > > The main reason why this wouldn't work today is that EPON, as we know, is synchronous, and requires the OLT to orchestrate the amount of time each ONU can transmit, and when. Having wireless hops and media conversions will introduce latencies which can break down the communications (e.g. one ONU may transmit, get delayed on the radio link, and end up overlapping another ONU that transmitted on the next slot). Thus, either the "magic" box needs to account for this, or an new hybrid EPON-wireless protocol developed. > > My main point here: the industry is moving away from the unconnected. All the claims I heard and saw at MWC about "connecting the unconnected" had zero resonance with the financial drivers that the unconnected really operate under, on top of IT literacy, digital skills, devices, power... > > Best, > > Mike > On Mar 14, 2023 at 05:27 +0100, rjmcmahon via Starlink <starlink@lists.bufferbloat.net>, wrote: >> To change the topic - curious to thoughts on FiWi. >> >> Imagine a world with no copper cable called FiWi (Fiber,VCSEL/CMOS >> Radios, Antennas) and which is point to point inside a building >> connected to virtualized APs fiber hops away. Each remote radio head >> (RRH) would consume 5W or less and only when active. No need for things >> like zigbee, or meshes, or threads as each radio has a fiber connection >> via Corning's actifi or equivalent. Eliminate the AP/Client power >> imbalance. Plastics also can house smoke or other sensors. >> >> Some reminders from Paul Baran in 1994 (and from David Reed) >> >> o) Shorter range rf transceivers connected to fiber could produce a >> significant improvement - - tremendous improvement, really. >> o) a mixture of terrestrial links plus shorter range radio links has the >> effect of increasing by orders and orders of magnitude the amount of >> frequency spectrum that can be made available. >> o) By authorizing high power to support a few users to reach slightly >> longer distances we deprive ourselves of the opportunity to serve the >> many. >> o) Communications systems can be built with 10dB ratio >> o) Digital transmission when properly done allows a small signal to >> noise ratio to be used successfully to retrieve an error free signal. >> o) And, never forget, any transmission capacity not used is wasted >> forever, like water over the dam. Not using such techniques represent >> lost opportunity. >> >> And on waveguides: >> >> o) "Fiber transmission loss is ~0.5dB/km for single mode fiber, >> independent of modulation" >> o) “Copper cables and PCB traces are very frequency dependent. At >> 100Gb/s, the loss is in dB/inch." >> o) "Free space: the power density of the radio waves decreases with the >> square of distance from the transmitting antenna due to spreading of the >> electromagnetic energy in space according to the inverse square law" >> >> The sunk costs & long-lived parts of FiWi are the fiber and the CPE >> plastics & antennas, as CMOS radios+ & fiber/laser, e.g. VCSEL could be >> pluggable, allowing for field upgrades. Just like swapping out SFP in a >> data center. >> >> This approach basically drives out WiFi latency by eliminating shared >> queues and increases capacity by orders of magnitude by leveraging 10dB >> in the spatial dimension, all of which is achieved by a physical design. >> Just place enough RRHs as needed (similar to a pop up sprinkler in an >> irrigation system.) >> >> Start and build this for an MDU and the value of the building improves. >> Sadly, there seems no way to capture that value other than over long >> term use. It doesn't matter whether the leader of the HOA tries to >> capture the value or if a last mile provider tries. The value remains >> sunk or hidden with nothing on the asset side of the balance sheet. >> We've got a CAPEX spend that has to be made up via "OPEX returns" over >> years. >> >> But the asset is there. >> >> How do we do this? >> >> Bob >> _______________________________________________ >> Starlink mailing list >> Starlink@lists.bufferbloat.net >> https://lists.bufferbloat.net/listinfo/starlink > _______________________________________________ > Rpm mailing list > Rpm@lists.bufferbloat.net > https://lists.bufferbloat.net/listinfo/rpm > > > -- > Come Heckle Mar 6-9 at: https://www.understandinglatency.com/ > Dave Täht CEO, TekLibre, LLC > _______________________________________________ > Starlink mailing list > Starlink@lists.bufferbloat.net > https://lists.bufferbloat.net/listinfo/starlink ^ permalink raw reply [flat|nested] 14+ messages in thread
* Re: [Starlink] [Rpm] On FiWi 2023-03-17 19:01 ` Sebastian Moeller @ 2023-03-17 19:19 ` rjmcmahon 2023-03-17 20:37 ` Bruce Perens 0 siblings, 1 reply; 14+ messages in thread From: rjmcmahon @ 2023-03-17 19:19 UTC (permalink / raw) To: Sebastian Moeller Cc: Dave Täht, Dave Taht via Starlink, Mike Puchol, bloat, Rpm, libreqos I think the low-power transceiver (or RRH) and fiber fronthaul is doable within the next 5 years. The difficult part to me seems the virtual APs that could service 12-256 RRHs including security monitoring & customer privacy. Is there a VMWARE NSX approach to reducing the O&M costs by at least 1/2 for the FiWi head end systems? For power: My approach to the Boston historic neighborhood where my kids now live would be AC wired CPE treated as critical, life support infrastructure. But better may be to do as modern garage door openers and have standard AC charge a battery so one can operate even during power outages. https://www.rsandrews.com/blog/hardwired-battery-powered-smoke-alarms-you/ Our Recommendation: Hardwired Smoke Alarms Hardwired smoke alarms, while they require slightly more work upfront, are the clear choice if you’re considering replacing your home’s smoke alarm system. You’ll hardly ever have to deal with the annoying “chirping” that occurs when a battery-powered smoke detector begins to go dead, and your entire family will be alerted in the event that a fire does occur since hardwire smoke detectors can be interconnected. Bob > Hi Dave, > > > >> On Mar 17, 2023, at 17:38, Dave Taht via Starlink >> <starlink@lists.bufferbloat.net> wrote: >> >> This is a pretty neat box: >> >> https://mikrotik.com/product/netpower_lite_7r >> >> What are the compelling arguments for fiber vs copper, again? > > As far as I can tell: > > Copper: > can carry electric power > > Fiber-PON: > much farther reach even without amplifiers (10 Km, 20 Km, ... > depending on loss budget) > cheaper operation (less active power needed by the headend/OLT) > less space need than all active alternatives (AON, copper ethernet) > likely only robust passive components in the field > Existing upgrade path for 25G and 50G is on the horizon over the same > PON infrastructure > mostly resistant to RF ingress along the path (as long as a direct > lightning hit does not melt the glas ;) ) > > Fiber-Ethernet: > like fiber-PON but > no density advantage (needs 1 port per end device) > even wider upgrade paths > > > I guess it really depends on how important "carry electric power" is > to you ;) feeding these from the client side is pretty cool for > consenting adults, but I would prefer not having to pay the electric > bill for my ISPs active gear in the field outside the CPE/ONT... > > Regards > Sebastian > > >> >> >> On Tue, Mar 14, 2023 at 4:10 AM Mike Puchol via Rpm >> <rpm@lists.bufferbloat.net> wrote: >> Hi Bob, >> >> You hit on a set of very valid points, which I'll complement with my >> views on where the industry (the bit of it that affects WISPs) is >> heading, and what I saw at the MWC in Barcelona. Love the FiWi term >> :-) >> >> I have seen the vendors that supply WISPs, such as Ubiquiti, Cambium, >> and Mimosa, but also newer entrants such as Tarana, increase the >> performance and on-paper specs of their equipment. My examples below >> are centered on the African market, if you operate in Europe or the >> US, where you can charge customers a higher install fee, or even >> charge them a break-up fee if they don't return equipment, the >> economics work. >> >> Where currently a ~$500 sector radio could serve ~60 endpoints, at a >> cost of ~$50 per endpoint (I use this term in place of ODU/CPE, the >> antenna that you mount on the roof), and supply ~2.5 Mbps CIR per >> endpoint, the evolution is now a ~$2,000+ sector radio, a $200 >> endpoint, capability for ~150 endpoints per sector, and ~25 Mbps CIR >> per endpoint. >> >> If every customer a WISP installs represents, say, $100 CAPEX at >> install time ($50 for the antenna + cabling, router, etc), and you >> charge a $30 install fee, you have $70 to recover, and you recover >> from the monthly contribution the customer makes. If the contribution >> after OPEX is, say, $10, it takes you 7 months to recover the full >> install cost. Not bad, doable even in low-income markets. >> >> Fast-forward to the next-generation version. Now, the CAPEX at install >> is $250, you need to recover $220, and it will take you 22 months, >> which is above the usual 18 months that investors look for. >> >> The focus, thereby, has to be the lever that has the largest effect on >> the unit economics - which is the per-customer cost. I have drawn what >> my ideal FiWi network would look like: >> >> >> <Hybrid EPON-Wireless network.png> >> Taking you through this - we start with a 1-port, low-cost EPON OLT >> (or you could go for 2, 4, 8 ports as you add capacity). This OLT has >> capacity for 64 ONUs on its single port. Instead of connecting the >> typical fiber infrastructure with kilometers of cables which break, >> require maintenance, etc. we insert an EPON to Ethernet converter (I >> added "magic" because these don't exist AFAIK). >> >> This converter allows us to connect our $2k sector radio, and serve >> the $200 endpoints (ODUs) over wireless point-to-multipoint up to 10km >> away. Each ODU then has a reverse converter, which gives us EPON >> again. >> >> Once we are back on EPON, we can insert splitters, for example, >> pre-connectorized outdoor 1:16 boxes. Every customer install now >> involves a 100 meter roll of pre-connectorized 2-core drop cable, and >> a $20 EPON ONU. >> >> Using this deployment method, we could connect up to 16 customers to a >> single $200 endpoint, so the enpoint CAPEX per customer is now $12.5. >> Add the ONU, cable, etc. and we have a per-install CAPEX of $82.5 >> (assuming the same $50 of extras we had before), and an even shorter >> break-even. In addition, as the endpoints support higher capacity, we >> can provision at least the same, if not more, capacity per customer. >> >> Other advantages: the $200 ODU is no longer customer equipment and >> CAPEX, but network equipment, and as such, can operate under a longer >> break-even timeline, and be financed by infrastructure PE funds, for >> example. As a result, churn has a much lower financial impact on the >> operator. >> >> The main reason why this wouldn't work today is that EPON, as we know, >> is synchronous, and requires the OLT to orchestrate the amount of time >> each ONU can transmit, and when. Having wireless hops and media >> conversions will introduce latencies which can break down the >> communications (e.g. one ONU may transmit, get delayed on the radio >> link, and end up overlapping another ONU that transmitted on the next >> slot). Thus, either the "magic" box needs to account for this, or an >> new hybrid EPON-wireless protocol developed. >> >> My main point here: the industry is moving away from the unconnected. >> All the claims I heard and saw at MWC about "connecting the >> unconnected" had zero resonance with the financial drivers that the >> unconnected really operate under, on top of IT literacy, digital >> skills, devices, power... >> >> Best, >> >> Mike >> On Mar 14, 2023 at 05:27 +0100, rjmcmahon via Starlink >> <starlink@lists.bufferbloat.net>, wrote: >>> To change the topic - curious to thoughts on FiWi. >>> >>> Imagine a world with no copper cable called FiWi (Fiber,VCSEL/CMOS >>> Radios, Antennas) and which is point to point inside a building >>> connected to virtualized APs fiber hops away. Each remote radio head >>> (RRH) would consume 5W or less and only when active. No need for >>> things >>> like zigbee, or meshes, or threads as each radio has a fiber >>> connection >>> via Corning's actifi or equivalent. Eliminate the AP/Client power >>> imbalance. Plastics also can house smoke or other sensors. >>> >>> Some reminders from Paul Baran in 1994 (and from David Reed) >>> >>> o) Shorter range rf transceivers connected to fiber could produce a >>> significant improvement - - tremendous improvement, really. >>> o) a mixture of terrestrial links plus shorter range radio links has >>> the >>> effect of increasing by orders and orders of magnitude the amount of >>> frequency spectrum that can be made available. >>> o) By authorizing high power to support a few users to reach slightly >>> longer distances we deprive ourselves of the opportunity to serve the >>> many. >>> o) Communications systems can be built with 10dB ratio >>> o) Digital transmission when properly done allows a small signal to >>> noise ratio to be used successfully to retrieve an error free signal. >>> o) And, never forget, any transmission capacity not used is wasted >>> forever, like water over the dam. Not using such techniques represent >>> lost opportunity. >>> >>> And on waveguides: >>> >>> o) "Fiber transmission loss is ~0.5dB/km for single mode fiber, >>> independent of modulation" >>> o) “Copper cables and PCB traces are very frequency dependent. At >>> 100Gb/s, the loss is in dB/inch." >>> o) "Free space: the power density of the radio waves decreases with >>> the >>> square of distance from the transmitting antenna due to spreading of >>> the >>> electromagnetic energy in space according to the inverse square law" >>> >>> The sunk costs & long-lived parts of FiWi are the fiber and the CPE >>> plastics & antennas, as CMOS radios+ & fiber/laser, e.g. VCSEL could >>> be >>> pluggable, allowing for field upgrades. Just like swapping out SFP in >>> a >>> data center. >>> >>> This approach basically drives out WiFi latency by eliminating shared >>> queues and increases capacity by orders of magnitude by leveraging >>> 10dB >>> in the spatial dimension, all of which is achieved by a physical >>> design. >>> Just place enough RRHs as needed (similar to a pop up sprinkler in an >>> irrigation system.) >>> >>> Start and build this for an MDU and the value of the building >>> improves. >>> Sadly, there seems no way to capture that value other than over long >>> term use. It doesn't matter whether the leader of the HOA tries to >>> capture the value or if a last mile provider tries. The value remains >>> sunk or hidden with nothing on the asset side of the balance sheet. >>> We've got a CAPEX spend that has to be made up via "OPEX returns" >>> over >>> years. >>> >>> But the asset is there. >>> >>> How do we do this? >>> >>> Bob >>> _______________________________________________ >>> Starlink mailing list >>> Starlink@lists.bufferbloat.net >>> https://lists.bufferbloat.net/listinfo/starlink >> _______________________________________________ >> Rpm mailing list >> Rpm@lists.bufferbloat.net >> https://lists.bufferbloat.net/listinfo/rpm >> >> >> -- >> Come Heckle Mar 6-9 at: https://www.understandinglatency.com/ >> Dave Täht CEO, TekLibre, LLC >> _______________________________________________ >> Starlink mailing list >> Starlink@lists.bufferbloat.net >> https://lists.bufferbloat.net/listinfo/starlink > > _______________________________________________ > Rpm mailing list > Rpm@lists.bufferbloat.net > https://lists.bufferbloat.net/listinfo/rpm ^ permalink raw reply [flat|nested] 14+ messages in thread
* Re: [Starlink] [Rpm] On FiWi 2023-03-17 19:19 ` rjmcmahon @ 2023-03-17 20:37 ` Bruce Perens 2023-03-17 20:57 ` rjmcmahon 0 siblings, 1 reply; 14+ messages in thread From: Bruce Perens @ 2023-03-17 20:37 UTC (permalink / raw) To: rjmcmahon; +Cc: Sebastian Moeller, libreqos, Dave Taht via Starlink, Rpm, bloat [-- Attachment #1: Type: text/plain, Size: 696 bytes --] On Fri, Mar 17, 2023 at 12:19 PM rjmcmahon via Starlink < starlink@lists.bufferbloat.net> wrote:You’ll hardly ever have to deal with the annoying > “chirping” that occurs when a battery-powered smoke detector begins to > go dead, and your entire family will be alerted in the event that a fire > does occur since hardwire smoke detectors can be interconnected. > Off-topic, but the sensors in these hardwired units expire after 10 years, and they start beeping. The batteries in modern battery-powered units with wireless links expire after 10 years, along with the rest of the unit, and they start beeping. There are exceptions, the first-generation Nest was pretty bad. [-- Attachment #2: Type: text/html, Size: 1041 bytes --] ^ permalink raw reply [flat|nested] 14+ messages in thread
* Re: [Starlink] [Rpm] On FiWi 2023-03-17 20:37 ` Bruce Perens @ 2023-03-17 20:57 ` rjmcmahon 2023-03-17 22:50 ` Bruce Perens 0 siblings, 1 reply; 14+ messages in thread From: rjmcmahon @ 2023-03-17 20:57 UTC (permalink / raw) To: Bruce Perens Cc: Sebastian Moeller, libreqos, Dave Taht via Starlink, Rpm, bloat I'm curious as to why the detectors have to be replaced every 10 years. Regardless, modern sensors could give a thermal map of the entire complex 24x7x365. Fire officials would have a better set of eyes when they showed up as the sensor system & network could provide thermals as a time series. Also, another "killer app" for Boston is digital image correlation & the cameras monitor stresses and strains on historic buildings valued at about $10M each. And that's undervalued because they're really irreplaceable. Similar for some in the Netherladns. Monitoring the groundwater with samples every 4 mos is ok - better to monitor the structure itself 24x7x365. https://www.sciencedirect.com/topics/engineering/digital-image-correlation https://www.bostongroundwater.org/ Bob On 2023-03-17 13:37, Bruce Perens wrote: > On Fri, Mar 17, 2023 at 12:19 PM rjmcmahon via Starlink > <starlink@lists.bufferbloat.net> wrote:You’ll hardly ever have to > deal with the annoying > >> “chirping” that occurs when a battery-powered smoke detector >> begins to >> go dead, and your entire family will be alerted in the event that a >> fire >> does occur since hardwire smoke detectors can be interconnected. > > Off-topic, but the sensors in these hardwired units expire after 10 > years, and they start beeping. The batteries in modern battery-powered > units with wireless links expire after 10 years, along with the rest > of the unit, and they start beeping. > > There are exceptions, the first-generation Nest was pretty bad. ^ permalink raw reply [flat|nested] 14+ messages in thread
* Re: [Starlink] [Rpm] On FiWi 2023-03-17 20:57 ` rjmcmahon @ 2023-03-17 22:50 ` Bruce Perens 2023-03-18 18:18 ` rjmcmahon 0 siblings, 1 reply; 14+ messages in thread From: Bruce Perens @ 2023-03-17 22:50 UTC (permalink / raw) To: rjmcmahon; +Cc: Sebastian Moeller, libreqos, Dave Taht via Starlink, Rpm, bloat [-- Attachment #1: Type: text/plain, Size: 786 bytes --] On Fri, Mar 17, 2023 at 1:57 PM rjmcmahon <rjmcmahon@rjmcmahon.com> wrote: > I'm curious as to why the detectors have to be replaced every 10 years. Dust, grease from cooking oil vapors, insects, mold, etc. accumulate, and it's so expensive to clean those little sensors, and there is so much liability associated with them, that it's cheaper to replace the head every 10 years. Electrolytic capacitors have a limited lifetime and that is also a good reason to replace the device. The basic sensor architecture is photoelectric, the older ones used an americium pelllet that detected gas ionization which was changed by the presence of smoke. The half-life on the americium ones is at least 400 years (there is more than one isotope, that's the shortest-life one). [-- Attachment #2: Type: text/html, Size: 1143 bytes --] ^ permalink raw reply [flat|nested] 14+ messages in thread
* Re: [Starlink] [Rpm] On FiWi 2023-03-17 22:50 ` Bruce Perens @ 2023-03-18 18:18 ` rjmcmahon 0 siblings, 0 replies; 14+ messages in thread From: rjmcmahon @ 2023-03-18 18:18 UTC (permalink / raw) To: Bruce Perens Cc: Sebastian Moeller, libreqos, Dave Taht via Starlink, Rpm, bloat >> I'm curious as to why the detectors have to be replaced every 10 >> years. > > Dust, grease from cooking oil vapors, insects, mold, etc. accumulate, > and it's so expensive to clean those little sensors, and there is so > much liability associated with them, that it's cheaper to replace the > head every 10 years. Electrolytic capacitors have a limited lifetime > and that is also a good reason to replace the device. > > The basic sensor architecture is photoelectric, the older ones used an > americium pelllet that detected gas ionization which was changed by > the presence of smoke. The half-life on the americium ones is at least > 400 years (there is more than one isotope, that's the shortest-life > one). Thanks for this. That makes sense. I do think the FiWi transceivers & sensors need to be pluggable & detect failures, particularly early on due to infant mortality. "Infant mortality is a special equipment failure mode that shows the probability of failure being highest when the equipment is first started, but reduces as time goes on. Eventually, the probability of failure levels off after time." https://www.upkeep.com/blog/infant-mortality-equipment-failure#:~:text=Infant%20mortality%20is%20a%20special,failure%20levels%20off%20after%20time. Also curious about thermal imaging inside a building - what sensor tech to use and at what cost? The Bronx fire occurred because poor people in public housing don't have access to electric heat pumps & used a space heater instead. It's very sad we as a society do this, i.e. make sure rich people can drive Teslas with heat pumps but only provide the worst type of heating to children from families that aren't so fortunate. https://www.cnn.com/2022/01/10/us/nyc-bronx-apartment-fire-monday/index.html "A malfunctioning electric space heater in a bedroom was the source of an apartment building fire Sunday in the Bronx that killed 17 people, including 8 children, making it one of the worst fires in the city’s history, New York Mayor Eric Adams said Monday." Bob ^ permalink raw reply [flat|nested] 14+ messages in thread
end of thread, other threads:[~2023-03-18 18:18 UTC | newest]
Thread overview: 14+ messages (download: mbox.gz / follow: Atom feed)
-- links below jump to the message on this page --
2023-03-17 16:54 [Starlink] [Rpm] On FiWi David Fernández
2023-03-17 17:05 ` [Starlink] GPON vs Active Fiber Ethernet Dave Taht
2023-03-17 20:36 ` Sebastian Moeller
2023-03-17 23:48 ` [Starlink] [LibreQoS] " dan
[not found] <mailman.2651.1672779463.1281.starlink@lists.bufferbloat.net>
2023-01-03 22:58 ` [Starlink] Researchers Seeking Probe Volunteers in USA David P. Reed
2023-01-09 14:44 ` Livingood, Jason
2023-01-09 15:26 ` Dave Taht
2023-01-09 18:54 ` [Starlink] [EXTERNAL] " Livingood, Jason
2023-01-09 19:19 ` [Starlink] [Rpm] " rjmcmahon
2023-01-09 19:56 ` [Starlink] [LibreQoS] " dan
2023-03-13 10:02 ` [Starlink] [Rpm] [LibreQoS] " Sebastian Moeller
2023-03-13 15:08 ` Jeremy Austin
2023-03-13 15:50 ` Sebastian Moeller
2023-03-13 16:12 ` dan
2023-03-13 16:36 ` Sebastian Moeller
2023-03-13 17:26 ` dan
2023-03-13 18:14 ` Sebastian Moeller
2023-03-13 18:42 ` rjmcmahon
2023-03-13 18:51 ` Sebastian Moeller
2023-03-13 19:32 ` rjmcmahon
2023-03-13 20:00 ` Sebastian Moeller
2023-03-13 20:28 ` rjmcmahon
2023-03-14 4:27 ` [Starlink] On FiWi rjmcmahon
2023-03-14 11:10 ` Mike Puchol
2023-03-14 16:54 ` [Starlink] [Rpm] " Robert McMahon
2023-03-14 17:06 ` Robert McMahon
2023-03-17 16:38 ` Dave Taht
2023-03-17 18:21 ` Mike Puchol
2023-03-17 19:01 ` Sebastian Moeller
2023-03-17 19:19 ` rjmcmahon
2023-03-17 20:37 ` Bruce Perens
2023-03-17 20:57 ` rjmcmahon
2023-03-17 22:50 ` Bruce Perens
2023-03-18 18:18 ` rjmcmahon
This is a public inbox, see mirroring instructions for how to clone and mirror all data and code used for this inbox
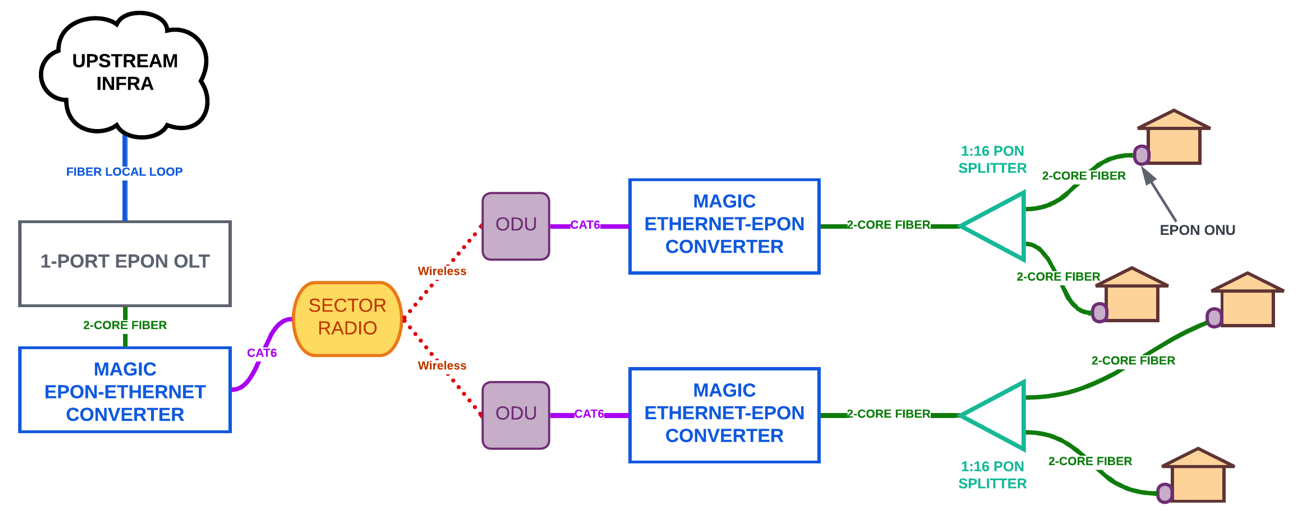{kind=link}